sqoop(sql-to-hadoop)
Apache Sqoop是用来实现结构型数据(如关系数据库)和Hadoop之间进行数据迁移的工具。它充分利用了MapReduce的并行特点以批处理的方式加快数据的传输,同时也借助MapReduce实现了容错。
可以把数据从hdfs倒到mysql
也可以把数据从
相当于把数据倒来倒去的工具,
sqoop支持的数据库:
|
Database |
version |
|
connect string matches |
|
HSQLDB |
1.8.0+ |
No |
|
|
MySQL |
5.0+ |
Yes |
|
|
Oracle |
10.2.0+ |
No |
|
|
PostgreSQL |
8.3+ |
Yes (import only) |
|
配置
1.开启zookeeper
2.开启集群服务(hadoop等)
3.上传sqoop并解压
4.进入目录sqoop下的conf(cd sqoop-1.4.5-cdh5.3.6/conf/)
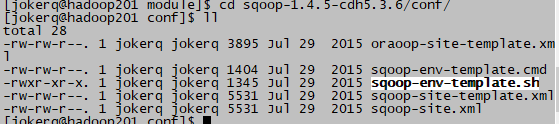
5.cp sqoop-env-template.sh sqoop-env.sh
6.rm -rf *.cmd

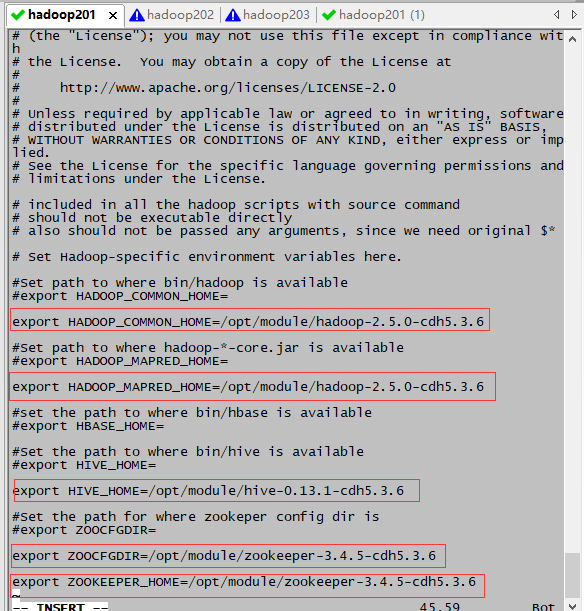
7.修改sqoop-env.sh(HBASE暂时还没有学到,还没有配置,后续会配)
8.拷贝jdbc驱动到sqoop的lib目录下
(cp mysql-connector-java-5.1.27-bin.jar /opt/module/sqoop-1.4.5-cdh5.3.6/lib/)
9.启动sqoop(在sqoop目录下)
9.1 、bin/sqoop help
9.2测试Sqoop是否能够连接成功( bin/sqoop list-databases --connect jdbc:mysql://hadoop201:3306/metastore --username root --password 123456)

案例
一.使用sqoop将mysql中的数据导入到HDFS
1.确定Mysql服务的正常开启
2.在Mysql中创建一张表
mysql -uroot -p mysql> show databses; mysql> create database company; mysql> use company; mysql> create table staff(id int(4) primary key not null auto_increment,name varchar(255) not null,sex varchar(255) not null); mysql> show tables;
mysql> insert into staff(name, sex) values('Thomas', 'Male');
3.操作数据
3.1RDBMS --> HDFS
使用Sqoop导入数据到HDFS
A、全部导入
1.现在hadoop下创建个文件夹(bin/hdfs dfs -mkdir /user/company)
2.进入sqoop目录,执行
bin/sqoop import --connect jdbc:mysql://hadoop201:3306/company --username root --password 123456 --table staff --target-dir /user/company --delete-target-dir --num-mappers 1 --fields-terminated-by " "
也可以写成这种形式(为未写完换行)
bin/sqoop import --connect jdbc:mysql://hadoop201:3306/company --username root --password 123456 --table staff --target-dir /user/company --delete-target-dir (如果目录存在则删除目录) --num-mappers 1 (用几个mapper跑这个任务) --fields-terminated-by " " (用什么分割)
3.查看(在hadoop目录下 bin/hdfs dfs -cat /user/company/*)

B、根据查询语句结果导入
$ bin/sqoop import --connect jdbc:mysql://hadoop201:3306/company --username root --password 123456 --target-dir /user/company --delete-target-dir --num-mappers 1 --fields-terminated-by " " --query 'select name,sex from staff where id >= 2 and $CONDITIONS;'
C、导入指定列
$ bin/sqoop import --connect jdbc:mysql://hadoop201:3306/company --username root --password 123456 --target-dir /user/company --delete-target-dir --num-mappers 1 --fields-terminated-by " " --columns id, sex --table staff
D、使用sqoop关键字筛选查询导入数据
$ bin/sqoop import --connect jdbc:mysql://hadoop201:3306/company --username root --password 123456 --target-dir /user/company --delete-target-dir --num-mappers 1 --fields-terminated-by " " --table staff --where "id=3"
3.2RDBMS --> Hive
1.在hive中创建表(不需要提前创建表,会自动创建)
1.1 在hive目录下 bin/hive
1.2
hive (company)> create table staff_hive(id int, name string, sex string) row format delimited fields terminated by ' ';

1.3向hive中导入数据
$ bin/sqoop import
--connect jdbc:mysql://hadoop201:3306/company
--username root
--password 123456
--table staff
--num-mappers 1
--hive-import
--fields-terminated-by " "
--hive-overwrite
--hive-table company.staff_hive
3.3Hive/HDFS --> MYSQL
1、在Mysql中创建一张表(create table student(id int(4) primary key not null auto_increment,name varchar(255) not null,sex varchar(255) not null,class varchar(255) not null);)

2.
$ bin/sqoop export
--connect jdbc:mysql://hadoo201:3306/company
--username root
--password 123456
--table staff_mysql
--num-mappers 1
--export-dir /user/hive/warehouse/company.db/staff_hive
--input-fields-terminated-by " "