 |
 |
 一、背景
一、背景1.1概念定义
我们这里想要实现的图像拼接,既不是如题图1和2这样的“图片艺术拼接”,也不是如图3这样的“显示拼接”,而是实现类似“BaiDU全景”这样的全部的或者部分的实际场景的重新回放。
对于图像拼接的流程有很多定义方式,本教程中主要介绍实现主流方法,总结梳理如下:
图像采集->投影变换->特征点匹配->拼接对准->融合->反投影
图像采集不仅仅指的是普通的图像数据的获取。为了能够拼接过程能够顺利进行、拼接结果能够满足要求,我们在采集图像的时候就使用了一些方法、固化了一些参数;
投影变换为了采集的图像能够方便拼接,我们需要将各个图片变换到统一的平面上去。而变换的依据就是在图像采集的设定下来的采集方法。
特征点匹配是先进的特征寻找方法,一般是SHIFT/SURF/ORB,简单介绍模板匹配。所谓“特征点”,就是这样同样的一个点,在不同的图片上面都会显示为同样的特征。那么如果掌握了足够的可信度高的特征点,就可以将图片中各个物体变换到同意的平面上去。RANSAC特征点提纯也是较为重要的内容。
拼接对准是图像拼接的核心部分,就是根据前面寻找到的匹配关系,将投影变换后的图片再次变换并合并成一张图片。需要注意的是,当大量图片拼接的时候,会出现错误累积的情况,我们采用“光束平差法”应对;同时还有插值计算的相关内容。
图像融合是用来消除由于几何校正、动态的场景或光照变化引起的相邻图像间的强度或颜色不连续问题,也就是缝隙消除。我们介绍一种复杂的方法和一种直接的方法,用于不同的情况。
反投影没有名字听起来那么玄乎,实际上就是将拼接的结果重新生成的过程。一般还是生成图片,但是也可以变成其它的类型。
1.2国内外研究现状
关于图像拼接的方法国内外已有不少的论文发表,其算法大致可分为基于模型的方法、基于变换域的方法、基于灰度相关的方法和基于特征的方法,而如何提高图像拼接的效率,减少处理时间和增强拼接系统的适应性一直是研究的重点。
(历史有兴趣可以看,不影响主要内容学习)1996年,微软研究院的瓦chadrSezhski提出了一种ZD空间八参数投影变换模型,采用Lvenebegr一Marquadrt迭代非线性最小化方法(简称L一M算法)求出图像间的几何变换参数来进行图像配准。这种方法在处理具有平移、旋转、仿射等多种变换的待拼接图像方面效果好,收敛速度快,因此成为图像拼接领域的经典算法。
2000年,shmuelPeleg等人在瓦chardszeliski的基础上作了进一步的改进,提出了自适应图像拼接模型,根据相机的不同运动而自适应选择拼接模型,通过把图像分成狭条进行多重投影来完成图像的拼接。这一研究成果推动了图像拼接技术的进一步的发展,从此自适应问题成为图像拼接领域新的研究热点。匹兹堡大学的SevketGumustekin对消除在固定点旋转摄像机拍摄自然景物时形成的透视变形和全景图像的拼接进行了研究。通过标定摄像机来建立成像模型,根据成像模型将捕获到的图像投影到统一的高斯球面上,从而得到拼接图像。这种方法拼接效果好、可靠性高,但是要求对摄像机进行精确的标定,同时要求摄像机透镜本身的畸变参数引起的图像变形可以忽略不计。
