目录
文章目录
前文列表
《Ceph 分布式存储架构解析与工作原理》
《手动部署 Ceph Mimic 三节点》
RBD
RBD: Ceph’s RADOS Block Devices , Ceph block devices are thin-provisioned, resizable and store data striped over multiple OSDs in a Ceph cluster.
Ceph RBD 是企业级的块设备存储解决方案,支持扩缩容、支持精简置备,具有 COW 特性,一个块设备(Volume)在 RADOS 中会被分割为若干个 Objects 储存。
CEPH BLOCK DEVICE
- Thin-provisioned
- Images up to 16 exabytes
- Configurable striping
- In-memory caching
- Snapshots
- Copy-on-write cloning
- Kernel driver support
- KVM/libvirt support
- Back-end for cloud solutions
- Incremental backup
- Disaster recovery (multisite asynchronous replication)
RBD Pool 的创建与删除
HELP:
osd pool create <poolname> <int[0-]> {<int[0-]>} {replicated|erasure} {<erasure_code_create pool profile>} {<rule>} {<int>}
创建一个 Pool rbd_pool 并初始化为 RBD 类型:
[root@ceph-node1 ~]# ceph osd pool create rbd_pool 8 8
pool 'rbd_pool' created
[root@ceph-node1 ~]# ceph osd pool create rbd_pool02 8 8
pool 'rbd_pool02' created
[root@ceph-node1 ~]# rbd pool init rbd_pool
[root@ceph-node1 ~]# rbd pool init rbd_pool02
NOTE:创建 Poo 时会指定 pg_num,官方推荐:
- 少于 5 个 OSD, 设置 pg_num 为 128
- 5~10 个 OSD,设置 pg_num 为 512
- 10~50 个 OSD,设置 pg_num 为 4096
- 超过 50 个OSD,可以应用 Ceph PGs per Pool Calculator 来进行计算
查看 Pools 的 df 信息:
[root@ceph-node1 ~]# rados df
POOL_NAME USED OBJECTS CLONES COPIES MISSING_ON_PRIMARY UNFOUND DEGRADED RD_OPS RD WR_OPS WR
.rgw.root 2.2 KiB 6 0 18 0 0 0 63 42 KiB 6 6 KiB
default.rgw.control 0 B 8 0 24 0 0 0 0 0 B 0 0 B
default.rgw.log 0 B 207 0 621 0 0 0 36870 36 MiB 24516 0 B
default.rgw.meta 0 B 0 0 0 0 0 0 0 0 B 0 0 B
rbd_pool 114 MiB 44 0 132 0 0 0 2434 49 MiB 843 223 MiB
total_objects 265
total_used 9.4 GiB
total_avail 81 GiB
total_space 90 GiB
查看每个 Pool 的 df 信息:
[root@ceph-node1 ~]# ceph df
GLOBAL:
SIZE AVAIL RAW USED %RAW USED
90 GiB 79 GiB 11 GiB 12.39
POOLS:
NAME ID USED %USED MAX AVAIL OBJECTS
.rgw.root 3 2.2 KiB 0 24 GiB 6
default.rgw.control 4 0 B 0 24 GiB 8
default.rgw.meta 5 0 B 0 24 GiB 0
default.rgw.log 6 0 B 0 24 GiB 207
images 9 39 MiB 0.16 24 GiB 9
volumes 10 36 B 0 24 GiB 5
vms 11 19 B 0 24 GiB 3
backups 12 19 B 0 24 GiB 2
查看 Pool 的相关信息:
# 查看 Pools 清单
[root@ceph-node1 ~]# rados lspools
rbd_pool
rbd_pool02
# 查看 Pool 的 PG 和 PGP 数量
[root@ceph-node1 ~]# ceph osd pool get rbd_pool pg_num
pg_num: 8
[root@ceph-node1 ~]# ceph osd pool get rbd_pool pgp_num
pgp_num: 8
# 查看当前 OSD 状态
root@ceph-node1 ~]# ceph osd dump | grep pool
pool 1 'rbd_pool' replicated size 3 min_size 1 crush_rule 0 object_hash rjenkins pg_num 8 pgp_num 8 last_change 71 flags hashpspool,selfmanaged_snaps stripe_width 0 application rbd
pool 3 '.rgw.root' replicated size 3 min_size 1 crush_rule 0 object_hash rjenkins pg_num 8 pgp_num 8 last_change 56 owner 18446744073709551615 flags hashpspool stripe_width 0 application rgw
pool 4 'default.rgw.control' replicated size 3 min_size 1 crush_rule 0 object_hash rjenkins pg_num 8 pgp_num 8 last_change 59 owner 18446744073709551615 flags hashpspool stripe_width 0 application rgw
pool 5 'default.rgw.meta' replicated size 3 min_size 1 crush_rule 0 object_hash rjenkins pg_num 8 pgp_num 8 last_change 61 owner 18446744073709551615 flags hashpspool stripe_width 0 application rgw
pool 6 'default.rgw.log' replicated size 3 min_size 1 crush_rule 0 object_hash rjenkins pg_num 8 pgp_num 8 last_change 63 owner 18446744073709551615 flags hashpspool stripe_width 0 application rgw
# 查看 Pool 下属 Obejcts 的 OSD Map 信息,可以看出 Pool rbd_pool 的 Objects 具有 3 副本(PG 被映射到 3 个 OSD)
[root@ceph-node1 ~]# ceph osd map rbd_pool rbd_info
osdmap e53 pool 'rbd_pool' (1) object 'rbd_info' -> pg 1.ac0e573a (1.2) -> up ([4,0,8], p4) acting ([4,0,8], p4)
[root@ceph-node1 ~]# ceph osd map rbd_pool rbd_directory
osdmap e53 pool 'rbd_pool' (1) object 'rbd_directory' -> pg 1.30a98c1c (1.4) -> up ([7,3,1], p7) acting ([7,3,1], p7)
[root@ceph-node1 ~]# ceph osd map rbd_pool rbd_id.volume01
osdmap e53 pool 'rbd_pool' (1) object 'rbd_id.volume01' -> pg 1.8f1d799c (1.4) -> up ([7,3,1], p7) acting ([7,3,1], p7)
删除一个 RBD 类型的 Pool:
[root@ceph-node1 ~]# ceph osd pool delete rbd_pool02
Error EPERM: WARNING: this will *PERMANENTLY DESTROY* all data stored in pool rbd_pool02. If you are *ABSOLUTELY CERTAIN* that is what you want, pass the pool name *twice*, followed by --yes-i-really-really-mean-it.
