下载和安装Neo4j
- 安装Java JDK
- 下载Neo4j安装文件
- 创建系统环境变量
Neo4j配置
配置文档存储在conf目录下,Neo4j通过配置文件neo4j.conf控制服务器的工作。默认情况下,不需要进行任意配置,就可以启动服务器。
核心数据文件的位置
例如,核心数据文件存储的位置,默认是在data/graph.db目录中,要改变默认的存储目录,可以更新配置选项:
# The name of the database to mount
#dbms.active_database=graph.db
Paths of directories in the installation.
dbms.directories.data=data
安全验证,默认是启用的
# Whether requests to Neo4j are authenticated.
# To disable authentication, uncomment this line
#dbms.security.auth_enabled=false
配置JAVA 堆内存的大小
# Java Heap Size: by default the Java heap size is dynamically calculated based on available system resources.
# Uncomment these lines to set specific initial and maximum heap size.
#dbms.memory.heap.initial_size=512m
#dbms.memory.heap.max_size=512m
网络连接配置
Neo4j支持三种网络协议(Protocol)
Neo4j支持三种网络协议(Protocol),分别是Bolt,HTTP和HTTPS,默认的连接器配置有三种,为了使用这三个端口,需要在Windows防火墙中创建Inbound Rules,允许通过端口7687,7474和7473访问本机。
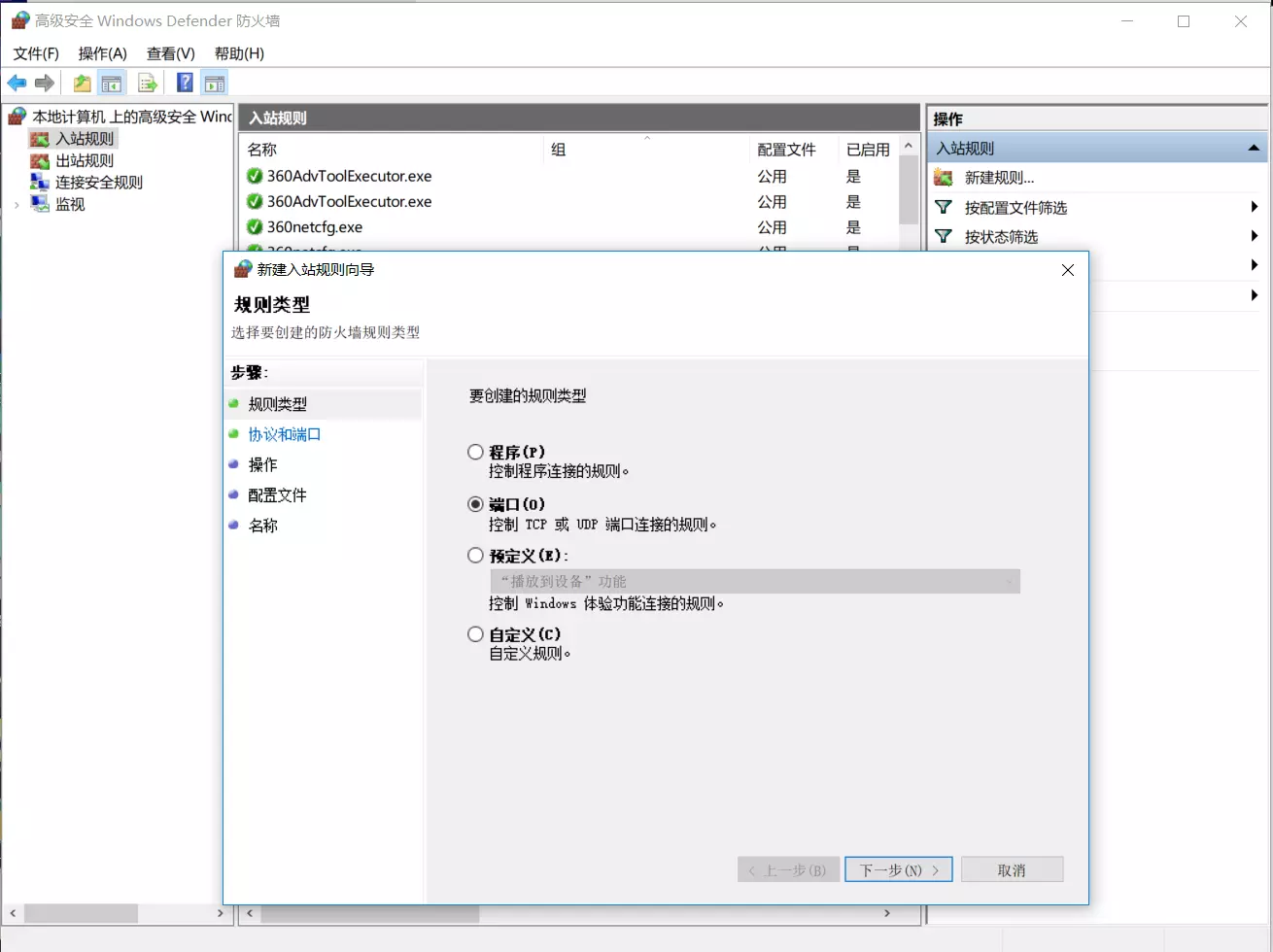

连接器的可选属性

listen_address:设置Neo4j监听的链接,由两部分组成:IP地址和端口号(Port)组成,格式是:<ip-address>:<port-number>
设置默认的监听地址
设置默认的网络监听的IP地址,该默认地址用于设置三个网络协议(Bolt,HTTP和HTTPs)的监听地址,即设置网络协议的属性:listen_address地址。在默认情况下,Neo4j只允许本地主机(localhost)访问,要想通过网络远程访问Neo4j数据库,需要修改监听地址为 0.0.0.0,这样设置之后,就能允许远程主机的访问。
# With default configuration Neo4j only accepts local connections.
# To accept non-local connections, uncomment this line:
dbms.connectors.default_listen_address=0.0.0.0
