被 Pandas read_csv 坑了
-- 不怕前路坎坷,只怕从一开始就走错了方向
Pandas 是python的一个数据分析包,纳入了大量库和一些标准的数据模型,提供了高效地操作大型数据集所需的工具。Pandas 就是为解决数据分析任务生的,无论是数据分析还是机器学习项目数据预处理中, Pandas 无处不在。
最近掉进一坑,差点铸成大错。实在没想到居然栽在pandas.read_csv上了,这里分享一下,希望大家注意。
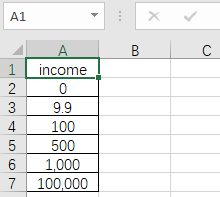
另:业务数据不方便拿出来演示,为尽可能复现,这里我手造了一份,另存为 income.csv 文件。
翻船记
读取csv文件小菜一碟
import numpy as np
import pandas as pd
df = pd.read_csv(r'C:...income.csv',encoding='utf-8')
读好了看看数据信息吧:
df.info()
RangeIndex: 6 entries, 0 to 5
Data columns (total 1 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 income 6 non-null object
dtypes: object(1)
memory usage: 176.0+ bytes
诶,怎么数据成了object?不应该是float吗?
不管他,硬转一发
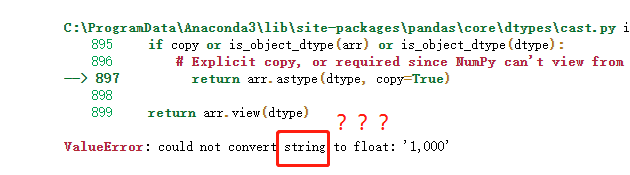
df=pd.DataFrame(df,dtype=np.float)
居然报错了,1000被读成了字符串。
其实这里我还掉进了另一个坑,使用了一个已被弃用的 .convert_objects 方法。这种方法更硬,直接把string转成了NaN,所以后面各种操作流畅且错误地进行着....这都是 pandas 没升级的锅,定期检查升级包太有必要了(pip 的高阶玩法)
说回刚才的问题,1,000被读成了字符串是因为csv文件中它使用了千位分隔符。问题其实非常简单,设置一下 thousands 参数就行了
df2 = pd.read_csv(r'C:...income.csv',encoding='utf-8',thousands =',')
看一下info
df2.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 6 entries, 0 to 5
Data columns (total 1 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 income 6 non-null float64
dtypes: float64(1)
往下继续
df2.describe()
income
count 6.000000
mean 16934.983333
std 40695.203980
min 0.000000
25% 32.425000
50% 300.000000
75% 875.000000
max 100000.000000
一切正常!
pandas.read_csv()参数

pandas.read_csv()的参数特别多,除了filepath,其他均可缺省。参数的具体含义这里就不赘述,还想复习一下的同学可以直接去看官方文档
http://pandas.pydata.org/pandas-docs/stable/io.html
英语不好的同学可以看一下热心博主的翻译版:
https://www.cnblogs.com/datablog/p/6127000.html