最近看了下Nutch,目前Nutch最新版本2.3.1,支持Hbase、MongoDB等存储,但在搭建和测试过程中发现对Mysql 的支持好像有点问题。
后来将Nutch版本改为2.2.1。基于Nutch2.2.1+Mysql 的环境配置过程如下:
1.下载Nutch2.2.1 源码:SVN:https://svn.apache.org/repos/asf/nutch/branches/branch-2.2.1
2.修改Nutch2.2.1 源码中的ivy/ivysetings.xml
- 添加一个源:
<property name="org.restlet"
value="http://maven.restlet.org"
override="false"/>
- 增加以下红色部分代码
<chain name="default" dual="true">
<resolver ref="local"/>
<resolver ref="maven2"/>
<resolver ref="apache-snapshot"/>
<resolver ref="sonatype"/>
<resolver ref="restlet"/>
</chain>
经过测试,没有增加这个有些包下载不了,可能和网络有关系。
3.修改ivy/ivy.xml
启用以下两个依赖
<dependency org="org.apache.gora" name="gora-sql" rev="0.1.1-incubating" conf="*->default" /><span style="color: #0000ff;"><</span><span style="color: #800000;">dependency </span><span style="color: #ff0000;">org</span><span style="color: #0000ff;">="mysql"</span><span style="color: #ff0000;"> name</span><span style="color: #0000ff;">="mysql-connector-java"</span><span style="color: #ff0000;"> rev</span><span style="color: #0000ff;">="5.1.18"</span><span style="color: #ff0000;"> conf</span><span style="color: #0000ff;">="*->default"</span><span style="color: #0000ff;">/></span></pre>
4.进入命令行,并定位到Nutch目录
执行:
ant eclipse -verbose
由于网络带宽问题,整个过程执行了半个小时
执行完成之后如下图所示

发现build文件夹比原来多了很多内容。
5. 打开Eclipse
使用Import 导入Nutch工程
6.配置conf/nutch-site.xml

<?xml version="1.0"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?><!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>http.agent.name</name>
<value>YourNutchSpider</value>
</property><property>
<name>http.accept.language</name>
<value>ja-jp, en-us,en-gb,en,zh-cn,zh-tw;q=0.7,*;q=0.3</value>
<description>Value of the “Accept-Language” request header field.
This allows selecting non-English language as default one to retrieve.
It is a useful setting for search engines build for certain national group.</description>
</property><property>
<name>parser.character.encoding.default</name>
<value>utf-8</value>
<description>The character encoding to fall back to when no other information
is available</description>
</property><property>
<name>plugin.folders</name>
<value>src/plugin</value>
<description>Directories where nutch plugins are located. Each
element may be a relative or absolute path. If absolute, it is used
as is. If relative, it is searched for on the classpath.</description>
</property>
<property></property>
<property>
<name>storage.data.store.class</name>
<value>org.apache.gora.sql.store.SqlStore</value>
<description>The Gora DataStore class for storing and retrieving data.
Currently the following stores are available: ….</description>
</property><property>
<name>generate.batch.id</name>
<value>*</value>
</property></configuration>
7.配置 gora.properties
gora.datastore.default=org.apache.gora.sql.store.SqlStore gora.datastore.autocreateschema=true gora.sqlstore.jdbc.driver=com.mysql.jdbc.Driver gora.sqlstore.jdbc.url=jdbc:mysql://localhost:3306/nutch?createDatabaseIfNotExist=true&useUnicode=true&characterEncoding=utf8&autoReconnect=true&zeroDateTimeBehavior=convertToNull gora.sqlstore.jdbc.user=root gora.sqlstore.jdbc.password=