1975年,Kuglni和Hines提出了相位相关法,利用傅立叶变换将两幅待配准的图像变换到频域,然后利用互功率谱直接计算出两幅图像间的平移矢量。1987年,DeCasrt断口Mornadi提出了扩展相位相关法,利用傅立叶变换的性质能够实现具有旋转和平移变换的图像的配准。随着快速傅立叶变换算法的提出以及信号处理领域对傅立叶变换的成熟应用,Rdedy和chatterji提出了基于快速傅立叶变换F(FT一basde)的方法,利用极坐标变换和互功率谱,对具有平移、旋转和缩放变换的图像都能够实现精确配准。相位相关法计算简单精确,但要求待配准图像之间有较大重叠比例,同时计算量和适用范围与图像的大小有很大关系。除了傅立叶变换外,人们还选择更可靠、更符合人眼视觉生理特征的Gbaor变换和小波变换进行图像匹配。基于灰度相关的方法是以两幅图像重叠部分所对应在RGB或CMY颜色系统中灰度级的相似性为准则寻找图像的配准位置。常用的算法有比值匹配法、块匹配法和网格匹配法。比值匹配法是从一幅图像的重叠区域中部分相邻的两列上取出部分像素,然后以它们的比值作为模板,在另一幅图像中搜索最佳匹配,这种算法计算量较小,但精度低;块匹配法是以一幅图像重叠区域中的一块作为模板,在另一幅图像中搜索与此模板最相似的匹配块,这种算法精度较高,但计算量过大;网格匹配法嗜先进行粗匹配,每次水平或垂直移动一个步长,记录最佳匹配位置,然后再进行精确匹配,每次步长减半,循环此过程直至步长减为O,这种算法较前两种运算量有所减小,但如果粗匹配步长过大会造成较大的误差。基于特征的方法首先从待匹配图像中提取特征集,利用特征的对应关系进行匹配。基于特征的方法利用了图像的显著特征,具有计算量小,速度快的特点,对与图像的畸变、噪声、遮挡等具有一定的鲁棒性,但是它的匹配性能在很大程度上取决于特征提取的质量。提出了一种轮廓的图像匹配方法,采用LOG算子提取出两幅图像的特征轮廓,用链码来表示轮廓,根据相同轮廓的链码差分值不变的特性找出对应轮廓,从而确定图像间的变换关系。这种方法在特征轮廓的提取上容易受到噪声的干扰,其计算量随着轮廓数量的增多而增长。使用HarriS检测器提取兴趣点,通过计算归一化相关系数,沿极线寻找一幅图像中兴趣点的对应点,然后使用第三幅图像来得到更准确的对应;Jnae提出了基于小波变换的分层图像匹配算法,在分解后的每一层图像中提取兴趣点进行匹配,用并行策略提高了计算速度。
图像匹配算法经过几十年的发展已经取得了很大的进展,但由于拍摄环境复杂多变,现在还没有一种算法能够解决所有图像的匹配问题。现有的几种方法各有其优缺点,如果能综合利用这些方法的优点将会取得更好的匹配结果。
(应该整理出最新的知识 以及经典的综述)
(这里要注意学习)软件方面,以微软研究院“Image Composite Editor”(下称ICE)效果最好,我判断ICE的作者很可能就是图像拼接相关论文的作者,或者至少是在其指导下完成的。ICE基本是将论文中的特性全部都体现出来了。

正是因为ICE的优良特性(和不开源性),我一般将其作为图像拼接的“验证工具”来使用。
1.3图像拼接技术的广泛运用
 |
1)消费类VR