[root@ceph-node1 ~]# ceph osd pool delete rbd_pool02 rbd_pool02 --yes-i-really-really-mean-it
Error EPERM: pool deletion is disabled; you must first set the mon_allow_pool_delete config option to true before you can destroy a pool
上述表示删除失败,Pool 的删除是一个风险级别非常高的操作,所以 Ceph 为该操作设定了一个配置项,我们修改配置运行删除 Pool:
# 只允许当前客户端执行删除操作,所以直接修改 /etc/ceph/ceph.conf
[mon]
mon allow pool delete = true
$ systemctl restart ceph-mon.target
再次删除 Pool:
[root@ceph-node1 ~]# ceph osd pool delete rbd_pool02 rbd_pool02 --yes-i-really-really-mean-it
pool 'rbd_pool02' removed
设置 Pool 的配额:
# 设置允许最大 Objects 数量为 100
ceph osd pool set-quota test-pool max_objects 100
# 设置允许最大容量限制为 10GB
ceph osd pool set-quota test-pool max_bytes $((10 * 1024 * 1024 * 1024))
# 取消配额限制只需要把对应值设为 0 即可
Pool 的重命名:
ceph osd pool rename test-pool test-pool-new
创建/删除 Pool Snapshot:
# 创建
ceph osd pool mksnap test-pool test-pool-snapshot
# 删除
ceph osd pool rmsnap test-pool test-pool-snapshot
NOTE:Ceph 有两种 Snapshot 类型,这两种类型是互斥的,在存在 Self Managed Snapshot 的 Pool 中不能再执行 Pool Snapshot,反之亦然。
- Pool Snapshot:对 Pool 执行快照
- Self Managed Snapshot:对 RBD 块设备执行快照
设置 Pool 的元数据:
eph osd pool set {pool-name} {key} {value}
# 设置 Pool 的 PG 副本数量为 3
ceph osd pool set test-pool size 3
块设备的创建与删除
要创建 RBD 块设备,首先需要登录到 Ceph Cluster 的任意 MON 节点,或登录到具有 Ceph Cluster 管理员权限的 Host,或 Ceph 客户端上。下面我们直接在 MON 节点上执行操作。
指定 RBD Pool 创建块设备:
[root@ceph-node1 ~]# rbd create rbd_pool/volume01 --size 1024
[root@ceph-node1 ~]# rbd create rbd_pool/volume02 --size 1024
[root@ceph-node1 ~]# rbd create rbd_pool/volume03 --size 1024
NOTE:如果不指定 RBD 类型的 Pool Name,则默认为 rbd,所以首选需要有一个 Pool rbd。
查看块设备信息:
[root@ceph-node1 ~]# rbd --image rbd_pool/volume01 info
rbd image 'volume01':
size 1 GiB in 256 objects
order 22 (4 MiB objects)
id: 11126b8b4567
block_name_prefix: rbd_data.11126b8b4567
format: 2
features: layering, exclusive-lock, object-map, fast-diff, deep-flatten
op_features:
flags:
create_timestamp: Tue Apr 23 07:30:57 2019
# size:块设备大小
# order:Object 大小,这里 22 表示 2**22 即 4MiB
# block_name_prefix:块设备的 Ceph Cluster 全局唯一标示
# format:块设备格式,有 1、2 两种类型
# features:卷特性,细分为
# - layering:支持分层
# - striping:支持条带化 v2
# - exclusive-lock:支持独占锁
# - object-map:支持对象映射索引,依赖 exclusive-lock
# - fast-diff:支持快速计算差异,依赖 object-map
# - deep-flatten:支持快照扁平化
# - journaling:支持记录 IO 操作,依赖独占锁
查看 Pool 下属的块设备的相关 Obejcts:
[root@ceph-node1 ~]# rados -p rbd_pool ls
...
rbd_directory
rbd_id.volume01
# rbd_id.volume01:保存了 volume01 自己的 block_name_prefix
# rbd_directory:保存了这个 Pool 下属所有块设备的索引
获取 Pool 下的一个 Objects 并查看其内容:
root@ceph-node1 ~]# rados -p rbd_pool get rbd_info rbd_info
[root@ceph-node1 ~]# ls
rbd_info
[root@ceph-node1 ~]# hexdump -vC rbd_info
00000000 6f 76 65 72 77 72 69 74 65 20 76 61 6c 69 64 61 |overwrite valida|
00000010 74 65 64 |ted|
00000013
删除一个块设备:
[root@ceph-node1 ~]# rbd ls rbd_pool
volume01
volume02
volume03
[root@ceph-node1 ~]# rbd rm volume03 -p rbd_pool
Removing image: 100% complete...done.
[root@ceph-node1 ~]# rbd ls rbd_pool
volume01
volume02
块设备的挂载与卸载
RBD 的驱动程序已经被集成到 Linux 内核(2.6.39 或更高版本),将 Linux 操作系统作为客户端挂载卷的前提是加载 RBD 内核模块,下面我们首先将卷挂载到 ceph-node1,因为 ceph-node1 就是一个原生的客户端,不需要额外操作。
映射块设备到客户端本地:
[root@ceph-node1 ~]# lsmod | grep rbd
rbd 83640 2
libceph 306625 1 rbd
[root@ceph-node1 ~]# rbd map rbd_pool/volume01
rbd: sysfs write failed
RBD image feature set mismatch. You can disable features unsupported by the kernel with "rbd feature disable rbd_pool/volume01 object-map fast-diff deep-flatten".
In some cases useful info is found in syslog - try "dmesg | tail".
rbd: map failed: (6) No such device or address
这里执行映射失败了,原因是因为客户端内核版本较低,无法支持卷的全部特性,可以通过以下修改来解决。
设定 Ceph 的全局默认 RBD 块设备特性清单:
$ vi /etc/ceph/ceph.conf
[global]
...
rbd_default_features = 1
$ ceph-deploy --overwrite-conf admin ceph-node1 ceph-node2 ceph-node3
或者在创建块设备的时候单独指定块设备特性:
rbd create rbd_pool/volume03 --size 1024 --image-format 1 --image-feature layering
或者关闭内核不支持的块设备特性之后再映射:
[root@ceph-node1 ~]# rbd info rbd_pool/volume01
rbd image 'volume01':
size 1 GiB in 256 objects
order 22 (4 MiB objects)
id: 11126b8b4567
block_name_prefix: rbd_data.11126b8b4567
format: 2
features: layering, exclusive-lock, object-map, fast-diff, deep-flatten
op_features:
flags:
create_timestamp: Tue Apr 23 07:30:57 2019
[root@ceph-node1 ~]# rbd feature disable rbd_pool/volume01 object-map fast-diff deep-flatten
[root@ceph-node1 ~]# rbd feature disable rbd_pool/volume02 object-map fast-diff deep-flatten
[root@ceph-node1 ~]# rbd info rbd_pool/volume01
rbd image 'volume01':
size 1 GiB in 256 objects
order 22 (4 MiB objects)
id: 11126b8b4567
block_name_prefix: rbd_data.11126b8b4567
format: 2
features: layering, exclusive-lock
op_features:
flags:
create_timestamp: Tue Apr 23 07:30:57 2019
[root@ceph-node1 ~]# rbd map rbd_pool/volume01
/dev/rbd0
查看客户端本地已映射的块设备:
[root@ceph-node1 ~]# rbd showmapped
id pool image snap device
0 rbd_pool volume01 - /dev/rbd0
[root@ceph-node1 ~]# lsblk | grep rbd0
rbd0 252:0 0 1G 0 disk
块设备映射到本地之后就等同于一个裸设备,需要分区格式化以及创建文件系统:
[root@ceph-node1 ~]# mkfs.xfs /dev/rbd0
meta-data=/dev/rbd0 isize=512 agcount=8, agsize=32768 blks
= sectsz=512 attr=2, projid32bit=1
= crc=1 finobt=0, sparse=0
data = bsize=4096 blocks=262144, imaxpct=25
= sunit=1024 swidth=1024 blks
naming =version 2 bsize=4096 ascii-ci=0 ftype=1
log =internal log bsize=4096 blocks=2560, version=2
= sectsz=512 sunit=8 blks, lazy-count=1
realtime =none extsz=4096 blocks=0, rtextents=0
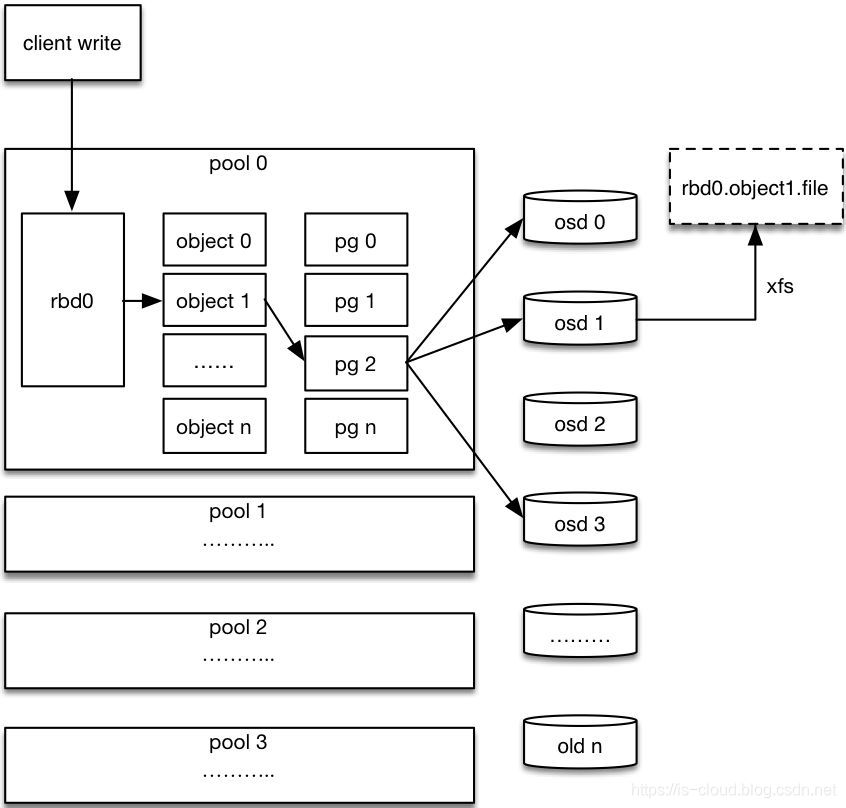
数据最终在 OSDs 上以 Object 的形式储存,Obejcts 的前缀为块设备的 block_name_prefix。随着写入的数据越多,Objects 的数量也会越多:
