一:Mapreduce编程模型
1.介绍
解决海量数据的计算问题。
》map:映射
处理不同机器上的块的数据,一个map处理一个块。
》reduce:汇总
将map的结果进行汇总合并
2.一个简单的MR程序
map
reduce
input
output
3.在处理中,格式的流向
《key,value》
4.需要思考的问题
处理的数据是什么样的
map的输出格式
reduce的输出数据格式
二:完成Wordcount的程序
1.数据的输入格式说明(默认方式)
Hadoop Yarn
》key:代表偏移量
》value:这一行的值
》<0,Hadoop Yarn>
2.map处理的数据格式
Hadoop Yarn
Hadoop Spark
分割单词
每出现一次就这样处理一下
<Hadoop,1> <Yarn,1>
<Hadoop,1> <Spark,1>
3.reduce处理的数据格式
将相同key的value值加在一起就是单词出现的次数
4.新建包以及类

5.将程序分成三块的框架
Mapper类,Reducer类,Driver的run方法
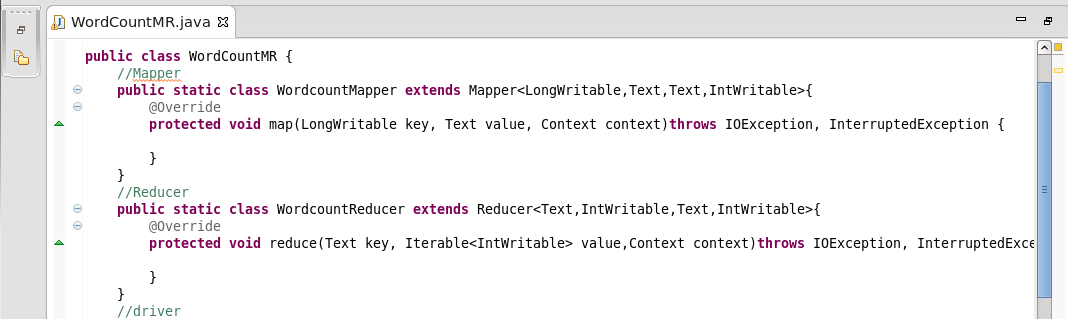
3.将map与reduce相结合,并在main中运行
分为四大部分:input,output,mapper,reducer
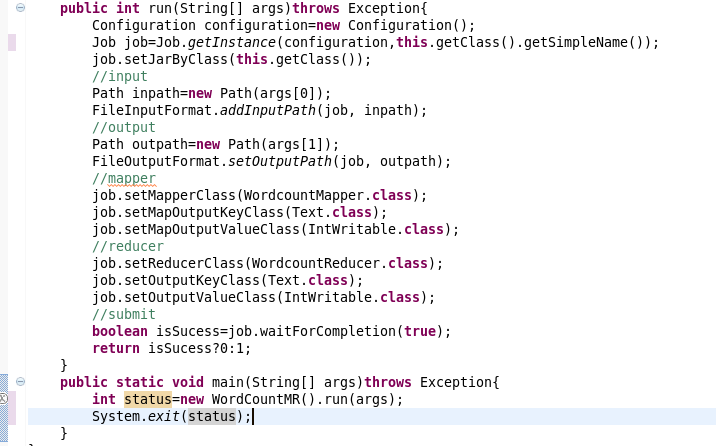
4.Mapper类
将value转化为字符串
使用空格分隔
使用context输出键值对。