虚拟现实技术(Virtual Reality)就是利用计算机构建一个逼真的虚拟环境,即以仿真的方式给人们创造一个反映实体对象变化及其相互作用的三维世界,使得人们能够通过使用专用设备,就能像在自然环境中一样对虚拟环境中的实体进行观察与控制。
(TIP 注意,这里就是“反投影”的一个灵活使用。拼接的结果最后不是以单幅图片显示出来的,而是处理以后,通过VR双屏幕显示出来的。所谓“反”指的就是逆过程)
2)遥感技术
随着航空航天技术的发展,侦察卫星或航空遥感器能够实时获得目标的高清晰图像。为了扩大视野,提高分辨率,获得质量更高、位置更精确的信息,需要将来自不同传感器的两幅或多幅遥感图像拼接成一幅影像图。下图所示,是由多幅遥感图像拼接成的月球表面拼接图像。

3)医学方面
在医学领域,从CT图像、X光照片到人体的细胞照片,医学对图像的质量和处理手段都有极高的要求,许多图像处理技术也是在解决医学图像问题的过程中产生的。全景图由于其宽视角的特点也被应用在医学领域。在远程会诊中,把拍摄的序列病理图片拼接成全景图,不仅可以使远程终端用户能够看到当地医院的完整“现场”,还能在当地医院再现观测病理切片时的“现场”,这对于病理切片存档、病理研究学习等都有着重要的意义。
在超声检查中,超声图像的质量直接影响着医生对病情的诊断,由于普通超声探头较小,对大的组织器官和病变难以在一个断面显示,利用图像拼接技术可以将探头连续移动时的图像拼接成为宽视角的全景图,就可以显示出组织的完整结构,为诊断提供更好的依据。
在外科手术中,由于缺少对视网膜整体状况进行检查的工具,视网膜激光手术的成功率很低。Alican Charles等人提出了利用图像拼接的方法构建视网膜的整体视图,作为外科手术的依据。他们将视网膜近似为一个二维的曲面,以视网膜上血管的三叉点作为匹配的特征点,通过求解一个12参数的变换矩阵找到相邻两幅视网膜图像之间的变换关系,将一系列视网膜的图像拼合成一张大的视网膜图像,如图所示。视网膜的整体视图为视网膜激光手术的发展做出了巨大的贡献。
图像拼接可以说在很多方面都会有强烈的需求、重要的作用,所以学习学懂图像拼接,对于一名图像方面的学生、工作者或者是研究人员来说都是必须的,值得付出的。
1.4图像拼接技术的特点
图像拼接技术是以多幅图像为处理对象,需要对两幅或两幅以上的图像进行综合的分析,因此相对于图像压缩、图像分割、图像编码等图像处理技术来说,有其自身的特点:多样性、针对性、复杂性和缺乏客观评价约束
1)多样性
在客观世界中的自然物体和人造物体种类繁多、形状各异,使得图像的内容千变万化;由于光照条件的变化和景物中不可避免的物体移动,所以相机从不同角度采集的图像之间以及在不同时间采集的同一物体的图像之间都存在着差异;相机在采集图像的过程中,存在着多种运动方式,如平移、旋转、倾斜等,这也使得到的图像具有不同的特点。以上多方面的原因造成了图像拼接技术的处理对象的复杂性和不可把握性,也决定了图像拼接技术的多样性。因此,对于不同类型的图像,需要不同的处理方法。
2)针对性
不同内容的图像,以及在不同条件下得到的图像,如柱面图像、球面图像和视频图像序列等,它们都具有鲜明的特点。因此,针对这些特点产生了特定的图像拼接算法。一般来说,图像拼接算法的针对性都很强,对于某种条件下产生的图像拼接算法可能完全不适合另外一种情况下的图像拼接算法;
