原帖地址:https://d-bi.gitee.io/sqlserver-ml-services/
新年第一篇,去旧迎新。本文内容,既旧也新。旧之处在于,SQL Server 机器学习服务是微软在SQL Server 2016 中就引入的新功能,但当时只支持R语言,所以也称为”R Server”,在SQL Server 2017及后续版本中,提供了对Python的支持,因此,现称为”Machine Learning Services(机器学习服务)”的功能自发布至今为止已有两年多的时间,故而这并不算一个新功能。而新的地方在于,此功能自发布起国内资料极少,一方面使用较旧版本SQL Server的用户依然很多,另一方面是很多人对该功能缺乏了解,然而,机器学习算法可以对数据进行深度挖掘,这对企业BI智能化的意义非常大,将AI融入BI也是企业未来实现商业智能的大方向。

本文将首先讲述机器学习服务(以Python为例)的概念,意义以及其基本应用原理,简单讲讲它的安装和部署方面的相关问题,最后会提供一个教程讲解其具体的应用方法。
什么是机器学习服务?
机器学习服务是SQL Server中提供的一项新特性,它允许用户可以在SQL Server中,使用存储过程调用R或Python脚本处理数据, 训练和部署机器学习模型。通俗地说,SQL Server数据库的数据可以直接传递至Python中进行处理和建模,Python处理好后可以将结果返回到SQL Server数据库(下文会进一步讲述这点),此方式使SQL Server集成了Python在数据处理和机器学习算法方面的强大功能,且这一切操作均在SQL Server内部完成(因此这也不同于独立版本的SQL Server机器学习服务器)。
(注:SQL Server 2019还提供了对Java支持,但不属于机器学习服务,在此忽略)
为何要使用机器学习服务?
到此处,部分读者可能会问,即使不使用机器学习服务,Python依然可以利用一些库(如sqlalchemy)来实现从数据库中获取和写回数据(如此文),依然可以利用Python强大的算法库预测数据并将结果写回数据库,那为何还要使用机器学习服务呢?事实上,这是不同的,因为利用SQL Server机器学习服务,能够带来如下优势:
- 可重复利用性。执行包含Python脚本的存储过程训练出的模型可以进行序列化,以单个值的形式存储在实体表中,只要模型调试好就可以在以后需要时重复利用。比如你可以提供给其他应用程序(如SSIS) 或其他的存储过程继续调用,部署到生产环境中,定期执行数据挖掘。
- 拓展性。SQL Server 机器学习服务使用Anaconda发行版,内置丰富的Python库,还可以安装第三方框架,如 TensorFlow和scikit-learn。
- 安全性。此功能在数据所在的位置运行脚本,无需通过网络将数据传输到其他服务器。通过在 SQL Server 管理的安全框架内执行受信任的脚本语言,数据库管理员可以在维持安全性的同时允许数据挖掘工程师访问企业数据。
- 可监控性。可以在SSMS中使用由微软提供或自行设计的报表监视Python的执行情况(关于安装此报表)。
- 与BI工具集成。存储过程中的参数值可以传递至Python,这意味着在使用SSRS(或Power BI Report Builder) 构建的报表中,用户可以直接调整机器学习算法中的参数,将算法模型的调优及结果的呈现自动化。比如使用多元线性回归预测销售数据,通过调整模型中不同的参数来优化模型(对于此,如果你使用Power BI, 此文提供了使用DAX建模及调优的用例)
(若针对于R语言,还有一个优势是可以以多线程的方式执行R脚本,而Python本身就支持多线程)
机器学习服务的运行原理
在SQL Server中安装了机器学习服务后,在SQL Server 配置管理器中会出现一个名为”SQL Server Launchpad”的服务,此即为SQL Server用于执行外部脚本(Python或R)的服务,官方提供的运行流程如下图所示,在此不一一赘述,详情可参考此文档:
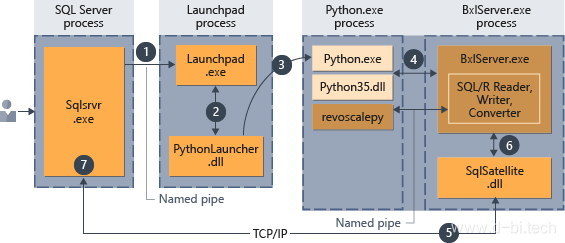
(注:关于revoscalepy, 这是一个由微软开发的Python机器学习库,它提供了一些常用的机器学习算法,如决策树,线性回归以及Logistic回归等),支持分布和远程计算环境,详见文档)
关于安装与部署
在SQL Server中训练并部署Python模型需要SQL Server至少在2017及以上版本,在Windows和Linux上都可以安装机器学习服务。关于安装与部署,我会在下文提供几个十分有用的链接来帮助你顺利的在SQL Server安装机器学习服务器。
(如果你需要下载全新的SQL Server可点此到达下载页面)
安装此功能,你需要打开SQL Server Installation Center,进入安装向导,添加Machine Learning Services及Python两项功能,你可以参考官方文档了解详细的安装过程。如果你在安装过程中遇到问题导致安装失败,你可以参考此文档,该文档详细列出出了可能遇到的问题以及解决建议。离线安装机器学习服务参考此文档,在该文档提到你需要下载两个CAB文件放置在你的安装根目录中:

如果你的SQL Server不是初始版本(RTM),那么在安装过程中需要提供的两个CAB文件需要和你的SQL Server具体版本相对应(查SQL Server具体版本的命令:SELECT @@VERSION),此页面提供了完整的SQL Server累计更新中各版本对应的CAB文件下载的下载地址。
(注:对于简体中文版需要将CAB文件后缀名由1033改为2052,否则安装程序会找不到CAB文件从而导致报错)
安装成功后,可以尝试运行较简单的Python脚本作为测试,此文档提供了一个很好的入门教程,可以让你慢慢熟悉使用存储过程来调用Python的方法。
如何使用机器学习服务训练预测模型(Python)
典型的流程是,打开SSMS,先创建一个包含Python建模代码的存储过程,执行该存储过程将模型以单条记录保存在一张实体表,然后第二个存储过程从该表中获取该记录,调用该模型为新数据生成预测(回归或分类),并将结果返回到新的实体表中。
(提示:建议先使用Python IDE完成Pyhon脚本,一个好的建议是打开机器学习服务安装根目录,打开jupyter-notebook.exe,使用jupyter notebook测试Python脚本)
以下案例是我以红酒质量数据集为例,使用70%的数据作为训练数据,30%的数据作为测试数据,使用随机森林算法预测红酒的质量等级。具体步骤如下:
1.创建一个存储过程—用于训练数据集以生成预测模型
(其中:@input_data_参数用于获取数据集)
DROP PROCEDURE IF EXISTS generate_model_rfc; go CREATE PROCEDURE generate_model_rfc (@trained_model varbinary(max) OUTPUT) AS BEGIN EXECUTE sp_execute_external_script @language = N'Python' , @script = N' import numpy as np import pandas as pd import pickle from sklearn.model_selection import train_test_split from sklearn.ensemble import RandomForestClassifier from sklearn import metrics dt = train_data dt["Level"] = dt["Level"].astype(''category'') X = dt[["Fixed Acidity","Volatile Acidity","Citric acid","Residual Sugar","Chlorides","Free Sulfur Dioxide","Total Sulfur Dioxide","Density","PH","Sulphates","Alcohol"]] Y = dt[["Level"]] X_Train, X_Test, Y_Train, Y_Test = train_test_split(X, Y, test_size=0.3, random_state=42) RFC=RandomForestClassifier(n_estimators=100,criterion=''gini'',min_samples_split=2,max_depth=2) RFC.fit(X_Train,Y_Train.values.ravel()) trained_model = pickle.dumps(RFC) ' , @input_data_1 = N'select "Fixed Acidity", "Volatile Acidity", "Citric acid", "Residual Sugar", "Chlorides", "Free Sulfur Dioxide", "Total Sulfur Dioxide", "Density", "PH", "Sulphates", "Alcohol", "Level" from dbo.RedWineQuality' , @input_data_1_name = N'train_data' , @params = N'@trained_model varbinary(max) OUTPUT' , @trained_model = @trained_model OUTPUT; END; GO
2.创建一个表–用于存储预测模型
CREATE TABLE dbo.my_py_models ( model_name VARCHAR(50) NOT NULL DEFAULT('default model') PRIMARY KEY, model_object VARBINARY(MAX) NOT NULL ); GO
3.执行第一个存储过程–生成预测模型并存储在上述创建的表(my_py_models)中
DECLARE @model_object VARBINARY(MAX); EXEC generate_model_rfc @model_object OUTPUT; INSERT INTO my_py_models (model_name, model_object) VALUES('RandomForestClassification(RFC)', @model_object);
4.创建第二个存储过程–用于调用现有预测模型对新增数据进行预测
