1. Redis集群方案
Redis Cluster 集群模式通常具有 高可用、可扩展性、分布式、容错 等特性。Redis 分布式方案一般有两种:
1.1 客户端分区方案
客户端就已经决定数据会被存储到哪个 redis 节点或者从哪个 redis 节点读取数据。其主要思想是采用 哈希算法 将 Redis 数据的 key 进行散列,通过 hash 函数,特定的 key会映射到特定的 Redis 节点上。
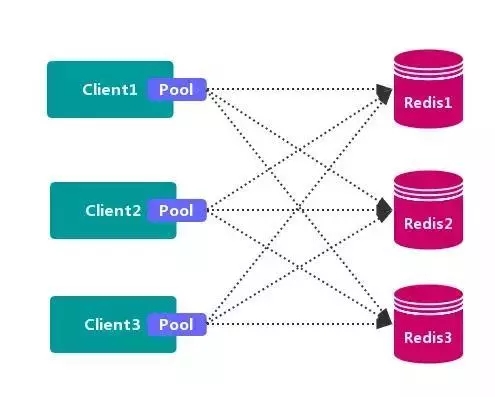
客户端分区方案 的代表为 Redis Sharding,Redis Sharding 是 Redis Cluster 出来之前,业界普遍使用的 Redis 多实例集群 方法。Java 的 Redis 客户端驱动库 Jedis,支持 Redis Sharding 功能,即 ShardedJedis 以及 结合缓存池 的 ShardedJedisPool。
优点
不使用 第三方中间件,分区逻辑 可控,配置 简单,节点之间无关联,容易 线性扩展,灵活性强。
缺点
客户端 无法 动态增删 服务节点,客户端需要自行维护 分发逻辑,客户端之间 无连接共享,会造成 连接浪费。
1.2. 代理分区方案
客户端 发送请求到一个代理组件,代理解析客户端的数据,并将请求转发至正确的节点,最后将结果回复给客户端。
优点:简化 客户端 的分布式逻辑,客户端透明接入,切换成本低,代理的转发和存储分离。
缺点:多了一层代理层,加重了架构部署复杂度和性能损耗。
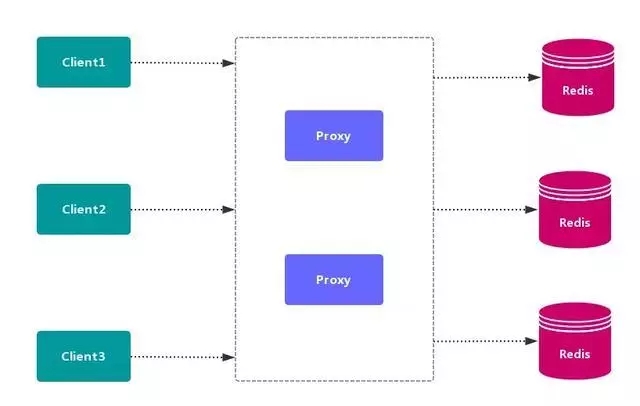
代理分区主流实现的有方案有 Twemproxy 和 Codis。
1.2.1. Twemproxy
Twemproxy 也叫 nutcraker,是 twitter 开源的一个 redis 和 memcache 的 中间代理服务器 程序。Twemproxy 作为 代理,可接受来自多个程序的访问,按照路由规则,转发给后台的各个Redis 服务器,再原路返回。Twemproxy 存在 单点故障 问题,需要结合 Lvs 和 Keepalived 做高可用方案。
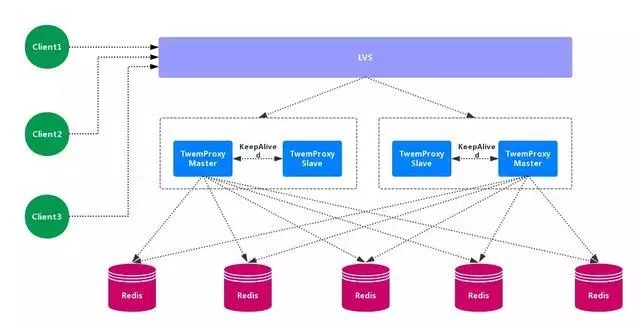
优点:应用范围广,稳定性较高,中间代理层 高可用。
缺点:无法平滑地 水平扩容/缩容,无 可视化管理界面,运维不友好,出现故障,不能 自动转移。
1.2.2. Codis