3)复杂性
图像采集和相机模型原理联系紧密;在采集的过程中涉及到多个模型;从图像的采集到最后生成效果良好的拼接结果,中间需要经过多个环节。而这些环节之间又相互关联,前后约束。这就决定了图像拼接算法比较复杂。同时容易出现各种现场问题。
4)缺乏客观评价约束
因为最后生成的是一副图片,那么就缺乏客观、统一的评价标准,衡量一个算法的优劣只能依靠人的主观视觉感知。反过来也会造成提高算法质量的时候缺乏依据。
正是因为图像拼接“复杂且难以评价”,所以在学习的时候需要理清框架、打牢基础、注重方法,并且注重“由易到难”和“编码实践”。
这里收集整理了多方的资料,还是为了让大家对拼接的重要意义有充分认识,对需要克服的困难有初步了解。如果能够理解困难出现的原因,那么对于解决困难肯定是有帮助的。
二、图像拼接技术的基本流程
(原因是什么07)前面已经说过了,我们这里将图像拼接划分为以下流程
图像采集->投影变换->特征点匹配->拼接对准->融合->反投影
2.1图像的采集(摄像头模型)
首先来看例子:
2.1.1精密图像采集体系:
 |
 |
 |
 |
虽然形状各异,充满了GEEK的感觉,但是共同点很明显:围绕中心排列一系列的相机。
这样一次采集就能够获得360度的图像,而且由于相机是固定的,所以采集获得的图像质量很高。
2.1.2正常的图像采集
 |
采集到的照片的质量好坏直接影响到最后的拼接结果和生成的全景图的真实感,因此在拍摄的时候应该尽可能的注意以下这几方面:
① 相机应该大致固定在景物的中心位置,这样能尽量保证拍摄角度恰当。
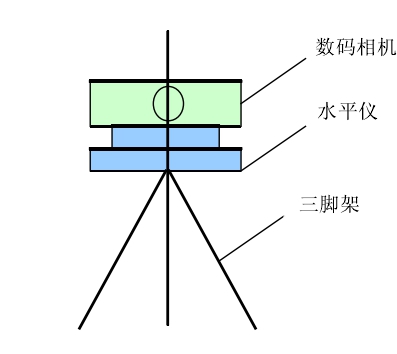
② 将数码相机固定在摄影三角架上,尽可能的避免平转数码相机时镜头的偏斜和俯仰,尽量保持相机水平旋转。
③ 相机尽可能绕光心旋转。偏离光心引入的误差会导致插值图像的重影和定位困难。
④ 拍摄时固定光圈和焦距。不同光圈会使不同方向上的照片有较大的亮度、对比度或色彩差异。
柱面全景空间的视点空间对应单一视点处的柱面范围,要获取该范围内的实景图,只需固定照相机或摄像机的位置,平转照相机或摄像机,每旋转一定的角度,拍摄一张照片。拍摄实景图像使用的器材包括三脚架、水平仪和数码相机等。如图所示。如果没有3脚架,可以以自己作为3脚架,但是效果会差一点。
前面说了在实际使用过程中出现的采集方式,那么下面来说一说模型。
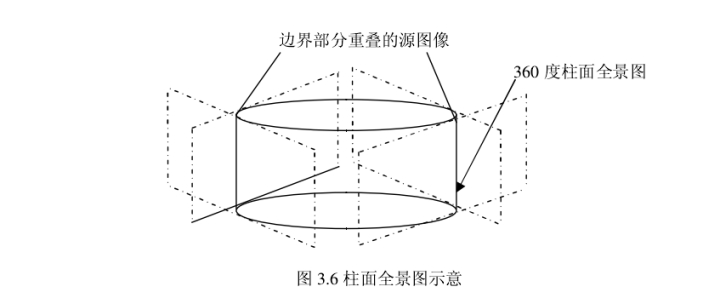
2.1.3 柱面图像采集模型
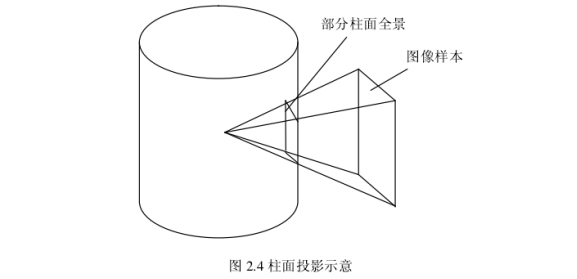 |
用户可以在全景图像中 360 度的范围内任意切换视线,也可以在一个视线上改变视角,来取得接近或远离的效果,也可以认为是球面全景图的一种简化。用户在水平方向上有 360度的视角,在垂直方向上也可以做一定的视角变化,但是角度范围则受到限制。由于柱面模型的图像质量均匀,细节真实程度更高,应用范围比较广泛。
