(1)标准 I/O
基本I/O:即不带缓冲区的I/O, 如 类Unix系统中常用的I/O函数有 :read()和write()等。
标准I/O:在基本的I/O函数基础上增加了流和缓冲区的概念。
-
常用的函数有 :
fopen(),getc(),putc()等 -
为了提高读写效率和保护磁盘, 使用了页缓存机制(
Page Cache)
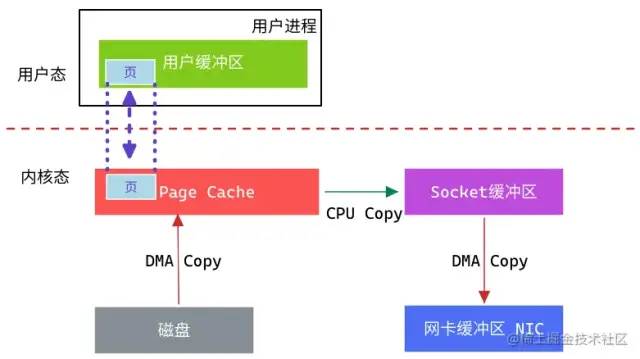
模拟场景:从文件中读取数据,然后将数据传输到网上
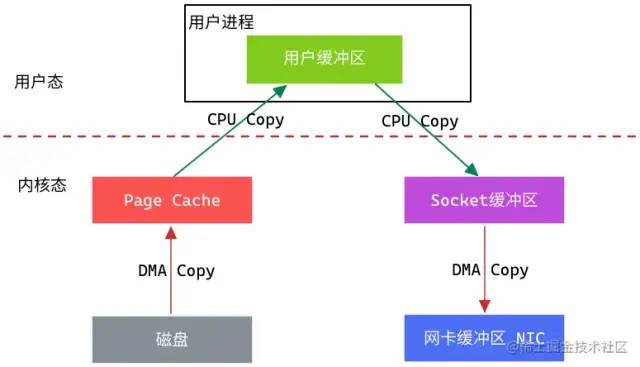
从上图中可以看出,从数据读取到发送一共经历了四次数据拷贝,具体流程如下:
-
第一次数据拷贝:当用户进程发起
read()调用后,上下文从用户态切换至内核态。DMA引擎从文件中读取数据,并存储到Page Cache(内核态缓冲区)。 -
第二次数据拷贝:请求的数据从内核态缓冲区拷贝到用户态缓冲区,然后返回给用户进程。同时会导致上下文从内核态再次切换到用户态。
-
第三次数据拷贝:用户进程调用
send()方法期望将数据发送到网络中,此时用户态会再次切换到内核态,请求的数据从用户态缓冲区被拷贝到Socket缓冲区。 -
第四次数据拷贝:
send()系统调用结束返回给用户进程,再次发生上下文切换。此次操作会异步执行,从Socket缓冲区拷贝到协议引擎中。
问题:为什么需要 Page Cache?
回答:充当缓存的作用,这样就可以实现文件数据的预读,提升 I/O 的性能。可以理解为:批量数据刷盘。
(2)零拷贝
那能不能减少数据拷贝的次数?能,使用零拷贝。
在 Linux 中系统调用 sendfile() 可以实现将数据从一个文件描述符传输到另一个文件描述符,从而实现了零拷贝技术。
在Java中也可以使用了零拷贝技术,主要是NIO FileChannel类中:
-
transferTo()方法:可以将数据从FileChannel直接传输到另外一个Channel。 -
transferFrom()方法:将数据从Channel传输到FileChannel。
模拟场景:从文件中读取数据,然后将数据传输到网上
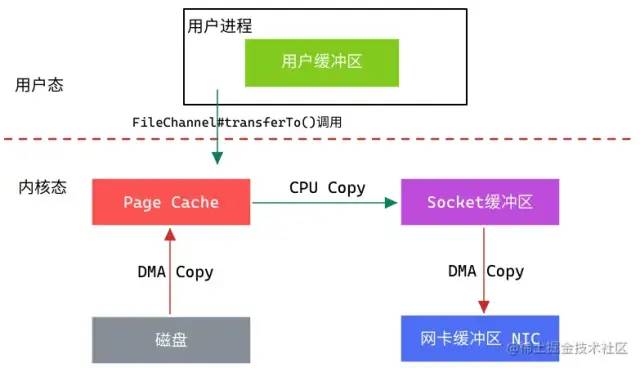
从上图中可以看出,从数据读取到发送一共经历了三次数据拷贝,减少了一次,具体流程如下:
-
用户进程调用
FileChannel#transferTo(),上下文从用户态切换至内核态。 -
第一次数据拷贝:
DMA从文件中读取数据,并存储到Page Cache。 -
第二次数据拷贝:
CPU将Page Cache中的数据拷贝到Socket缓冲区。 -
第三次数据拷贝:
DMA将Socket缓冲区数据拷贝到网卡进行数据传输
案例:Kafka 写入日志
实际开发中,我们能发现 Kafka 写入数据时也用到零拷贝技术。
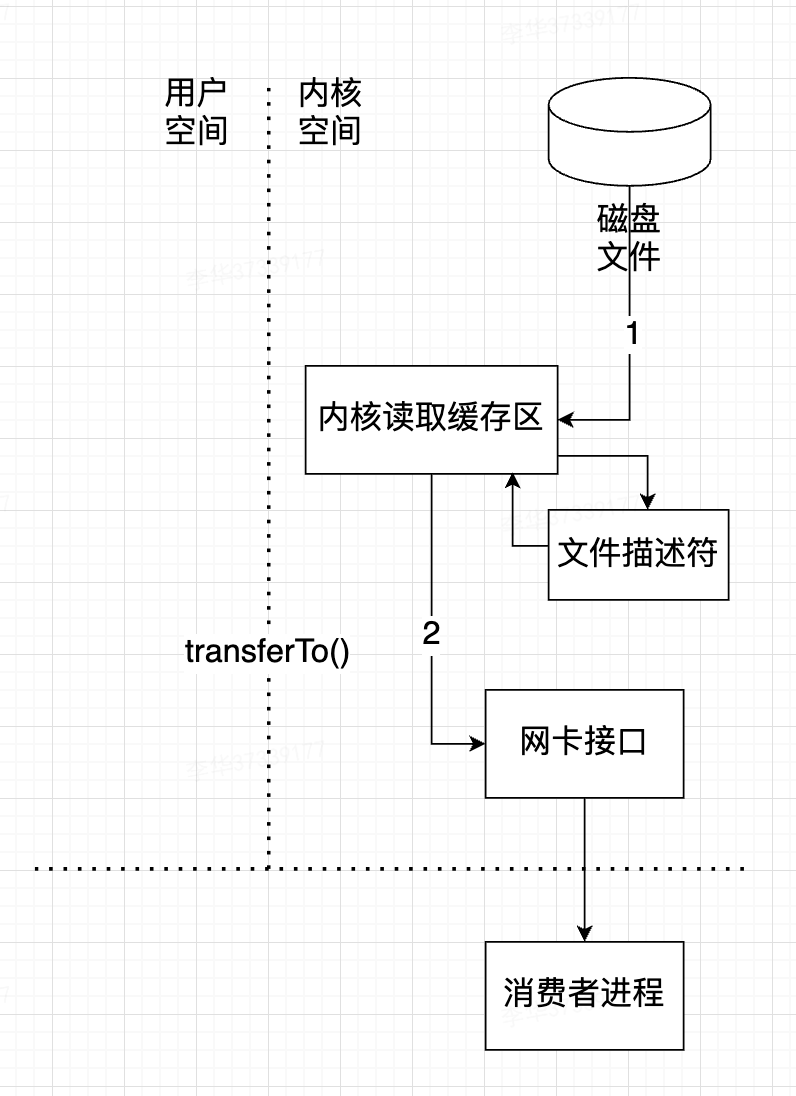
kafka的零拷贝技术体现在服务端发送给客户端(消费者)某一个消息文件,使用的就是零拷贝
在Kafka源码中MemoryRecords的writeTo方法中可发现:
-
调用了
FileChannel的transferTo()方法
public class FileRecords extends AbstractRecords implements Closeable { @Override public long writeTo(GatheringByteChannel destChannel, long offset, int length) throws IOException { long newSize = Math.min(channel.size(), end) - start; int oldSize = sizeInBytes(); if (newSize < oldSize) throw new KafkaException(String.format( "Size of FileRecords %s has been truncated during " + " write: old size %d, new size %d ", file.getAbsolutePath(), oldSize, newSize)); long position = start + offset; int count = Math.min(length, oldSize); final long bytesTransferred; if (destChannel instanceof TransportLayer) { TransportLayer tl = (TransportLayer) destChannel; bytesTransferred = tl.transferFrom(channel, position, count); } else { // 重点: bytesTransferred = channel.transferTo(position, count, destChannel); } return bytesTransferred; } }
更进一步:只需二次数据拷贝
能否继续减少内核中的数据拷贝次数呢?