Codis 是一个分布式 Redis 解决方案,对于上层应用来说,连接 Codis-Proxy 和直接连接原生的 Redis-Server 没有的区别。Codis 底层会处理请求的转发,不停机的进行数据迁移等工作。Codis 采用了无状态的代理层,对于客户端 来说,一切都是透明的。
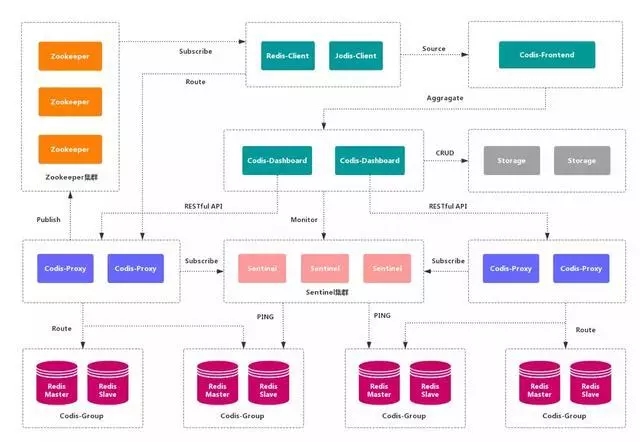
优点
实现了上层 Proxy 和底层 Redis 的 高可用,数据分片 和 自动平衡,提供 命令行接口 和 RESTful API,提供 监控 和 管理 界面,可以动态 添加 和 删除 Redis 节点。
缺点
部署架构 和 配置 复杂,不支持 跨机房 和 多租户,不支持 鉴权管理。
1.3. 查询路由方案
客户端随机地 请求任意一个 Redis 实例,然后由 Redis 将请求 转发 给 正确 的 Redis 节点。Redis Cluster 实现了一种 混合形式 的 查询路由,但并不是 直接 将请求从一个 Redis 节点 转发 到另一个 Redis 节点,而是在 客户端 的帮助下直接 重定向( redirected)到正确的 Redis 节点。

优点
无中心节点,数据按照 槽 存储分布在多个 Redis 实例上,可以平滑的进行节点 扩容/缩容,支持 高可用 和 自动故障转移,运维成本低。
缺点
严重依赖 Redis-trib 工具,缺乏 监控管理,需要依赖 Smart Client (维护连接,缓存路由表,MultiOp 和 Pipeline 支持)。Failover 节点的 检测过慢,不如 中心节点 ZooKeeper 及时。Gossip 消息具有一定开销。无法根据统计区分 冷热数据。
2. 数据分布
2.1. 数据分布理论
分布式数据库 首先要解决把 整个数据集 按照 分区规则 映射到 多个节点 的问题,即把 数据集 划分到 多个节点 上,每个节点负责 整体数据 的一个 子集。

数据分布通常有 哈希分区 和 顺序分区 两种方式,对比如下:
分区方式 特点 相关产品 哈希分区 离散程度好,数据分布与业务无关,无法顺序访问 Redis Cluster,Cassandra,Dynamo 顺序分区 离散程度易倾斜,数据分布与业务相关,可以顺序访问 BigTable,HBase,Hypertable 由于 Redis Cluster 采用 哈希分区规则,这里重点讨论 哈希分区。常见的 哈希分区 规则有几种,下面分别介绍:
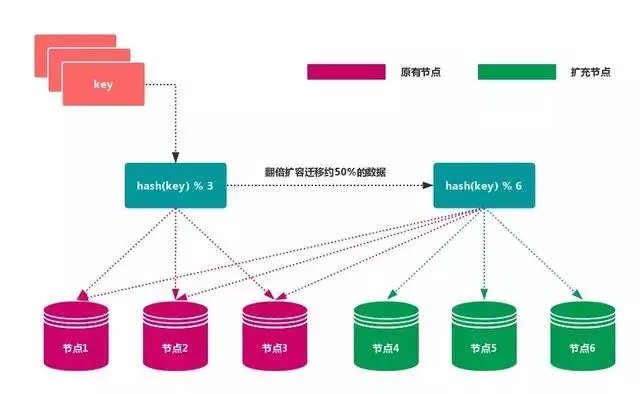