[root@ceph-node1 deploy]# rados ls -p rbd_pool | grep rbd_data.121896b8b4567
rbd_data.121896b8b4567.0000000000000080
rbd_data.121896b8b4567.00000000000000a0
rbd_data.121896b8b4567.0000000000000082
rbd_data.121896b8b4567.00000000000000e0
rbd_data.121896b8b4567.00000000000000ff
rbd_data.121896b8b4567.0000000000000081
rbd_data.121896b8b4567.0000000000000040
rbd_data.121896b8b4567.0000000000000020
rbd_data.121896b8b4567.0000000000000000
rbd_data.121896b8b4567.00000000000000c0
rbd_data.121896b8b4567.0000000000000060
rbd_data.121896b8b4567.0000000000000001
NOTE:而且这些块设备对应的 Objects 的后缀是是以 16 进制编码的,Object 的命名规则为 block_name_prefix+index。而且 index range [0x00, 0xff] 就是十进制的 256,表示该块设备的 Size 具有 256 个 Objects。
[root@ceph-node1 ~]# rbd --image rbd_pool/volume01 info
rbd image 'volume01':
size 1 GiB in 256 objects
但很显然,现在实际上并不存在 256 个 Objects,这是因为 Ceph RBD 是精简置备的,并非是完成创建卷时就已经把块设备 Size 对应的 256 个 Objects 都准备好了,Objects 的数量是随着实际数据的写入而逐渐增长的。并且上述的 12 个 Objects 仅仅是格式化 XFS 文件系统时生成的。
mount 块设备并写入数据:
[root@ceph-node1 ~]# mkdir -pv /mnt/volume01
[root@ceph-node1 ~]# mount /dev/rbd0 /mnt/volume01
[root@ceph-node1 ~]# dd if=/dev/zero of=/mnt/volume01/fi1e1 count=10 bs=1M
10+0 records in
10+0 records out
10485760 bytes (10 MB) copied, 0.0129169 s, 812 MB/s
[root@ceph-node1 deploy]# rados ls -p rbd_pool | grep rbd_data.121896b8b4567 | wc -l
37
可以看见,块设备的 Objects 动态增长了。
我们不妨看看块设备 volume01 的第一、第二个 Objects 的内容:
[root@ceph-node1 ~]# rados -p rbd_pool get rbd_data.121896b8b4567.0000000000000000 rbd_data.121896b8b4567.0000000000000000
[root@ceph-node1 ~]# rados -p rbd_pool get rbd_data.121896b8b4567.0000000000000001 rbd_data.121896b8b4567.0000000000000001
[root@ceph-node1 ~]# ll -lht
total 172K
-rw-r--r-- 1 root root 32K Apr 24 06:30 rbd_data.121896b8b4567.0000000000000001
-rw-r--r-- 1 root root 128K Apr 24 06:30 rbd_data.121896b8b4567.0000000000000000
[root@ceph-node1 ~]# hexdump -vC rbd_data.121896b8b4567.0000000000000000 | more
00000000 58 46 53 42 00 00 10 00 00 00 00 00 00 04 00 00 |XFSB............|
...
有两点信息值得我们关注,首先,从第一个 Objects 的内容可以看出它的确是 mkfs.xfs 文件系统时创建的,而且这样的数据就是 XFS 文件系统的格式;再一个,可见 Object0、Object1 的 Size 都没有达到 4MiB,但却创建了更多的 Objects。这是因为客户端将原始数据分片之后是轮询储存到 Object Set 的,而不是存满了一个 Object 再继续存到下一个 Object 的(!!! 这里有待验证,因为 volume01 没有开启条带化特性)。
卸载块设备:
[root@controller ~]# umount /mnt/volume01/
root@ceph-node1 deploy]# rbd showmapped
id pool image snap device
1 rbd_pool volume01 - /dev/rbd1
[root@ceph-node1 deploy]# rbd unmap rbd_pool/volume01
[root@ceph-node1 deploy]# rbd showmapped
关于 RBD 块设备与 XFS 的一个有趣描述:
RBD 其实是一个完完整整的块设备,如果把 1G 的块想成一个 1024 层楼的高楼的话,xfs 可以想象成住在这个大楼里的楼管,它只能在大楼里面,也就只能看到这 1024 层的房子,楼管自然可以安排所有的住户(文件或文件名),住在哪一层哪一间,睡在地板还是天花板(文件偏移量),隔壁的楼管叫做 ext4,虽然住在一模一样的大楼里,但是它们有着自己的安排策略,这就是文件系统如果组织文件的一个比喻。某一天拆迁大队长跑来说,我不管你们(xfs or ext4)是怎么安排的,盖这么高的楼是想做什么,然后大队长把这 1024 层房子,每 4 层(4MiB)砍了一刀,一共砍成了 256 个四层,然后一起打包带走了,运到了一个叫做 Ceph 的小区里面,放眼望去,这个小区里面的房子最高也就四层(填满的),而有些才打了地基(还没写内容)。
新建客户端
这里我们将 OpenStack 的 Controller Node 作为客户端,首先加载 rbd 内核模块:
[root@controller ~]# uname -r
3.10.0-957.10.1.el7.x86_64
[root@controller ~]# modprobe rbd
[root@controller ~]# lsmod | grep rbd
rbd 83640 0
libceph 306625 1 rbd
为了授予客户端访问 Ceph Cluster 的权限,需要将管理员密钥环和配置文件拷贝到客户端上。客户端与 Ceph Cluster 之间的身份验证基于这个密钥环,这里我们使用 admin keyring,使客户端拥有完全访问 Ceph Cluster 的权限。合理的做法应该是创建权限集有限的密钥环分发给非管理员客户端。下面我们依旧通过 ceph-deploy 工具来完成客户端的安装与授权。
-
在 Controller 上配置 Ceph Mimic YUM 源
-
Controller 与 Ceph Deploy 节点免密登录:
[root@ceph-node1 deploy]# ssh-copy-id -i ~/.ssh/id_rsa.pub root@controller
- 在 Controller 上安装客户端软件:
ceph-deploy install controller
- 将密钥环和配置文件拷贝到 Controller
ceph-deploy --overwrite-conf admin controller
LOG:
[ceph_deploy.admin][DEBUG ] Pushing admin keys and conf to controller
- 在客户端查询 Ceph Cluster 状态
[root@controller ~]# ceph -s
cluster:
id: d82f0b96-6a69-4f7f-9d79-73d5bac7dd6c
health: HEALTH_WARN
too few PGs per OSD (2 < min 30)
services:
mon: 3 daemons, quorum ceph-node1,ceph-node2,ceph-node3
mgr: ceph-node1(active), standbys: ceph-node2, ceph-node3
osd: 9 osds: 9 up, 9 in
data:
pools: 1 pools, 8 pgs
objects: 40 objects, 84 MiB
usage: 9.3 GiB used, 81 GiB / 90 GiB avail
pgs: 8 active+clean
- 在 Controller 客户端挂载卷
[root@controller ~]# rbd map rbd_pool/volume02
/dev/rbd0
[root@controller ~]# rbd showmapped
id pool image snap device
0 rbd_pool volume02 - /dev/rbd0
[root@controller ~]# mkfs.xfs /dev/rbd0
meta-data=/dev/rbd0 isize=512 agcount=8, agsize=32768 blks
= sectsz=512 attr=2, projid32bit=1
= crc=1 finobt=0, sparse=0
data = bsize=4096 blocks=262144, imaxpct=25
= sunit=1024 swidth=1024 blks
naming =version 2 bsize=4096 ascii-ci=0 ftype=1
log =internal log bsize=4096 blocks=2560, version=2
= sectsz=512 sunit=8 blks, lazy-count=1
realtime =none extsz=4096 blocks=0, rtextents=0
[root@controller ~]# mkdir -pv /mnt/volume02
mkdir: created directory ‘/mnt/volume02’
[root@controller ~]# mount /dev/rbd0 /mnt/volume02
[root@controller ~]# df -Th
Filesystem Type Size Used Avail Use% Mounted on
/dev/mapper/centos-root xfs 196G 3.2G 193G 2% /
devtmpfs devtmpfs 9.8G 0 9.8G 0% /dev
tmpfs tmpfs 9.8G 0 9.8G 0% /dev/shm
tmpfs tmpfs 9.8G 938M 8.9G 10% /run
tmpfs tmpfs 9.8G 0 9.8G 0% /sys/fs/cgroup
/dev/sda1 xfs 197M 165M 32M 84% /boot
tmpfs tmpfs 2.0G 0 2.0G 0% /run/user/0
/dev/rbd0 xfs 1014M 43M 972M 5% /mnt/volume02
[root@controller ~]# dd if=/dev/zero of=/mnt/volume02/fi1e1 count=10 bs=1M
10+0 records in
10+0 records out
10485760 bytes (10 MB) copied, 0.0100852 s, 1.0 GB/s
块设备的扩缩容
块设备扩容:
[root@ceph-node1 deploy]# rbd resize rbd_pool/volume01 --size 2048
Resizing image: 100% complete...done.