分别设置各个网络协议的监听地址和端口
HTTP链接器默认的端口号是7474,Bolt链接器默认的端口号是7687,必须在Windows 防火墙中允许远程主机访问这些端口号。
# Bolt connector
dbms.connector.bolt.enabled=true
#dbms.connector.bolt.tls_level=OPTIONAL
#dbms.connector.bolt.listen_address=0.0.0.0:7687
HTTP Connector. There must be exactly one HTTP connector.
dbms.connector.http.enabled=true
dbms.connector.http.listen_address=0.0.0.0:7474
HTTPS Connector. There can be zero or one HTTPS connectors.
dbms.connector.https.enabled=true
dbms.connector.https.listen_address=0.0.0.0:7473
启动Neo4j程序
通过控制台启动Neo4j程序
点击组合键:Windows+R,输入cmd,启动DOS命令行窗口,切换到主目录,以管理员身份运行命令:
./neo4j.bat console
把Neo4j安装为服务(Windows Services)
安装和卸载服务:
bin
eo4j install-service
bin
eo4j uninstall-service
启动服务,停止服务,重启服务和查询服务的状态:
./neo4j.bat start
./neo4j.bat stop
./neo4j.bat restart
./neo4j.bat status
打开Neo4j集成的浏览器
Neo4j服务器具有一个集成的浏览器,在一个运行的服务器实例上访问 “http://localhost:7474/”,打开浏览器,显示启动页面
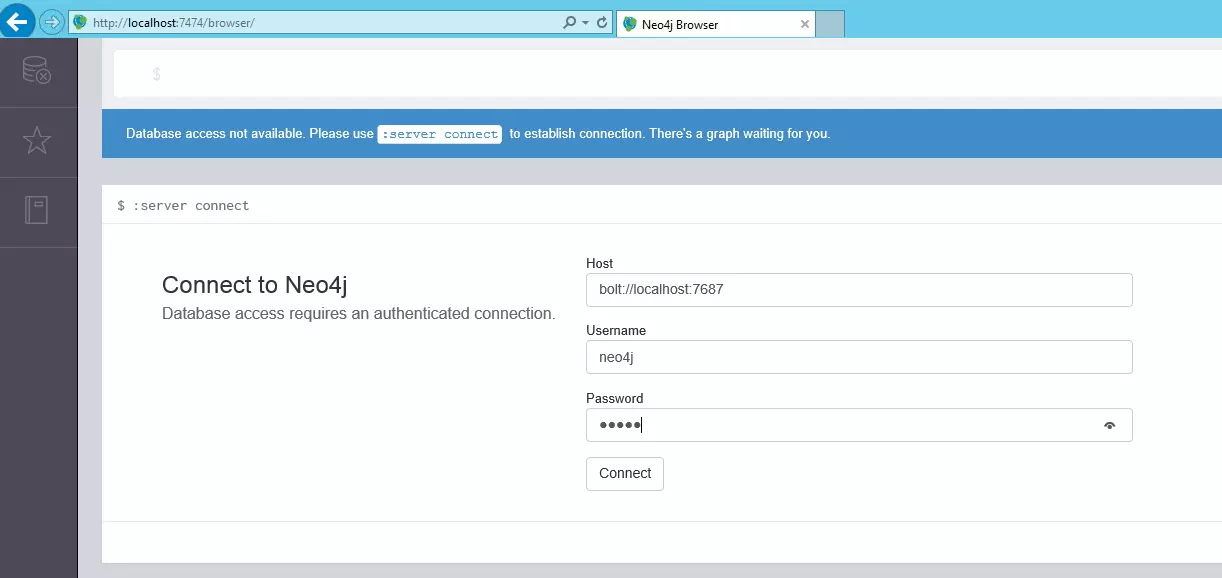
默认的host是bolt://localhost:7687,默认的用户是neo4j,其默认的密码是:neo4j,第一次成功登陆到Neo4j服务器之后,需要重置密码。
访问Graph Database需要输入身份验证,Host是Bolt协议标识的主机。
导入三元组
生成节点与关系csv文件
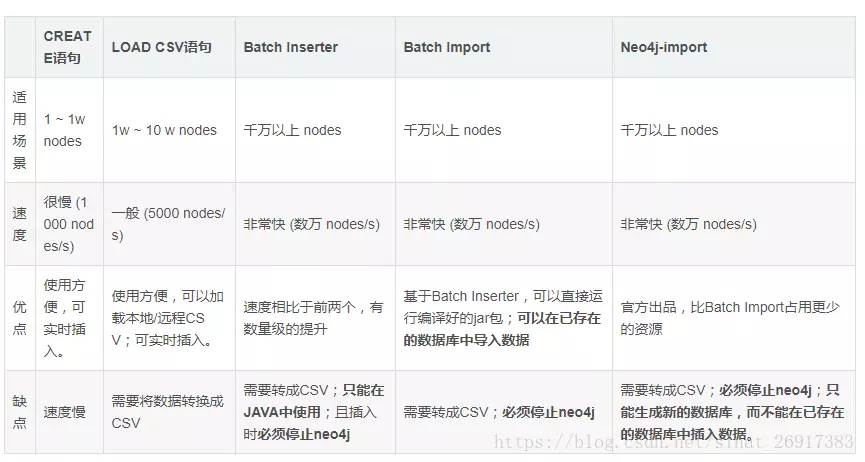
语句插入往往非常缓慢,当需要插入大量三元组时考虑使用Neo4j-import的方式。
这种方式有许多注意点:
- 传入文件名的时候务必使用绝对路径。
- 在执行指令之前务必保证Neo4j处于关闭状态,如果不确定可以在Neo4j根目录下运行./bin/neo4j status 查看当前状态。