柱面全景图像也较为容易处理,因为可以将圆柱面沿轴向切开并展开在一个平面上,传统的图像处理方法常常可以直接使用。柱面全景图像并不要求照相机的标定十分准确。所以将柱面全景图显著优点归纳为以下两点:
1)它的单幅照片的获取方式比立方体形式和球面形式的获取方式简单。所需的设备只有普通的相机和一个允许连续“转动”的三角架。
2)柱面全景图容易展开为一个矩形图像,可直接用计算机常用的图像格式进行存储和访问。虽然柱面形式的全景图在垂直方向允许参与者视线的转动角度小于 180 度,但是在绝大多数应用中,水平方向的 360 度环视场景已足以表达空间信息。
这里只是让大家对“柱面模型”这种采集方式有一个初步的了解,具体的数据计算在后面解释。
此外,我强调的是:“柱面模型”,本身是一种设计出来的图像采集的模式,采用这种模式就决定了以后图像投影变换的细节,间接地决定了最后拼接结果的质量。
所谓的柱状投影。

可以得到这样的效果,这个效果是否正确还有待商榷,但是基于此的确可以更进一步地做东西了。
// column_transoform.cpp : 桶装投影
//
#include "stdafx.h"
#include <iostream>
#include "opencv2/core/core.hpp"
#include "opencv2/imgproc/imgproc.hpp"
#include "opencv2/features2d/features2d.hpp"
#include "opencv2/highgui/highgui.hpp"
#include "opencv2/nonfree/features2d.hpp"
#include "opencv2/calib3d/calib3d.hpp"
using namespace std;
using namespace cv;
#define PI 3.14159
int main( int argc, char** argv )
{
Mat img_1 = imread( "Univ1.jpg");
Mat img_result = img_1.clone();
for(int i=0;i<img_result.rows;i++)
{ for(int j=0;j<img_result.cols;j++)
{
img_result.at<Vec3b>(i,j)=0;
}
}
int W = img_1.cols;
int H = img_1.rows;
float r = W/(2*tan(PI/6));
float k = 0;
float fx=0;
float fy=0;
for(int i=0;i<img_1.rows;i++)
{ for(int j=0;j<img_1.cols;j++)
{
k = sqrt((float)(r*r+(W/2-j)*(W/2-j)));
fx = r*sin(PI/6)+r*sin(atan((j -W/2 )/r));
fy = H/2 +r*(i-H/2)/k;
int ix = (int)fx;
int iy = (int)fy;
if (ix<W&&ix>=0&&iy<H&&iy>=0)
{