[root@ceph-node1 ~]# rbd info rbd_pool/volume01
rbd image 'volume01':
size 2 GiB in 512 objects
order 22 (4 MiB objects)
id: 11126b8b4567
block_name_prefix: rbd_data.11126b8b4567
format: 2
features: layering, exclusive-lock
op_features:
flags:
create_timestamp: Tue Apr 23 07:30:57 2019
如果已经被挂载了,还要手动检查新的容量是否被内核接收,刷新一下文件系统的大小:
[root@ceph-node1 ~]# df -Th
...
/dev/rbd0 xfs 1014M 103M 912M 11% /mnt/volume01
[root@ceph-node1 ~]# xfs_growfs -d /mnt/volume01/
meta-data=/dev/rbd0 isize=512 agcount=8, agsize=32768 blks
= sectsz=512 attr=2, projid32bit=1
= crc=1 finobt=0 spinodes=0
data = bsize=4096 blocks=262144, imaxpct=25
= sunit=1024 swidth=1024 blks
naming =version 2 bsize=4096 ascii-ci=0 ftype=1
log =internal bsize=4096 blocks=2560, version=2
= sectsz=512 sunit=8 blks, lazy-count=1
realtime =none extsz=4096 blocks=0, rtextents=0
data blocks changed from 262144 to 524288
[root@ceph-node1 ~]# df -Th
...
/dev/rbd0 xfs 2.0G 103M 1.9G 6% /mnt/volume01
RBD 块设备的 Format 1 VS Format 2
众所周知,RBD 块设备有两种格式,不同的格式包含了不同块设备特性集合:
- Format 1:Hammer,rbd_default_features = 3
- Format 2:Jewel,rbd_default_features = 61
Features 编号:配置项 rbd_default_features 的值就是由下列编号相加得到的:
NOTE:Only applies to format 2 images
- +1 for layering,
- +2 for striping v2,
- +4 for exclusive lock,
- +8 for object map
- +16 for fast-diff,
- +32 for deep-flatten,
- +64 for journaling
块设备的快照、克隆、恢复
Ceph 块设备的快照是一个基于时间点的、只读的块设备镜像副本,可以通过创建快照来保存块设备在某一时刻的状态,并且支持创建多次快照,所以快照功能也被称之为 Time Machine(时间机器)。
Ceph RBD 应用的快照技术为 COW(写时复制),通过写时复制可以在保持原始镜像数据不被修改的情况下,得到一个新的镜像或称为快照文件,而新的镜像中储存化了新数据的变更。可见,快照的执行是非常快的,因为它仅更新了块设备的元数据,例如:添加了快照 ID。Ceph RBD 的分层特性与 QCOW2 镜像文件具有一样的特征,更多的 COW 工作原理,请浏览《再谈 COW、ROW 快照技术》。
注:基于具体的实现差异,快照未必会以实际的文件形式而存在。所以,这里 “快照” 的语义表示变更的新数据。
基于 COW 的链式快照:
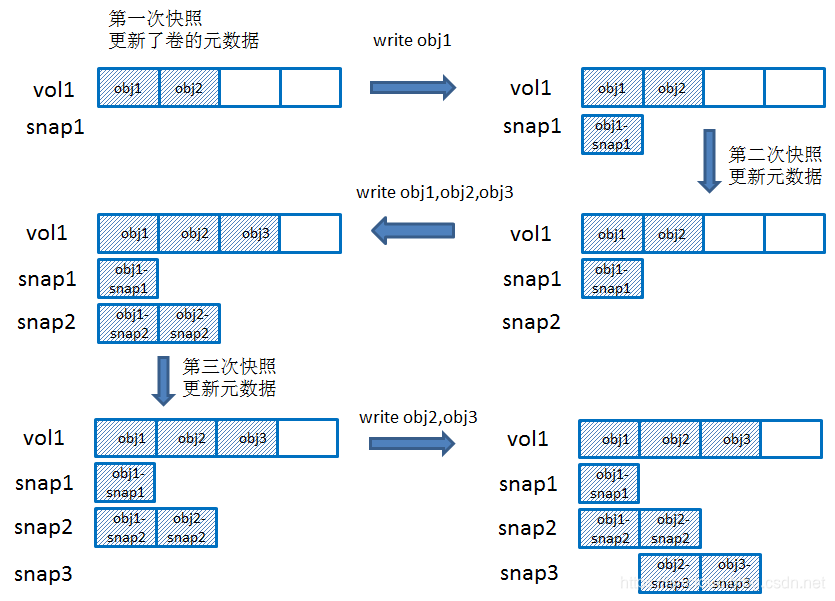
创建快照:
$ rbd snap create rbd_pool/volume01@snap01
查看快照:
[root@ceph-node1 ~]# rbd snap ls rbd_pool/volume01
SNAPID NAME SIZE TIMESTAMP
4 snap01 2 GiB Tue Apr 23 23:50:23 2019
删除指定快照:
$ rbd snap rm rbd_pool/volume01@snap01
删除全部快照:
[root@ceph-node1 ~]# rbd snap purge rbd_pool/volume01
Removing all snapshots: 100% complete...done.