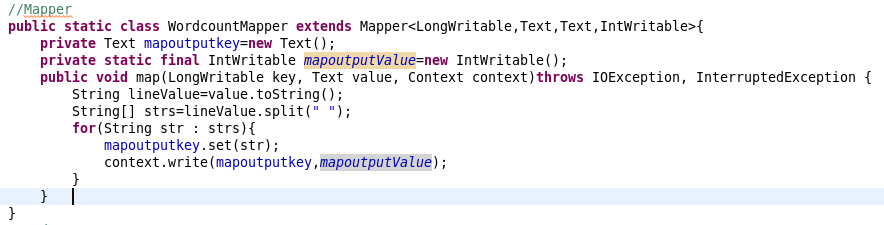
5.Reducer类

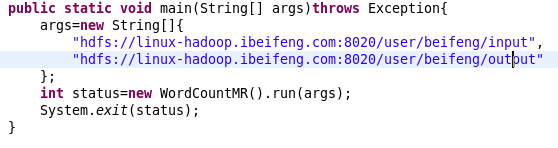
6.在main()中写入文件操作系统的路径。
7.结果
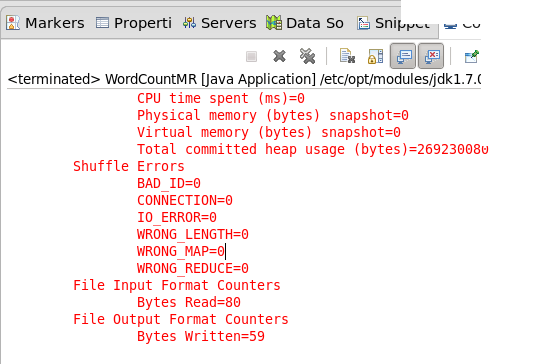
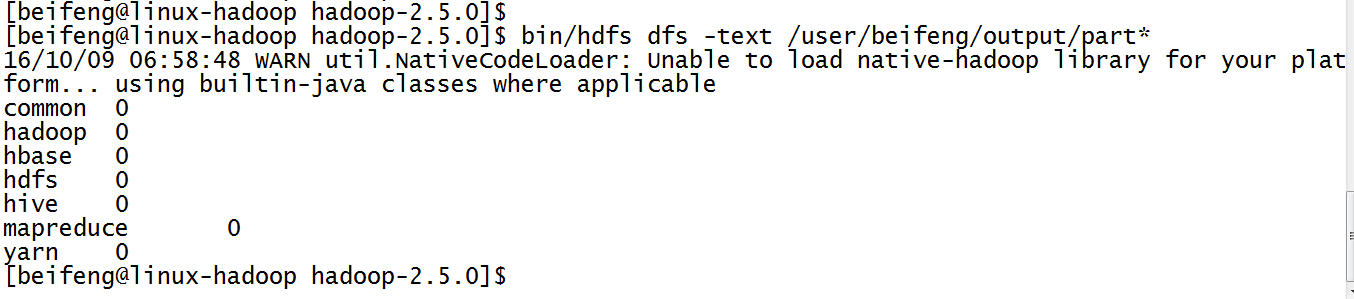
8.出现的结果有些问题,因为没有计数。

IntWritable(1),其参数为1.表示每出现一次就记录一次。
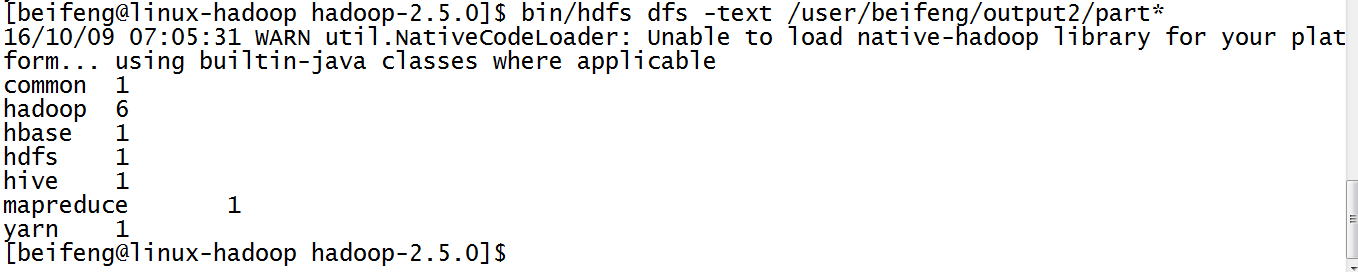
9.最新的结果
三:打包在yarn上运行
10.因为需要把jar分发到节点上,所以需要修改

11.打jar包
