目录
消息队列
消息队列(Message Queue,MQ)是大型分布式系统中不可或缺的重要组成部分,主要解决了 应用解耦,异步处理,流量削峰,消息通讯 等问题,支撑实现分布式系统的高并发,高性能,高可用,可伸缩和最终一致性。目前在生产环境中使用较多的消息队列有 ActiveMQ,RabbitMQ,ZeroMQ,Kafka,MetaMQ,RocketMQ 等。
消息队列一般会以中间件的形式存在于分布式系统中,所以也会被称为消息队列中间件。顾名思义,就是将存放消息的队列作为系统组件间通讯的中间件。队列是一种数据结构,具有 FIFO(First In First Out) 的特征,通过队列能够有效将消息的发送和接收分离,以此来解耦不同的功能模块,并同时支持异步处理。实际上异步和解耦只是应用了 MQ 所表现出来的效果,并非是 MQ 所存在的目的。MQ 最初的目的是为了解决通讯问题。
我们都知道在分布式系统中的两个组件之间的通讯,要么使用 HTTP,要么使用自己开发的 TCP,但实际上这两种协议都是比较原始的协议,过于底层,无法为上层应用程序提供更加具体的、贴近需求的功能。例如:HTTP 想要实现两端双工通讯,就需要两端都提供 WebServer,而且 HTTP 不支持长连接;TCP 就更加底层了,往往需要自己开发 Socket 连接,连带的还需要解决粘包、心跳机制、定义私有协议等问题。由此可见,在使用 HTTP 和 TCP 协议作为通讯支撑时,就要开发者做大量重复的工作来保证通讯稳定。
秉承 DRY(Don’t repeat yourself) 原则,MQ 解决的思路就是直接将底层通讯协议屏蔽,在 HTTP、TCP 协议之上定义出应用层的统一通讯模型——「生产者/消费者通讯模型」。需要注意的是,这里所说的通讯模型而非经常听说的生产者/消费者设计模式,前者是解决方案的描述,后者是解决方案具体的实现方式。之所以提到这里,是为了强调 MQ 定义的仅是一个通讯模型,具体如何实现生产者/消费者功能模块依旧是开发者的工作。
我们知道编写高质量代码逻辑需要遵守高内聚、松耦合原则,这样能够有效保证应用程序具有良好的可读、可维护和可扩展性。分布式系统将这一理念从代码级别提高到了系统组件级别,其设计的初衷为了解决软件架构的可伸缩性和高并发性能问题。系统中的每个组件既可以是生产者又可以是消费者,彼此之间通过 MQ 来进行通信,生产者只管生成消息并发送给 MQ,消费者只管从 MQ 中接收消息。MQ 成为了消息的中转站,从而有效的将两者分离。同时 MQ 也相当于缓冲区,平衡了生产者和消费者的处理能力,整体提高了系统处理数据的速度。当然了,MQ 只是解耦的方案之一,解耦也只是 MQ 的应用场景之一。
消息队列的种类
MQ 一般被分为两大类,通过是否需要 Broker 来区分:
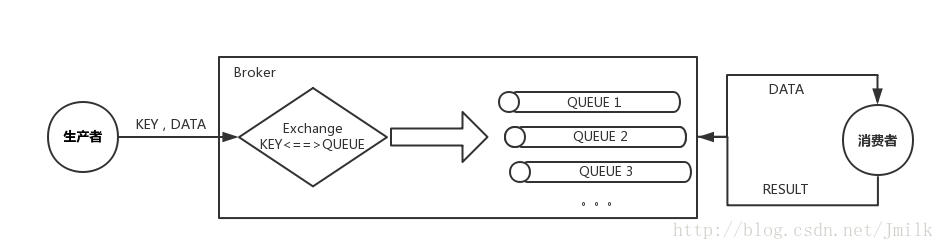
有 Broker:此类型 MQ 有专门的 Broker 中间件,所有消息都经由 Broker 代理中转,具有非常强的灵活性,典型代表有 RabbitMQ。
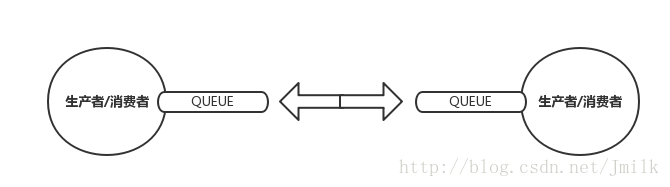
无 Broker:这一类 MQ 不需要专门的 Broker,通讯节点既是生产者,又是消费者,典型代表为 ZeroMQ。ZeroMQ 被设计成了库而非中间件,它封装了 Socket API 用于完成数据的发送和读取,所以 ZeroMQ 看起来更像是一种高级的 Socket,更加侧重于解决通讯的问题。