- 使用neo4j-admin import指令导入之前先将原数据库从neo4j_home/data/databases/graph.db/中移除。
- 写CSV文件的时候务必确保所有的节点的CSV文件的ID fileds的值都唯一、不重复。并且确保所有的边的CSV文件的START_ID 和 END_ID都包含在节点CSV文件中。
本人原三元组文件:
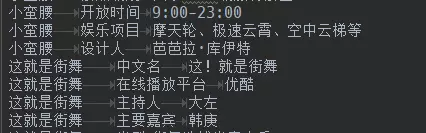
两边为实体/属性,中间为关系
python程序
#!/usr/bin/env python
# _*_ coding:utf-8 _*_
import pandas as pd
import csv
# 读取三元组文件
h_r_t_name = [":START_ID", "role", ":END_ID"]
h_r_t = pd.read_table("entity_sig.txt", decimal=" ", names=h_r_t_name)
print(h_r_t.info())
print(h_r_t.head())
# 去除重复实体
entity = set()
entity_h = h_r_t[':START_ID'].tolist()
entity_t = h_r_t[':END_ID'].tolist()
for i in entity_h:
entity.add(i)
for i in entity_t:
entity.add(i)
print(entity)
# 保存节点文件
csvf_entity = open("entity.csv", "w", newline='', encoding='utf-8')
w_entity = csv.writer(csvf_entity)
# 实体ID,要求唯一,名称,LABEL标签,可自己不同设定对应的标签
w_entity.writerow(("entity:ID", "name", ":LABEL"))
entity = list(entity)
entity_dict = {}
for i in range(len(entity)):
w_entity.writerow(("e" + str(i), entity[i], "my_entity"))
entity_dict[entity[i]] = "e"+str(i)
csvf_entity.close()
# 生成关系文件,起始实体ID,终点实体ID,要求与实体文件中ID对应,:TYPE即为关系
h_r_t[':START_ID'] = h_r_t[':START_ID'].map(entity_dict)
h_r_t[':END_ID'] = h_r_t[':END_ID'].map(entity_dict)
h_r_t[":TYPE"] = h_r_t['role']
h_r_t.pop('role')
h_r_t.to_csv("roles.csv", index=False)
实体文件:
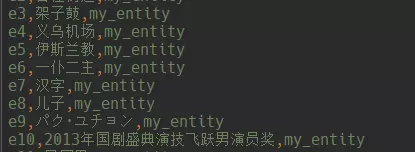
关系文件:

导入文件
.