克隆就是基于快照恢复出一个新的块设备,它的执行速度同样很快,只会修改了块设备的元数据,例如:添加了 parent 信息。为了便于理解,我们首先统一一下术语定义:
- 块设备,镜像(RBD Image):Ceph RBD 块设备的统称。
- 原始镜像,模板镜像:被执行快照的块设备。
- COW 副本镜像:通过某一个快照克隆出来的块设备。
NOTE:快照和克隆的区别在于,克隆利用了快照的 COW 分层特性,拷贝了指定快照的数据并转换为一个被 Ceph 认可的新的块设备。
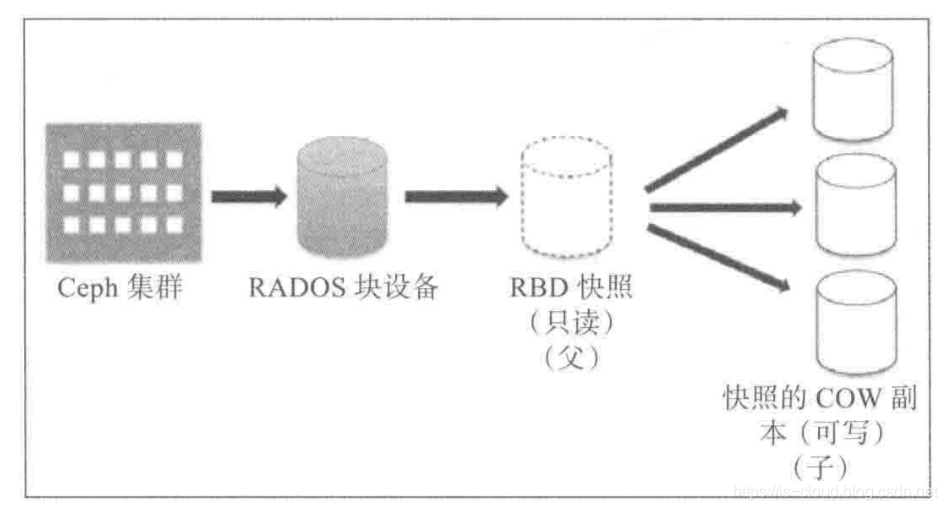
得益于 Ceph RBD 的分层特性,使得对接 Ceph 存储的 Openstack 能够在短时间之内快速地启动数百台虚拟机,而虚拟机磁盘的本质就是 COW 副本镜像,它保存了 GuestOS 更改的数据。
创建 RBD 块设备:
[root@ceph-node1 ~]# rbd create rbd_pool/volume03 --size 1024 --image-format 2
[root@ceph-node1 ~]# rbd ls rbd_pool
volume01
volume02
volume03
[root@ceph-node1 ~]# rbd info rbd_pool/volume03
rbd image 'volume03':
size 1 GiB in 256 objects
order 22 (4 MiB objects)
id: 12bb6b8b4567
block_name_prefix: rbd_data.12bb6b8b4567
format: 2
features: layering
op_features:
flags:
create_timestamp: Wed Apr 24 03:53:28 2019
执行快照:
[root@ceph-node1 ~]# rbd snap create rbd_pool/volume03@snap01
[root@ceph-node1 ~]# rbd snap ls rbd_pool/volume03
SNAPID NAME SIZE TIMESTAMP
8 snap01 1 GiB Wed Apr 24 03:54:53 2019
将快照设为保护(不可被删除)状态,此时的快照就是原始镜像:
rbd snap protect rbd_pool/volume03@snap01
执行克隆操作,得到 COW 副本镜像,包含了父镜像信息:
[root@ceph-node1 ~]# rbd clone rbd_pool/volume03@snap01 rbd_pool/vol01_from_volume03
[root@ceph-node1 ~]# rbd ls rbd_pool
vol01_from_volume03
volume01
volume02
volume03
[root@ceph-node1 ~]# rbd info rbd_pool/vol01_from_volume03
rbd image 'vol01_from_volume03':
size 1 GiB in 256 objects
order 22 (4 MiB objects)
id: faf86b8b4567
block_name_prefix: rbd_data.faf86b8b4567
format: 2
features: layering
op_features:
flags:
create_timestamp: Wed Apr 24 03:56:36 2019
parent: rbd_pool/volume03@snap01
overlap: 1 GiB
执行 COW 副本镜像的扁平化,使其不再依赖父镜像,自身就具有块设备的完整数据(旧+新):
[root@ceph-node1 ~]# rbd flatten rbd_pool/vol01_from_volume03
Image flatten: 100% complete...done.
[root@ceph-node1 ~]# rbd info rbd_pool/vol01_from_volume03
rbd image 'vol01_from_volume03':
size 1 GiB in 256 objects
order 22 (4 MiB objects)
id: faf86b8b4567
block_name_prefix: rbd_data.faf86b8b4567
format: 2
features: layering
op_features:
flags:
create_timestamp: Wed Apr 24 03:56:36 2019
解除保护并删除快照:
[root@ceph-node1 ~]# rbd snap unprotect rbd_pool/volume03@snap01
[root@ceph-node1 ~]# rbd snap rm rbd_pool/volume03@snap01
Removing snap: 100% complete...done.
[root@ceph-node1 ~]# rbd snap ls rbd_pool/volume03
恢复一个快照就是进行一个 “时刻穿越”,将块设备还原到某个特定时间点的状态,所以 Ceph 的恢复指令选择了使用 rollback 一词:
[root@ceph-node1 ~]# rbd snap rollback rbd_pool/volume01@snap01
Rolling back to snapshot: 100% complete...done.
NOTE:如果块设备已经被挂载,那么需要 re-mount 以刷新文件系统状态
块设备的 I/O 模型
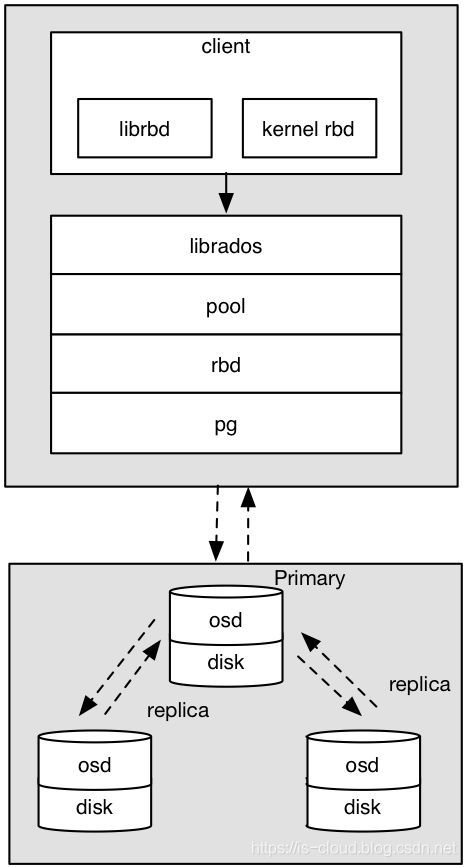
- 客户端应用 librbd 库创建一个块设备,并向块设备写入数据。
- 客户端应用 librbd 库调用 librados 库,经过 Pool、RBD(RBD 的专属 Pool)、Object、PG、OSDs 进行层层映射之后,得到 Primary OSD 的 IP:Port。
- 客户端与 Primary OSD 建立 Socket 通信,将要写入的数据直接传输给 Primary OSD,再由 Primary OSD 同步到 Replica OSDs 中。
RBD QoS
QoS(Quality of Service,服务质量)起源于网络技术,主要用于解决网络阻塞和延迟问题,能够为指定的网络通信提供更好的服务质量。在存储领域,集群的 IO 能力同样是有限的,比如:带宽,IOPS 等参数。如何避免用户之间争抢资源,保障高优用户的存储服务质量?就需要对有限的 IO 能力进行合理分配,这就是存储 QoS。而 RBD QoS 就是在 Ceph librbd 模块上实现的 QoS。
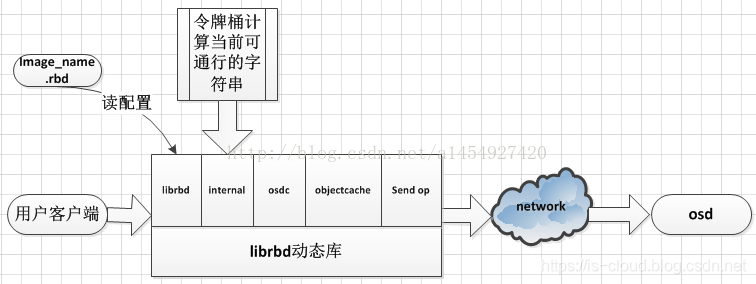
librbd 架构:
- librbd 接口层:读取配置,设置配置对象的 Watch 功能
- Internal:所有 librbd 接口读写的汇聚
- osdc:对用户数据流进行切片
- objectcache:用户数据缓冲层
- send op:数据操作发送层
RBD QoS 参数选项:
-
conf_rbd_qos_iops_limit 每秒 IO 限制
-
conf_rbd_qos_read_iops_limit 每秒读 IO 限制
-
conf_rbd_qos_write_iops_limit 每秒写 IO 限制
-
conf_rbd_qos_bps_limit 每秒带宽限制
-
conf_rbd_qos_read_bps_limit 每秒读带宽限制
-
conf_rbd_qos_write_bps_limit 每秒写带宽限制