img_result.at<Vec3b>(iy,ix)= img_1.at<Vec3b>(i,j);
}
}
}
imshow( "桶状投影", img_1 );
imshow("img_result",img_result);
waitKey(0);
return 0;
};
2.1.4 难道就没有其他模型了吗
在论文中和实际的项目中,看到最多的就是“柱状模型”,容易让人认为:“全景拼接只适合柱状模型”,甚至以为“图像拼接只适合柱状模型”。
实际上,只要采集的图像中的信息包含了原始全景图片的信息,那么就应该能够有办法将其复原。之所以采用“柱状模型”是因为最容易实现,再说一遍:之所以采用“柱状模型”是因为最容易实现。事实上,针对不同的应用场景,可能会有很多其他的模型:
1) 步进电机控制的精密采集设备;
2) 消费类,手机拍摄形成“蜂窝状”图片拼接;
类似的情况还可能会有许多,但是如果能够理解第二章整个的流程、掌握配套的代码编写,就能够灵活运用于不同的模型上面。后面在代码程序设计的时候,我会将一些其它方面的考虑一起放出来。
光是采集方法就说了好多,再一次说明了图像拼接的复杂。选用什么样的采集方法就决定了以后图像投影变换的细节,间接地决定了最后拼接结果的质量。
2.2投影变换
二维平面运动参数模型是根据建立的数学模型,将待拼接图像转换到参考图像的坐标系中,以此来构成完整的拼接图像。
2.2.1两步成像
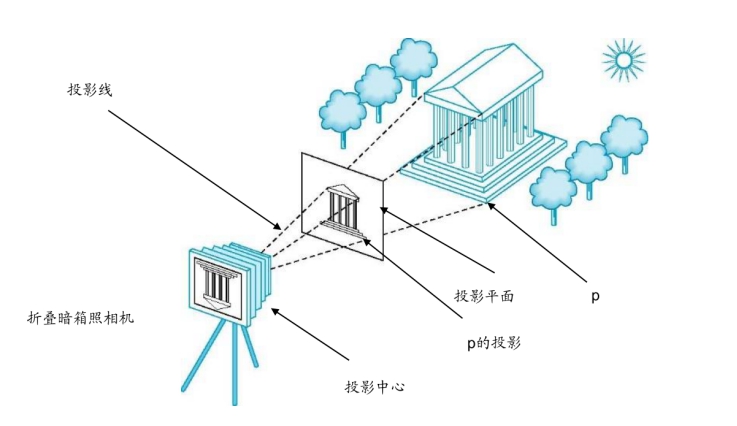
到了这里,就必须涉及相机模型的简单介绍。在我们正常的图像采集中,采用的是“两步成像”方法,将三维物体展现在相机二维的成像面上(比如ccd或者cmos)。
我们在电子图片中,看到的是图像的像
 |
同样可以再举一个图
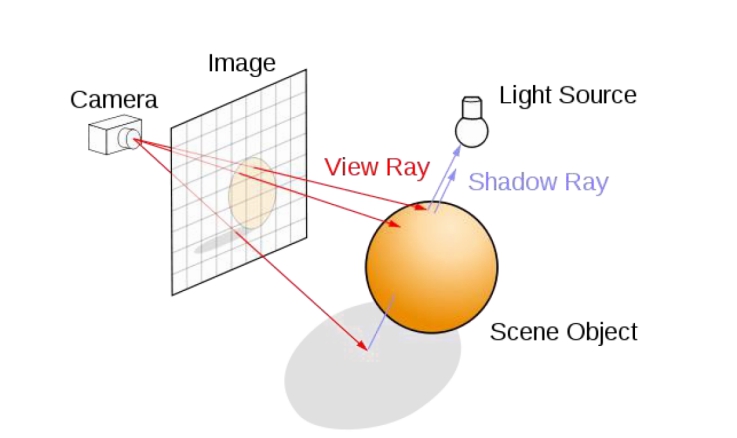 |
2.2.2圆柱面投影算法
(分清楚什么是先验知识)圆柱面投影算法 由于采集的原始图像是在绕视点一周不同角度下拍摄的,它们并不在同一投影平面上,投影存在一定的夹角。如果对图像直接进行拼接,得到的拼合图像在重叠区域会发生局部扭曲现象,并会破坏实际场景的视觉一致性,无法满足实际场景中各对象间的几何关系。比如场景中本来是直线的景物,在拼接后变成了折线,为了保证实际场景在视觉上的一致性,维持实际场景中的空间约束关系。我们必须将拍照得到的反映各自投影平面的各局部图像映射到一个标准投影即柱面投影上,以便获得从投影中心观察图像在柱面上的成像。这样一方面消除了实景图像之间可能存在的重复景物信息,同时也得到了每张实景图像上的像素点在视点空间中的位置信息。
(提示:哪些是虚拟像平面)
展平的过程肯定是一个非线性变换,具体来说就是三角变换。
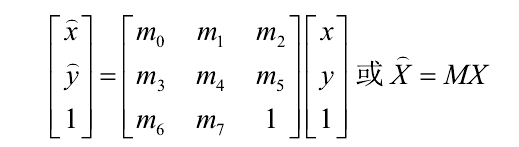 2.2.3 二维坐标体系中的8参数模型。
2.2.3 二维坐标体系中的8参数模型。
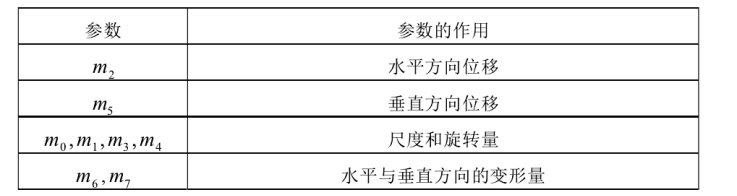
其中,各个参数定义
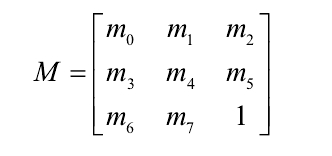 |
 |
2.3 特征匹配
1)什么是特征点?