eo4j-admin.bat import --nodes D:\python_workplaces\get_kg\entity.csv --relationships D:\python_workplaces\get_kg\roles.csv
启动浏览器即可查看
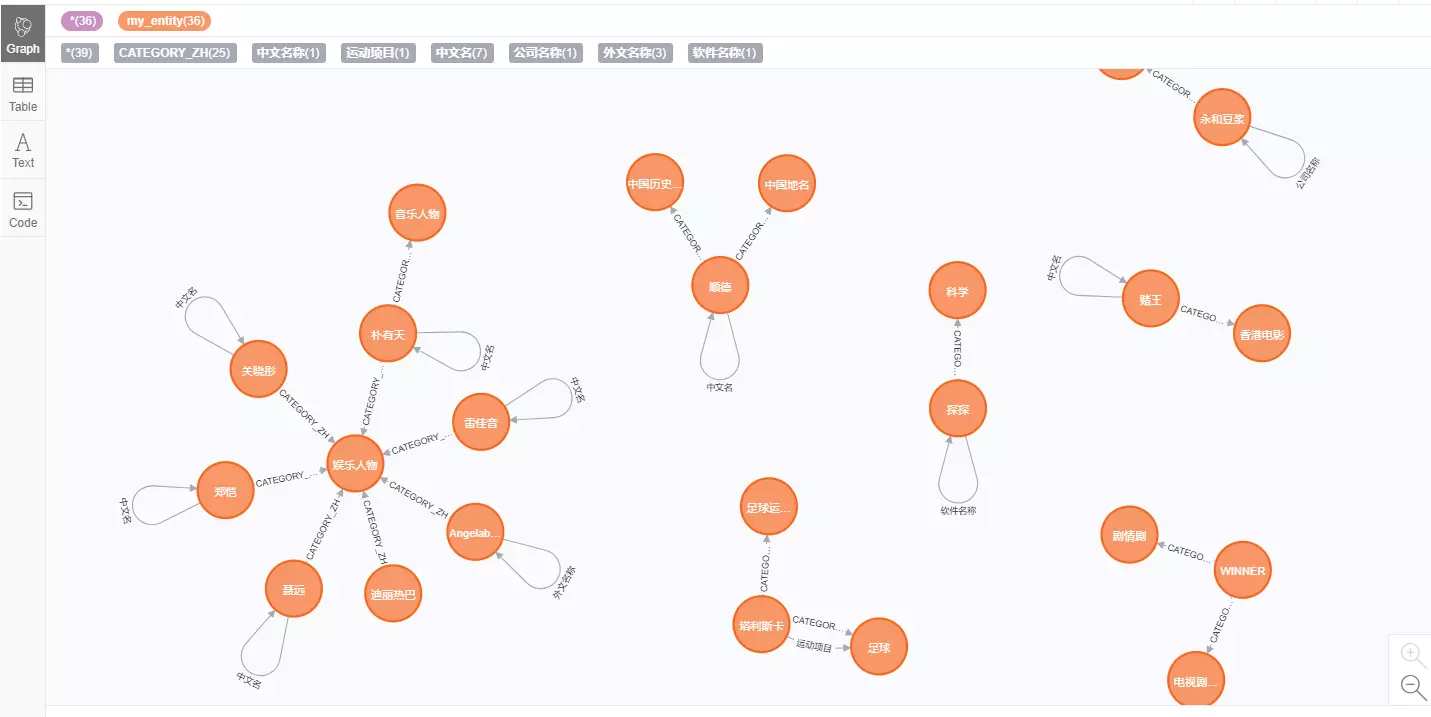
参考文献
https://www.cnblogs.com/ljhdo/p/5521577.html
https://blog.csdn.net/sinat_26917383/article/details/82424508
https://blog.csdn.net/weixin_40322587/article/details/80846106