本案例的训练数据集和测试数据集是在Python脚本之中使用train_test_split进行拆分,而官方文档的案例与此不同,训练数据集和测试数据集使用WHERE拆分,先后作为参数传递给两个存储过程的Python脚本,因此本案例无论是generate_model_rfc(第一个存储过程)还是py_predict_rfc,@input_data_1参数都是一样的。因此本案例对于不便使用WHERE拆分的数据集有一定参考性,在此注意两次拆分都需要指定相同的随机种子(如此处:random_state=42)
DROP PROCEDURE IF EXISTS py_predict_rfc; GO CREATE PROCEDURE py_predict_rfc (@model varchar(100)) AS BEGIN DECLARE @py_model varbinary(max) = (select model_object from dbo.my_py_models where model_name = @model); EXEC sp_execute_external_script @language = N'Python', @script = N' import pickle import numpy as np import pandas as pd from sklearn.model_selection import train_test_split py_model_rfc = pickle.loads(py_model) dt = data dt["Level"] = dt["Level"].astype(''category'') X = dt[["Fixed Acidity","Volatile Acidity","Citric acid","Residual Sugar","Chlorides","Free Sulfur Dioxide","Total Sulfur Dioxide","Density","PH","Sulphates","Alcohol"]] Y = dt[["Level"]] X_Train, X_Test, Y_Train, Y_Test = train_test_split(X, Y, test_size=0.3, random_state=42) Predictions = py_model_rfc.predict(X_Test) OutputDataSet=pd.DataFrame(data=Predictions,columns=[''Prediction'']) OutputDataSet[''Actual''] = pd.Series(Y_Test[''Level''].values,index=np.arange(0,len(Y_Test))) ' , @input_data_1 = N'select "Fixed Acidity", "Volatile Acidity", "Citric acid", "Residual Sugar", "Chlorides", "Free Sulfur Dioxide", "Total Sulfur Dioxide", "Density", "PH", "Sulphates", "Alcohol", "Level" from dbo.RedWineQuality' , @input_data_1_name = N'data' , @params = N'@py_model varbinary(max)' , @py_model = @py_model with result sets (("Prediction" int, "Actual" int)); END; GO
5.创建一个新表–用于存储模型测试结果
CREATE TABLE [dbo].[py_rfc_predictions]( [Prediction] int, [Actual] int )
6.执行第二个存储过程–预测数据并将结果输出到上述新表(py_rfc_predictions)中
如前述代码所示,该表返回是一个仅有两个字段的验证表,一列存放预测的数据–[Prediction],一列是真实的数据–[Actual]。
INSERT INTO py_rfc_predictions EXEC py_predict_rfc 'RandomForestClassification(RFC)'; SELECT * FROM py_rfc_predictions;
至此,即是机器学习模型训练与使用的完整流程。
总结
SQL Server和Python的强强联手,能够使报表开发者更好地获取到经过机器学习算法生成的深度挖掘的数据,这类数据往往难以使用前端的BI工具完成,比如在Power BI中,利用DAX只能实现简单基础的算法(如用DAX实现KNN分类算法),在Power BI Premium以及Power BI Embedded中虽然具备机器学习功能但只支持云端版本,且这种机器学习模型的训练相比用户自己根据自身需求直接使用Python代码训练的方式而言,无论是可选择性还是效果等等,都有很明显的差距。显然在企业环境中,使用机器学习服务挖掘数据并存储在数据库,然后使用前端BI工具直接读取结果集是更规范更实用的办法。

本作品采用知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议进行许可。