可以这样简单理解,所谓“特征点”就是能够表明物体本身特征的点。也就是说,这种特征提取的方法具有独特的算法,使得即使你处理在不同的拍摄条件下拍摄同一物体,都能够得到同样的特征值。(所谓“尺度不变性”).
这种特性对于图像拼接来说具有重要意义,因为目前计算机无法识别出图片中的物体,但是如果有一种统一的计算方法,能够告诉计算机不同图片中同一物体的特征点,那么也就是得到了物体的位置和形态了。(可以看图)
 |
2)常用的特征点寻找方法。
SIFT,即尺度不变特征变换(Scale-invariant feature transform,SIFT),是用于图像处理领域的一种描述。这种描述具有尺度不变性,可在图像中检测出关键点,是一种局部特征描述子。该方法于1999年由David Lowe 首先发表于计算机视觉国际会议(International Conference on Computer Vision,ICCV),2004年再次经David Lowe整理完善后发表于International journal of computer vision(IJCV)。截止2014年8月,该论文单篇被引次数达25000余次。
SURF(Speeded Up Robust Features)是一个稳健的图像识别和描述算法,首先于2006年发表在欧洲计算机视觉国际会议 用于计算机视觉任务,如物件识别和3D重构。他部分的灵感来自于SIFT算法。SURF标准的版本比SIFT要快数倍,并且其作者声称在不同图像变换方面比SIFT更加稳健。SURF 基于近似的2D 离散小波变换响应和并且有效地利用了积分图。该算法由Herbert Bay于2006年首次发表于ECCV,2008年正式发表在Computer vision and image understanding期刊上,论文被引9000余次。
ORB,从它的名字中可以看出它是对FAST特征点与BREIF特征描述子的一种结合与改进,这个算法是由Ethan Rublee,Vincent Rabaud,Kurt Konolige以及Gary R.Bradski在2011年一篇名为“ORB:An Efficient Alternative to SIFT or SURF”的文章中提出。就像文章题目所写一样,ORB是除了SIFT与SURF外一个很好的选择,而且它有很高的效率,最重要的一点是它是免费的,SIFT与SURF都是有专利的,你如果在商业软件中使用,需要购买许可。
关于SIFT/SURF/ORB,可以通过发表的论文看出之间的相互关系,特征点提取是一个复杂的话题,网络上有很多资料需要去消化吸收。在我的博客中现有调用SURF进行图像处理的一些实验的例子,可以帮助学习。关于这三者的深入解读的课程已经在筹备。
需要注意一点,即使你不懂特征提取的原理,也是可以利用其进行图像拼接的。当然要解决复杂问题,最好还是要懂原理。在实际的使用过程中,ORB速度很快,并且能够提供足够的特征点,同时相比较其他两者编译起来比较简单(因为SIFT/SURF要联编contrib库),所以本拼接教程采用ORB算法。
特征点有没有失效的时候?怎么办?