12.选择jar包的路径

13.选择jar运行的主类
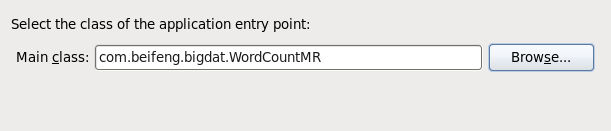
14.运行jar在yarn上
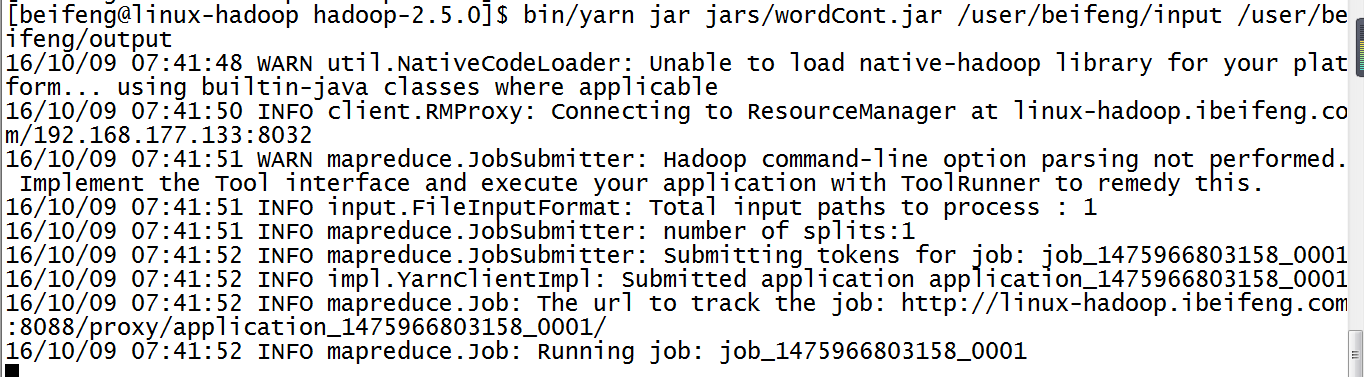
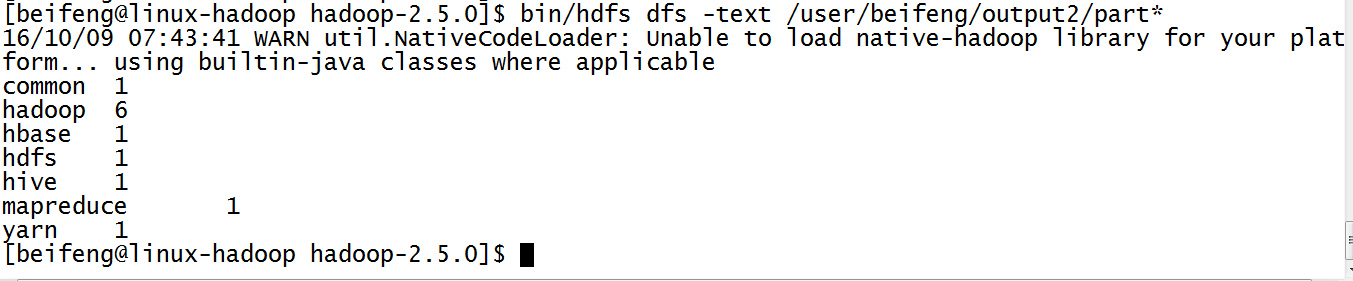
15.运行结果
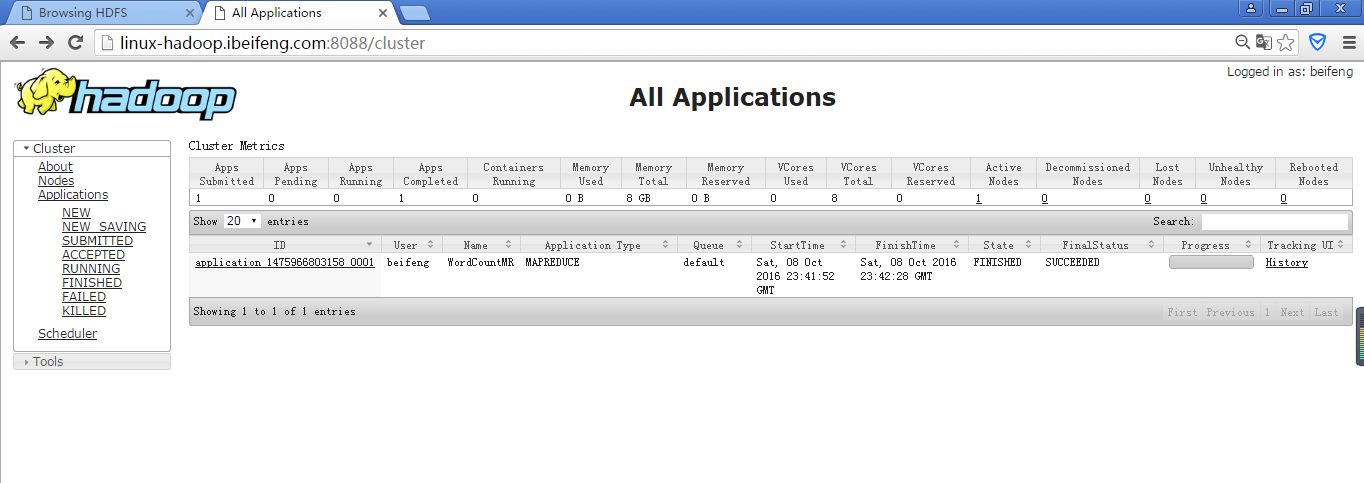
16.在yarn的管理界面上看
17.在Configuration中search一下mapper
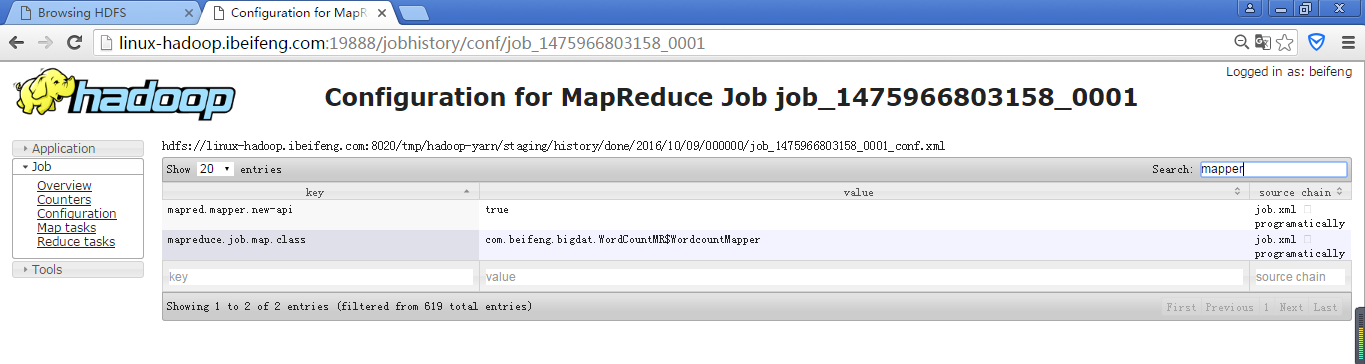
同样可以reduce,或者fileoutput等查阅一些参数。