2.1.1. 节点取余分区
使用特定的数据,如 Redis 的 键 或 用户 ID,再根据 节点数量 N 使用公式:hash(key)% N 计算出 哈希值,用来决定数据 映射 到哪一个节点上。
优点
这种方式的突出优点是 简单性,常用于 数据库 的 分库分表规则。一般采用 预分区 的方式,提前根据 数据量 规划好 分区数,比如划分为 512 或 1024 张表,保证可支撑未来一段时间的 数据容量,再根据 负载情况 将 表 迁移到其他 数据库 中。扩容时通常采用 翻倍扩容,避免 数据映射 全部被 打乱,导致 全量迁移 的情况。
缺点
当 节点数量 变化时,如 扩容 或 收缩 节点,数据节点 映射关系 需要重新计算,会导致数据的 重新迁移。
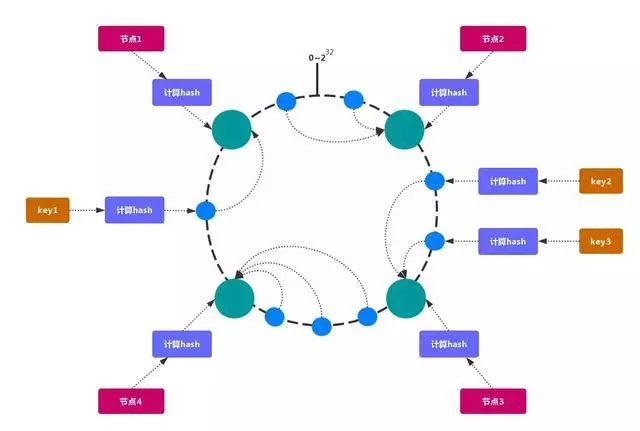
2.1.2. 一致性哈希分区
一致性哈希 可以很好的解决 稳定性问题,可以将所有的 存储节点 排列在 收尾相接 的 Hash 环上,每个 key 在计算 Hash 后会 顺时针 找到 临接 的 存储节点 存放。而当有节点 加入 或 退出 时,仅影响该节点在 Hash 环上 顺时针相邻 的 后续节点。
优点
加入 和 删除 节点只影响 哈希环 中 顺时针方向 的 相邻的节点,对其他节点无影响。
缺点
加减节点 会造成 哈希环 中部分数据 无法命中。当使用 少量节点 时,节点变化 将大范围影响 哈希环 中 数据映射,不适合 少量数据节点 的分布式方案。普通 的 一致性哈希分区 在增减节点时需要 增加一倍 或 减去一半 节点才能保证 数据 和 负载的均衡。
注意:因为 一致性哈希分区 的这些缺点,一些分布式系统采用 虚拟槽 对 一致性哈希 进行改进,比如 Dynamo 系统。
2.1.3. 虚拟槽分区
虚拟槽分区 巧妙地使用了 哈希空间,使用 分散度良好 的 哈希函数 把所有数据 映射 到一个 固定范围 的 整数集合 中,整数定义为 槽(slot)。这个范围一般 远远大于 节点数,比如 Redis Cluster 槽范围是 0 ~ 16383。槽 是集群内 数据管理 和 迁移 的 基本单位。采用 大范围槽 的主要目的是为了方便 数据拆分 和 集群扩展。每个节点会负责 一定数量的槽,如图所示:
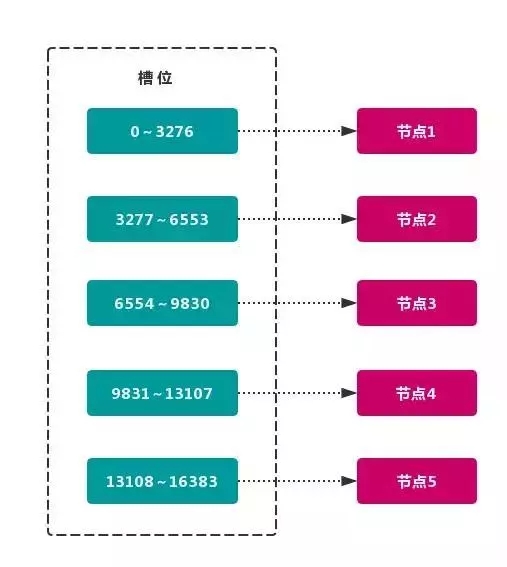
当前集群有 5 个节点,每个节点平均大约负责 3276 个 槽。由于采用 高质量 的 哈希算法,每个槽所映射的数据通常比较 均匀,将数据平均划分到 5 个节点进行 数据分区。Redis Cluster 就是采用 虚拟槽分区。