Token bucket algorithm(令牌桶算法)
在当前版本(Mimic)中已经实现了基于令牌桶算法的 RBD QoS 功能,但暂时只支持 conf_rbd_qos_iops_limit 选项。
[root@ceph-node2 ~]# rbd create rbd_pool/volume01 --size 10240
[root@ceph-node2 ~]# rbd image-meta set rbd_pool/volume01 conf_rbd_qos_iops_limit 1000
[root@ceph-node2 ~]# rbd image-meta list rbd_pool/volume01
There is 1 metadatum on this image:
Key Value
conf_rbd_qos_iops_limit 1000
[root@ceph-node2 ~]# rbd image-meta set rbd_pool/volume01 conf_rbd_qos_bps_limit 2048000
failed to set metadata conf_rbd_qos_bps_limit of image : (2) No such file or directory
rbd: setting metadata failed: (2) No such file or directory
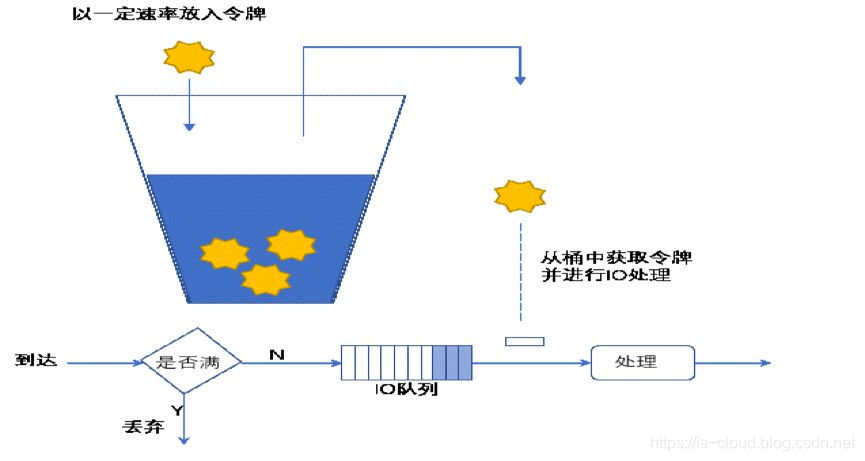
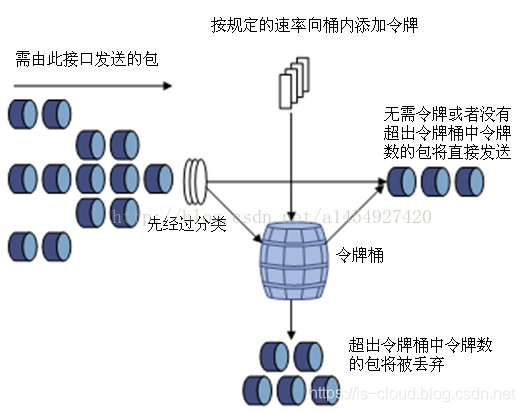
令牌桶算法的基本思想:
- 假如用户配置的平均发送速率为 R,则按照 1/R(s) 的速率令牌桶投放令牌;
- 假设令牌桶最多可以储存 N 个令牌,如果新添的令牌到达时令牌桶已经满了,那么这个令牌被丢弃;
- 根据预设的匹配规则先对报文进行分类,不符合匹配规则的报文不需要经过令牌桶的处理,直接发送;
- 反正,符合匹配规则的报文,则需要进行令牌桶处理。当一个 M 字节的数据包到达时,就从令牌桶中取走 M 个令牌,数据包持有令牌运行被发送到网络;
- 如果令牌桶中少于 M 个令牌,则该数据包不被发送。只有等到桶中投入了新的令牌,报文才可能被发送。这就可以限制报文的流量只能小于或等于令牌投入的速度,以此达到限制流量的目的。
令牌桶算法的 UML 流程:
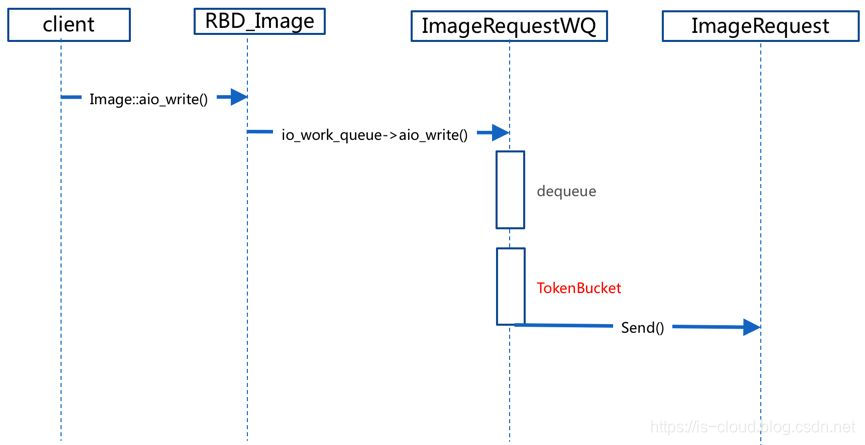
- 用户发起的请求异步 IO 到达 Image 中。
- 请求到达 ImageRequestWQ 队列中。
- 在 ImageRequestWQ 出队列的时候加入令牌桶算法 TokenBucket。
- 通过令牌桶算法进行限速,然后发送给 ImageRequest 进行处理。

dmClock algorithm
当前基于 dmClock 实现的 QoS 还在不断的提交 PR,很多尚未 Merge 到 Master,这里不多做讨论,有待继续跟进社区。
dmClock 是一种基于时间标签的 I/O 调度算法,最先被 VMware 提出用于集中式管理的存储系统。dmClock 可以将以下实体作为 QoS 对象:
- RBD Image
- Pool
- CephFS Directory
- Client 或者一组 Client
- 数据集
dmClock 主要通过 Reservation、Weight 和 Limit 来实现 QoS 控制:
- reservation:预留,表示客户端获得的最低 I/O 资源。
- weight:权重,表示客户端所占共享 I/O 资源的比重。
- limit:上限,表示客户端可获得的最高 I/O 资源。
块设备性能测试
使用 RADOS bench 进行基准测试
Ceph 提供了一个内置的基准测试程序 RADOS bench,它用于测试 Ceph 对象存储器的性能。
语法:
rados bench -p <pool_name> <seconds> <write|seq|rand>
- -p:指定 Pool
- Seconds:指定测试运行时长(s)
- write|seq|rand:指定测试类型,它应该是写、顺序读或者随机读
- -t:指定井发数,默认为 160
- –no-cleanup:指定 RODOS bench 写入到 Pool 的临时数据将不被删除,这些数据可用于读操作,默认为删除。
创建 Test Pool:
[root@ceph-node1 fio_tst]# ceph osd pool create test_pool 8 8
pool 'test_pool' created
[root@ceph-node1 fio_tst]# rados lspools
rbd_pool
.rgw.root
default.rgw.control
default.rgw.meta
default.rgw.log
test_pool
写入性能测试:
[root@ceph-node1 ~]# rados bench -p test_pool 10 write --no-cleanup
hints = 1
Maintaining 16 concurrent writes of 4194304 bytes to objects of size 4194304 for up to 10 seconds or 0 objects
Object prefix: benchmark_data_ceph-node1_34663
sec Cur ops started finished avg MB/s cur MB/s last lat(s) avg lat(s)
0 0 0 0 0 0 - 0
1 16 16 0 0 0 - 0
2 16 19 3 5.99838 6 1.66988 1.45496
3 16 25 9 11.997 24 2.99072 2.19588
4 16 32 16 15.996 28 3.33757 2.62036
5 16 39 23 18.3956 28 2.37105 2.54244
6 16 45 29 19.3289 24 2.65705 2.53162
7 16 52 36 20.5669 28 1.10485 2.51232
8 16 54 38 18.9957 8 3.27297 2.55235
9 16 67 51 22.6617 52 2.22446 2.57639
10 15 69 54 21.5954 12 2.41363 2.55092
11 2 69 67 24.3585 52 2.54614 2.54768
Total time run: 11.0136
Total writes made: 69
Write size: 4194304
Object size: 4194304
Bandwidth (MB/sec): 25.0599
Stddev Band 17.0752
Max bandwidth (MB/sec): 52
Min bandwidth (MB/sec): 0
Average IOPS: 6
Stddev IOPS: 4
Max IOPS: 13
Min IOPS: 0
Average Latency(s): 2.52608
Stddev Latency(s): 0.615785
Max latency(s): 4.03768
Min latency(s): 1.00465
- Average IOPS: 6
- Bandwidth (MB/sec): 25.0599
查看写入的临时数据:
[root@ceph-node1 ~]# rados ls -p test_pool
benchmark_data_ceph-node1_34663_object59
benchmark_data_ceph-node1_34663_object42
...