在Linux 2.4版本之后,对Socket缓冲区 追加一些Descriptor(文件描述符)信息来进一步减少内核数据的复制。
Tips:这种方式的前提是硬件和相关驱动程序支持DMA Gather Copy。
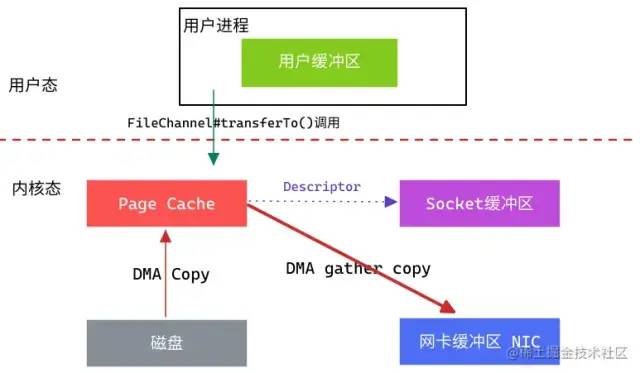
DMA读取文件内容并拷贝到Page Cache,然后并没有再拷贝到Socket缓冲区,只是将数据的长度以及位置信息被追加到Socket缓冲区,然后DMA根据这些描述信息,直接从内核缓冲区读取数据并传输到协议引擎中,从而消除一次CPU拷贝。
(3)MMAP
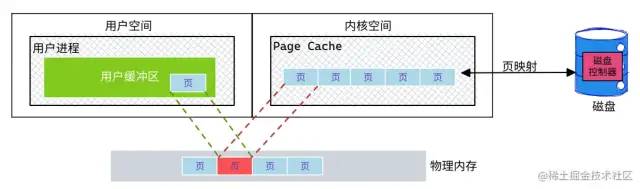
MMAP:是一种内存映射文件的方法, 可以将一个文件或者其他对象映射到进程的虚拟地址空间
-
实现文件磁盘地址 和 进程虚拟地址空间中某一段地址的一一对应。
-
这样应用程序就可以通过访问进程虚拟内存地址直接访问文件。
好处在于:
-
用户进程把文件数据当作内存, 所以无需发布
read()或write()系统调用。 -
当用户进程碰触到映射内存空间, 页错误会自动产生, 从而将文件数据从磁盘读进内存。如果用户修改了映射内存空间, 相关页会自动标记为脏, 随后刷新到磁盘, 文件得到更新。
-
操作系统的虚拟内存子系统会对页进行智能高速缓存, 自动根据系统负载进行内存管理。
-
数据总是按页对齐的, 无需执行缓冲区拷贝。
-
大型文件使用映射, 无需耗费大量内存, 即可进行数据拷贝。
MMAP操作文件:
-
MMAP为用户进程创建新的虚拟内存区域 -
建立文件磁盘地址 和 虚拟内存相关区域的映射 (这期间没有涉及任何的文件拷贝)
-
当用户进程访问数据时, 若无数据则发起缺页异常处理, 根据已经建立好的映射关系进行一次数据拷贝, 将磁盘中的文件数据读取到虚拟地址对应的内存中。
从内存视角再来看 MMAP:虚拟地址 与 物理内存
案例:RocketMQ写入日志
MMAP技术在进行文件映射的时候,一般有大小限制,在 1.5GB ~ 2GB之间。
RocketMQ才让CommitLog单个文件在1GB,ConsumeQueue文件在5.72MB,不会太大。
RocketMQ的消息写入支持内存映射与FileChannel两种写入方式:根据tranisentStorePoolEnable参数判断
-
false:先将消息写入到页缓存,然后根据刷盘机制持久化到磁盘。 -
true:数据会先写入到堆外内存,然后批量提交到FileChannel,并最终根据刷盘策略将数据持久化到磁盘。
(4)堆外内存
如果在 JVM 内部执行 I/O 操作时,必须将数据拷贝到堆外内存,才能执行系统调用。
问题:为什么操作系统不能直接使用 JVM 堆内存进行 I/O 的读写呢?
原因有二:
1. 操作系统并不感知JVM的堆内存,而且JVM的内存布局与操作系统所分配的是不一样的,操作系统并不会按照JVM的行为来读写数据。
2. 同一个对象的内存地址随着JVM GC的执行可能会随时发生变化,例如JVM GC的过程中会通过压缩来减少内存碎片,这就涉及对象移动的问题了。
平时开发时,会使用NIO的DirectBuffer来创建堆外内存:
-
普通的
Buffer分配的是JVM堆内存。 -
堆外内存
DirectBuffer创建和销毁的代价相对较高,一般都会采用复用方式。 -
DirectBuffer申请的内存并不是直接由JVM负责垃圾回收,但在DirectBuffer包装类被回收时,会通过Java Reference机制来释放该内存块。
案例:Netty
Netty在进行I/O操作时都是使用的堆外内存,可以避免数据从JVM堆内存到堆外内存的拷贝。
总结
小结下:
| 拷贝方式 | CPU 拷贝 | DMA 拷贝 | 系统调用 | 上下文切换次数 |
|---|---|---|---|---|
| 标准 I/O | 2 | 2 | read/write | 4 |
内存映射(MMAP) |
1 | 2 | mmap/write | 4 |
零拷贝(sendfile) |
1 | 2 | sendfile | 2 |
零拷贝(sendfile DMA gather copy) |
0 | 2 | sendfile | 2 |