节点1: 包含 0 到 3276 号哈希槽。
节点2:包含 3277 到 6553 号哈希槽。
节点3:包含 6554 到 9830 号哈希槽。
节点4:包含 9831 到 13107 号哈希槽。
节点5:包含 13108 到 16383 号哈希槽。
这种结构很容易 添加 或者 删除 节点。如果 增加 一个节点 6,就需要从节点 1 ~ 5 获得部分 槽 分配到节点 6 上。如果想 移除 节点 1,需要将节点 1 中的 槽 移到节点 2 ~ 5 上,然后将 没有任何槽 的节点 1 从集群中 移除 即可。
由于从一个节点将 哈希槽 移动到另一个节点并不会 停止服务,所以无论 添加删除或者 改变 某个节点的 哈希槽的数量 都不会造成 集群不可用 的状态.
2.2. Redis的数据分区
Redis Cluster 采用 虚拟槽分区,所有的 键 根据 哈希函数 映射到 0~16383 整数槽内,计算公式:slot = CRC16(key)& 16383。每个节点负责维护一部分槽以及槽所映射的 键值数据,如图所示:

2.2.1. Redis虚拟槽分区的特点
解耦 数据 和 节点 之间的关系,简化了节点 扩容 和 收缩 难度。
节点自身 维护槽的 映射关系,不需要 客户端 或者 代理服务 维护 槽分区元数据。
支持 节点、槽、键 之间的 映射查询,用于 数据路由、在线伸缩 等场景。
2.3. Redis集群的功能限制
Redis 集群相对 单机 在功能上存在一些限制,需要开发人员提前了解,在使用时做好规避。
- key 批量操作支持有限。类似 mset、mget 操作,目前只支持对具有相同 slot 值的 key 执行 批量操作。对于 映射为不同 slot 值的 key 由于执行 mget、mget 等操作可能存在于多个节点上,因此不被支持。
- key 事务操作支持有限。只支持 多 key 在 同一节点上 的 事务操作,当多个 key 分布在 不同 的节点上时 无法 使用事务功能。
- key 作为 数据分区 的最小粒度,不能将一个 大的键值 对象如 hash、list 等映射到 不同的节点。
- 不支持 多数据库空间,单机 下的 Redis 可以支持 16 个数据库(db0 ~ db15),集群模式 下只能使用 一个 数据库空间,即 db0。
- 复制结构 只支持一层
- 从节点 只能复制 主节点,不支持 嵌套树状复制 结构。