测试顺序读性能:
[root@ceph-node1 ~]# rados bench -p test_pool 10 seq
hints = 1
sec Cur ops started finished avg MB/s cur MB/s last lat(s) avg lat(s)
0 0 0 0 0 0 - 0
1 16 35 19 75.9741 76 0.323362 0.505157
2 16 59 43 85.9734 96 0.198388 0.543002
3 13 69 56 74.645 52 2.17551 0.543934
Total time run: 3.22507
Total reads made: 69
Read size: 4194304
Object size: 4194304
Bandwidth (MB/sec): 85.5795
Average IOPS: 21
Stddev IOPS: 5
Max IOPS: 24
Min IOPS: 13
Average Latency(s): 0.716294
Max latency(s): 2.17551
Min latency(s): 0.136899
- Average IOPS: 21
- Bandwidth (MB/sec): 85.5795
测试随机读性能:
[root@ceph-node1 ~]# rados bench -p test_pool 10 rand
hints = 1
sec Cur ops started finished avg MB/s cur MB/s last lat(s) avg lat(s)
0 0 0 0 0 0 - 0
1 16 108 92 367.61 368 0.0316746 0.119223
2 16 206 190 379.757 392 0.608621 0.145352
3 16 299 283 377.153 372 0.0378421 0.149943
4 15 368 353 352.859 280 0.6233 0.167492
5 16 473 457 365.474 416 0.66508 0.1645
6 16 563 547 364.547 360 0.00293503 0.166475
7 16 627 611 349.038 256 0.00289834 0.173168
8 16 748 732 365.897 484 0.0360462 0.168754
9 16 825 809 359.457 308 0.00331438 0.171356
10 16 896 880 351.908 284 0.75437 0.173779
Total time run: 10.3753
Total reads made: 897
Read size: 4194304
Object size: 4194304
Bandwidth (MB/sec): 345.821
Average IOPS: 86
Stddev IOPS: 17
Max IOPS: 121
Min IOPS: 64
Average Latency(s): 0.182936
Max latency(s): 1.06424
Min latency(s): 0.00266894
- Average IOPS: 86
- Bandwidth (MB/sec): 345.821
使用 fio 进行 IO 测试
fio 是一个第三方 IO 测试工具,在 Linux 系统上使用非常方便。fio 参数解析:
filename=/dev/emcpowerb 支持文件系统或者裸设备,-filename=/dev/sda2 或 -filename=/dev/sdb
direct=1 测试过程绕过机器自带的 Buffer,使测试结果更真实
rw=randwread 测试随机读的 I/O
rw=randwrite 测试随机写的 I/O
rw=randrw 测试随机混合写和读的 I/O
rw=read 测试顺序读的 I/O
rw=write 测试顺序写的 I/O
rw=rw 测试顺序混合写和读的 I/O
bs=4k 单次 IO 的块文件大小为 4k
bsrange=512-2048 同上,提定数据块的大小范围
size=5g 本次的测试文件大小为 5G,以每次 4k 的 IO 进行测试
numjobs=30 本次的测试线程为 30
runtime=1000 测试时间为 1000 秒,如果不写则一直将 5G 文件分 4k 每次写完为止
ioengine=psync IO 引擎使用 pync 方式,如果要使用 libaio 引擎,需要 yum install libaio-devel 包
rwmixwrite=30 在混合读写的模式下,写占 30%
group_reporting 关于显示结果的,汇总每个进程的信息
lockmem=1g 只使用 1G 内存进行测试
zero_buffers 用 0 初始化系统 Buffer
nrfiles=8 每个进程生成文件的数量
安装 fio 工具和 librbd 相关开发库(e.g. librbd-devel):
$ yum install -y fio "*librbd*"
创建测试块设备:
root@ceph-node1 ~]# rbd create rbd_pool/volume01 --size 10240
[root@ceph-node1 ~]# rbd ls rbd_pool
volume01
[root@ceph-node1 ~]# rbd info rbd_pool/volume01
rbd image 'volume01':
size 10 GiB in 2560 objects
order 22 (4 MiB objects)
id: 1229a6b8b4567
block_name_prefix: rbd_data.1229a6b8b4567
format: 2
features: layering
op_features:
flags:
create_timestamp: Thu Apr 25 00:11:20 2019
编辑测试参数配置:
$ mkdir /root/fio_tst && cd /root/fio_tst
$ cat write.fio
[global]
description="write test with block size of 4M"
direct=1
ioengine=rbd
clustername=ceph
clientname=admin
pool=rbd_pool
rbdname=volume01
iodepth=32
runtime=300
rw=randrw
numjobs=1
bs=8k
[logging]
write_iops_log=write_iops_log
write_bw_log=write_bw_log
write_lat_log=write_lat_log
执行 IO 测试:
[root@ceph-node1 fio_tst]# fio write.fio
logging: (g=0): rw=randrw, bs=(R) 8192B-8192B, (W) 8192B-8192B, (T) 8192B-8192B, ioengine=rbd, iodepth=32
fio-3.1
Starting 1 process
Jobs: 1 (f=1): [m(1)][100.0%][r=392KiB/s,w=280KiB/s][r=49,w=35 IOPS][eta 00m:00s]
logging: (groupid=0, jobs=1): err= 0: pid=34842: Thu Apr 25 02:41:25 2019
Description : ["write test with block size of 4M"]
read: IOPS=120, BW=965KiB/s (988kB/s)(283MiB/300063msec)
slat (nsec): min=734, max=688371, avg=4864.30, stdev=11806.74
clat (usec): min=771, max=1638.5k, avg=112142.48, stdev=118607.44
lat (usec): min=773, max=1638.5k, avg=112147.35, stdev=118607.37
clat percentiles (msec):
| 1.00th=[ 3], 5.00th=[ 5], 10.00th=[ 7], 20.00th=[ 20],
| 30.00th=[ 31], 40.00th=[ 48], 50.00th=[ 71], 60.00th=[ 107],
| 70.00th=[ 144], 80.00th=[ 192], 90.00th=[ 268], 95.00th=[ 342],
| 99.00th=[ 523], 99.50th=[ 617], 99.90th=[ 827], 99.95th=[ 894],
| 99.99th=[ 1133]
bw ( KiB/s): min= 4, max=10622, per=41.55%, avg=400.92, stdev=773.36, samples=36196
iops : min= 1, max= 1, avg= 1.00, stdev= 0.00, samples=36196
write: IOPS=120, BW=966KiB/s (990kB/s)(283MiB/300063msec)
slat (usec): min=2, max=1411, avg=18.63, stdev=31.60
clat (msec): min=4, max=2301, avg=152.15, stdev=137.61
lat (msec): min=4, max=2301, avg=152.17, stdev=137.61
clat percentiles (msec):
| 1.00th=[ 11], 5.00th=[ 18], 10.00th=[ 24], 20.00th=[ 40],
| 30.00th=[ 61], 40.00th=[ 86], 50.00th=[ 116], 60.00th=[ 150],
| 70.00th=[ 192], 80.00th=[ 245], 90.00th=[ 326], 95.00th=[ 405],
| 99.00th=[ 609], 99.50th=[ 735], 99.90th=[ 961], 99.95th=[ 1133],
| 99.99th=[ 2198]
bw ( KiB/s): min= 3, max= 1974, per=14.09%, avg=136.11, stdev=164.08, samples=36248
iops : min= 1, max= 1, avg= 1.00, stdev= 0.00, samples=36248
lat (usec) : 1000=0.01%
lat (msec) : 2=0.39%, 4=1.87%, 10=4.40%, 20=7.39%, 50=19.19%