8.创建mysql数据库和表结构
CREATE TABLE webpage (
id varchar(256) NOT NULL,
headers blob,
text longtext DEFAULT NULL,
status int(11) DEFAULT NULL,
markers blob,
parseStatus blob,
modifiedTime bigint(20) DEFAULT NULL,
prevModifiedTime bigint(20) DEFAULT NULL,
score float DEFAULT NULL,
typ varchar(32) CHARACTER SET latin1 DEFAULT NULL,
batchId varchar(32) CHARACTER SET latin1 DEFAULT NULL,
baseUrl varchar(256) DEFAULT NULL,
content longblob,
title text DEFAULT NULL,
reprUrl varchar(256) DEFAULT NULL,
fetchInterval int(11) DEFAULT NULL,
prevFetchTime bigint(20) DEFAULT NULL,
inlinks mediumblob,
prevSignature blob,
outlinks mediumblob,
fetchTime bigint(20) DEFAULT NULL,
retriesSinceFetch int(11) DEFAULT NULL,
protocolStatus blob,
signature blob,
metadata blob,
PRIMARY KEY (id)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
9. 配置Crawler.java 的执行参数
具体执行过程是 右键-->"run as"-->configuratiaon-->java Application -->右键new一个运行配置,在program arguments中输入“urls -dir crawl -depth 3 -topN 50" 在 vm arguments中输入"-Dhadoop.log.dir=logs -Dhadoop.log.file=hadoop.log"(前提建立了下文提到的文件加和文件),在这些参数书官方的,可以按照下面图片输入即可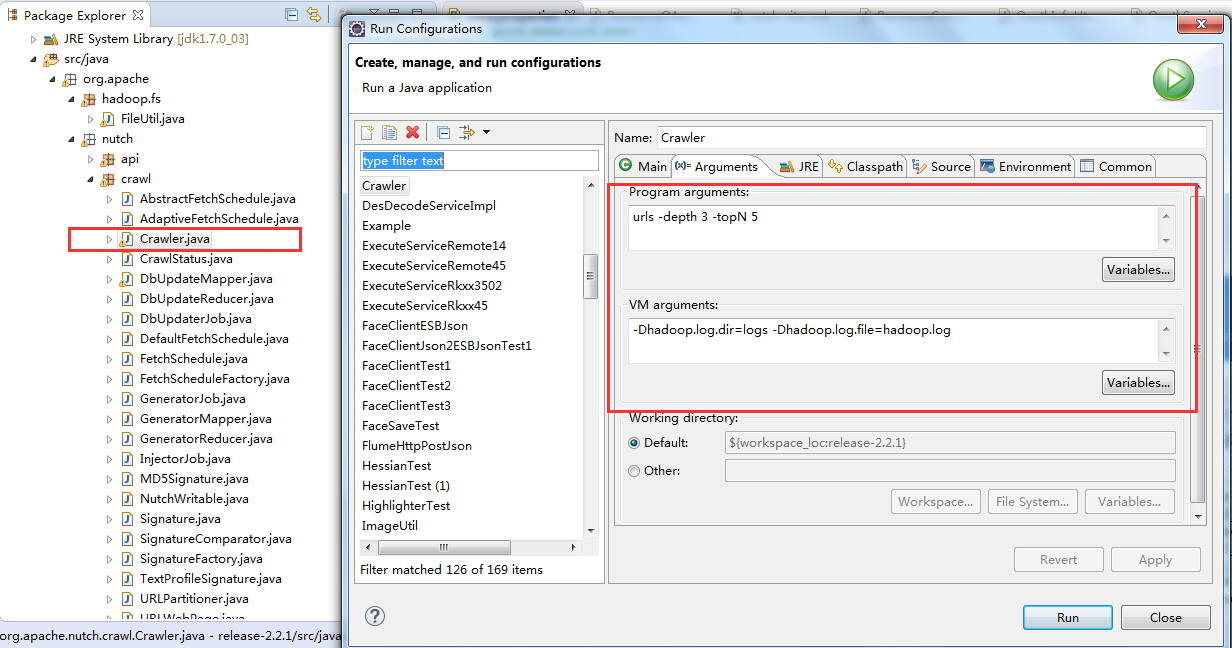
10. 修改Hadoop的FileUtil.java
由于windows平台问题,需要修改FileUtil.java 代码,将红色部分注释掉(自己将”hadoop-core1.2.0.jar“源码重新编译后重新打jar包替换掉ant下载的jar报就可了,也可以下载线程打包好的。另外,直接替换构建的buid文件夹下的lib文件夹直接替换即可,然后在buidpath中先移除原来的jar包引用再引入即可!)。否则在执行Crawl 过程中会报Hadoop的路径权限错误
1 private static void checkReturnValue(boolean rv, File p, FsPermission permission) 2 throws IOException 3 { 4 //if (!rv) 5 // throw new IOException(new StringBuilder().append("Failed to set permissions of path: ").append(p).append(" to ").append(String.format("%04o", new Object[] { Short.valueOf(permission.toShort()) })).toString()); 6 }
11. 在工程目录创建urls 文件夹,并在文件夹中创建seed.txt文件
添加需要爬取的网站URL路径,如: http://www.cnblogs.com/
注意:这个urls文件夹与Crawler执行参数的urls 对应。
12.执行Crawler.java 观察Mysql 数据
13.在大多数情况下,网站可能配置了反爬虫的功能robots.txt
Nutch也遵守了该协议,但可以通过修改Nutch的源码绕过反爬虫。
只需要将类FetcherReducer 的以下这个代码注释掉即可
/*
if (!rules.isAllowed(fit.u.toString())) {
// unblock
fetchQueues.finishFetchItem(fit, true);
if (LOG.isDebugEnabled()) {
LOG.debug("Denied by robots.txt: " + fit.url);
}
output(fit, null, ProtocolStatusUtils.STATUS_ROBOTS_DENIED,
CrawlStatus.STATUS_GONE);
continue;
}
*/
for (int i = 0; i < args.length; i++) {
if ("-threads".equals(args[i])) {
threads = Integer.parseInt(args[i+1]);
i++;
} else if ("-depth".equals(args[i])) {
depth = Integer.parseInt(args[i+1]);
i++;
} else if ("-topN".equals(args[i])) {
topN = Integer.parseInt(args[i+1]);
i++;
} else if ("-solr".equals(args[i])) {
solrUrl = StringUtils.lowerCase(args[i + 1]);
i++;
} else if ("-numTasks".equals(args[i])) {
numTasks = Integer.parseInt(args[i+1]);
i++;
} else if ("-continue".equals(args[i])) {
// skip
} else if (args[i] != null) {
seedDir = args[i];
}
}
Map<String,Object> argMap = ToolUtil.toArgMap(
Nutch.ARG_THREADS, threads,
Nutch.ARG_DEPTH, depth,
Nutch.ARG_TOPN, topN,
Nutch.ARG_SOLR, solrUrl,
Nutch.ARG_SEEDDIR, seedDir,
Nutch.ARG_NUMTASKS, numTasks);
run(argMap);
return 0;
}
参考地址:https://wiki.apache.org/nutch/RunNutchInEclipse1.0
QA列表:http://www.cnblogs.com/jpfss/p/7891792.html