 |
首先想到的是采用前后的变换矩阵进行拟合,也就是估计出可能的情况。但是这里是8参数估计,所以只是在一些特殊的情况下效果较好(比如有机械臂控制的平面移动)。或者可以采用模板识别辅助获得变换的具体情况。
关于模板识别,可以参考OpenCV官方Wiki,我的博客中也有相关内容,网络上同时资料比较丰富。
3)特征提纯
采用特征匹配可能会得到很多匹配的结果。对于自然图像来说,效果一般比较好:
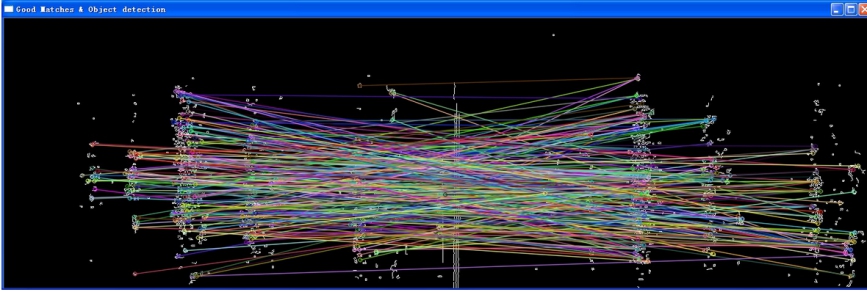 |
 |
就需要有特定的方法提纯这些特征点。主流方法为RANSAC(Random Sample Consensus),它是根据一组包含异常数据的样本数据集,计算出数据的数学模型参数,得到有效样本数据的算法。同样不展开,具体看博客。《RANSAC算法在图像拼接上的应用的实现》,都是带有原理解析和代码的。
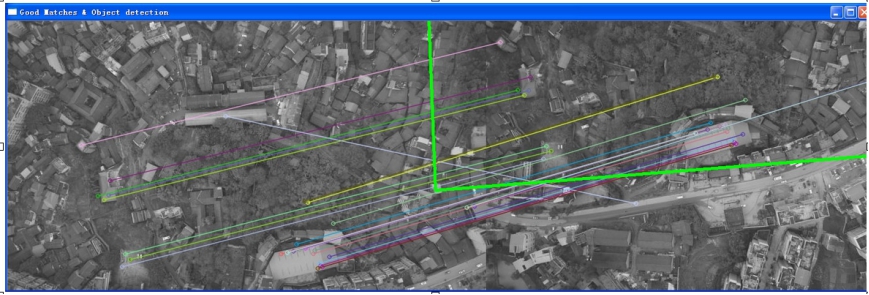
4)特征匹配最后得到一个什么结果,达到什么效果?
即使前面做了那么多工作,最后图像对准的结果还可能是这样:
 |
2.4图像对准
 图像配准是整个图像拼接过程的核心部分,是将不同条件下(气候、照度、摄像位置和角度等)、不同时间或不同传感器获取的同一场景的两幅或多幅图像进行最优匹配的过程。
图像配准是整个图像拼接过程的核心部分,是将不同条件下(气候、照度、摄像位置和角度等)、不同时间或不同传感器获取的同一场景的两幅或多幅图像进行最优匹配的过程。
图像变换后,往往碰到坐标值非整数的情况,为了解决这个问题,图像的插值理论(最近邻插值、双线性插值、三次样条插值) 经常会被运用到拼接算法中。
2.5 图像融合
图像在拍摄过程中可能会存在光照变换,若将配准后图像直接拼接在一起,会出现明显的拼接痕迹,使整个图像看起来光照不够自然,图像融合部分帮助我们解决这一问题。当然但是如果前面做的不好,最后的结果即使要不融合不好;要不融合后的结果和实际不相符。
 |
2.6 反向投影(显示结果)
所谓反向投影这个玄乎的名字,其实想说明的就是将最后拼接的结果显示出来。最直接的就是还是显示成为一个图片(也是我们这个教程要做的),那么复杂一点,可以显示成一个flash;可以显示成一个VR的双目的效果。大家自己发挥,这里抛砖引玉。