lat (msec) : 100=18.12%, 250=33.10%, 500=13.85%, 750=1.35%, 1000=0.28%
lat (msec) : 2000=0.05%, >=2000=0.01%
cpu : usr=0.33%, sys=0.12%, ctx=5983, majf=0, minf=30967
IO depths : 1=0.6%, 2=1.7%, 4=5.4%, 8=17.9%, 16=68.3%, 32=6.1%, >=64=0.0%
submit : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0%
complete : 0=0.0%, 4=95.2%, 8=0.7%, 16=1.3%, 32=2.8%, 64=0.0%, >=64=0.0%
issued rwt: total=36196,36248,0, short=0,0,0, dropped=0,0,0
latency : target=0, window=0, percentile=100.00%, depth=32
Run status group 0 (all jobs):
READ: bw=965KiB/s (988kB/s), 965KiB/s-965KiB/s (988kB/s-988kB/s), io=283MiB (297MB), run=300063-300063msec
WRITE: bw=966KiB/s (990kB/s), 966KiB/s-966KiB/s (990kB/s-990kB/s), io=283MiB (297MB), run=300063-300063msec
Disk stats (read/write):
dm-0: ios=0/1336, merge=0/0, ticks=0/42239, in_queue=45656, util=1.33%, aggrios=0/1356, aggrmerge=0/87, aggrticks=0/46003, aggrin_queue=46002, aggrutil=1.39%
sda: ios=0/1356, merge=0/87, ticks=0/46003, in_queue=46002, util=1.39%
- read: IOPS=120, BW=965KiB/s (988kB/s)(283MiB/300063msec)
- write: IOPS=120, BW=966KiB/s (990kB/s)(283MiB/300063msec)
输出结果参数解析:
io 执行了多少(M)IO
bw 平均 IO 带宽
iops IOPS
runt 线程运行时间
slat 提交延迟
clat 完成延迟
lat 响应时间
cpu 利用率
IO depths IO 队列
IO submit 单个 IO 提交要提交的 IO 数
IO complete Like the above submit number, but for completions instead.
IO issued The number of read/write requests issued, and how many of them were short.
IO latencies IO 完延迟的分布
aggrb Group 总带宽
minb 最小平均带宽.
maxb 最大平均带宽.
mint Group 中线程的最短运行时间.
maxt Group中线程的最长运行时间.
ios 所有Group总共执行的IO数.
merge 总共发生的 IO 合并数.
ticks Number of ticks we kept the disk busy.
io_queue 花费在队列上的总共时间.
util 磁盘利用率
对块设备的 IOPS 执行 QoS:
[root@ceph-node1 fio_tst]# rbd image-meta set rbd_pool/volume01 conf_rbd_qos_iops_limit 50
[root@ceph-node1 fio_tst]# rbd image-meta list rbd_pool/volume01
There is 1 metadatum on this image:
Key Value
conf_rbd_qos_iops_limit 50
再次执行 IO 测试:
[root@ceph-node1 fio_tst]# fio write.fio
logging: (g=0): rw=randrw, bs=(R) 8192B-8192B, (W) 8192B-8192B, (T) 8192B-8192B, ioengine=rbd, iodepth=32
fio-3.1
Starting 1 process
Jobs: 1 (f=1): [f(1)][100.0%][r=56KiB/s,w=200KiB/s][r=7,w=25 IOPS][eta 00m:00s]
logging: (groupid=0, jobs=1): err= 0: pid=35040: Thu Apr 25 02:50:54 2019
Description : ["write test with block size of 4M"]
read: IOPS=24, BW=199KiB/s (204kB/s)(58.5MiB/300832msec)
slat (nsec): min=807, max=753733, avg=4863.82, stdev=16831.94
clat (usec): min=1311, max=1984.2k, avg=482448.41, stdev=481601.17
lat (usec): min=1313, max=1984.2k, avg=482453.27, stdev=481601.01
clat percentiles (msec):
| 1.00th=[ 4], 5.00th=[ 5], 10.00th=[ 6], 20.00th=[ 8],
| 30.00th=[ 14], 40.00th=[ 23], 50.00th=[ 71], 60.00th=[ 969],
| 70.00th=[ 978], 80.00th=[ 986], 90.00th=[ 995], 95.00th=[ 995],
| 99.00th=[ 1003], 99.50th=[ 1011], 99.90th=[ 1036], 99.95th=[ 1938],
| 99.99th=[ 1989]
bw ( KiB/s): min= 4, max= 6247, per=100.00%, avg=486.86, stdev=666.26, samples=7483
iops : min= 1, max= 1, avg= 1.00, stdev= 0.00, samples=7483
write: IOPS=25, BW=200KiB/s (205kB/s)(58.8MiB/300832msec)
slat (usec): min=3, max=1427, avg=19.40, stdev=33.29
clat (msec): min=6, max=1998, avg=799.32, stdev=501.54
lat (msec): min=6, max=1998, avg=799.34, stdev=501.54
clat percentiles (msec):
| 1.00th=[ 13], 5.00th=[ 16], 10.00th=[ 20], 20.00th=[ 34],
| 30.00th=[ 961], 40.00th=[ 986], 50.00th=[ 995], 60.00th=[ 995],
| 70.00th=[ 995], 80.00th=[ 1003], 90.00th=[ 1011], 95.00th=[ 1938],
| 99.00th=[ 1989], 99.50th=[ 1989], 99.90th=[ 1989], 99.95th=[ 1989],
| 99.99th=[ 2005]
bw ( KiB/s): min= 4, max= 1335, per=50.98%, avg=101.96, stdev=184.46, samples=7522
iops : min= 1, max= 1, avg= 1.00, stdev= 0.00, samples=7522
lat (msec) : 2=0.04%, 4=1.27%, 10=11.24%, 20=11.63%, 50=11.50%
lat (msec) : 100=2.03%, 250=0.63%, 500=0.27%, 750=0.34%, 1000=48.66%
lat (msec) : 2000=12.41%
cpu : usr=0.06%, sys=0.03%, ctx=1118, majf=0, minf=10355
IO depths : 1=0.9%, 2=2.7%, 4=7.9%, 8=22.2%, 16=61.5%, 32=4.8%, >=64=0.0%
submit : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0%
complete : 0=0.0%, 4=96.0%, 8=0.2%, 16=0.6%, 32=3.1%, 64=0.0%, >=64=0.0%
issued rwt: total=7483,7522,0, short=0,0,0, dropped=0,0,0
latency : target=0, window=0, percentile=100.00%, depth=32
Run status group 0 (all jobs):
READ: bw=199KiB/s (204kB/s), 199KiB/s-199KiB/s (204kB/s-204kB/s), io=58.5MiB (61.3MB), run=300832-300832msec
WRITE: bw=200KiB/s (205kB/s), 200KiB/s-200KiB/s (205kB/s-205kB/s), io=58.8MiB (61.6MB), run=300832-300832msec
Disk stats (read/write):
dm-0: ios=11/1599, merge=0/0, ticks=68/19331, in_queue=19399, util=0.92%, aggrios=11/1555, aggrmerge=0/46, aggrticks=68/19228, aggrin_queue=19295, aggrutil=0.92%
sda: ios=11/1555, merge=0/46, ticks=68/19228, in_queue=19295, util=0.92%
- read: IOPS=24, BW=199KiB/s (204kB/s)(58.5MiB/300832msec)
- write: IOPS=25, BW=200KiB/s (205kB/s)(58.8MiB/300832msec)
从结果来看 RBD QoS 的效果是还可以的。