谷歌论文题目:
MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications
其他参考:
Tensorflow实现参考:
前言:
目前,CNN以及其他神经网络正在飞速发展与应用,为了追求高准确率,网络模型的深度和复杂度越来越大。然而在某些真实的应用场景如移动或者嵌入式设备上,如此大而复杂的模型难以应用。
首先,模型过于庞大,面临着内存不足的问题;
其次,一些场景要求低延迟或者说响应速度要快(自动驾驶中的行人检测)。
因此,研究小而高效的CNN模型至关重要。
目前针对此类问题的研究,主要集中在两个方面:
1、对训练好的模型进行压缩得到小的模型。
2、直接设计小的模型。
总的来说,都是在保持模型的性能的前提下,降低模型大小,提升模型速度。
而谷歌提出的MobileNet就是一种直接设计的小模型,它是在accuracy(准确率)和latency(延迟)中折中的一种方法。
图1.MobileNet模型可以高效的应用到智能设备的识别任务中去
Depthwise Separable Convolution(深度级可分离卷积,DSC):
MobileNet与CNN的不同在于它的基本单元是DSC,即深度级可分离卷积。
深度级可分离卷积是一种可分解卷积操作,它可分解为两个更小的操作:depthwise Convolution和pointwise Convolution。
对于标准卷积,其卷积核是用在所有的输入通道上,而depthwise Convolution针对每个输入通道采用不同的卷积核,就是说一个卷积核对应一个输入通道,所以说depthwise Convolution是depth级别的操作。而pointwise Convolution其实就是普通的卷积,只不过采用的是1*1的卷积核。
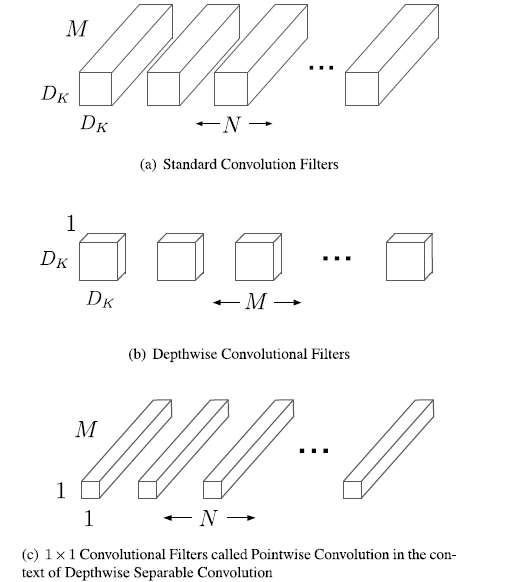
图2.标准卷积滤波器被深度级卷积和1*1卷积替代用来构建深度级可分离卷积
对于DSC,其首先采用depthwise Conv对不同输入通道分别进行卷积,然后采用pointwise Conv将上面的输出再进行结合,其效果与一个标准卷积差不多,但是会大大减少计算量和模型参数量。
采用depthwise Conv会有一个问题,就是会导致信息流通不畅,即输出的feature Map仅包含输入的feature Map的一部分,在这里,MobileNet采用了pointwise Conv解决这个问题。后来的ShuffleNet采用同样的思想对网络进行改进,只不过将pointwise Conv换成了channel Shuffle。
下面,对DSC在计算量上与标准卷积的区别进行说明:
假设输入特征图:Df*Df*M;输出特征图:Df*Df*N,M、N是通道数(channel或者depth),这里假定了输入和输出特征图的大小(width and height)是一致的。采用的卷积核:Dk*Dk。
对于标准的卷积,其计算量为:Dk*Dk*M*N*Df*Df
对于depthwise Conv:Dk*Dk*M*Df*Df
对于pointwise Conv:M*N*Df*Df
从而总的DSC的计算量为:Dk*Dk*M*Df*Df+M*N*Df*Df
进而得到depthwise Conv/CNN = (Dk*Dk*M*Df*Df+M*N*Df*Df)/(Dk*Dk*M*N*Df*Df) = 1/N + 1/Dk^2
从上面可以看出,如果采用3*3的卷积核,DSC可将原来的计算量将至1/9。
MobileNet 的一般结构:
MobileNet的基本结构和网络结构可以从下面的图表中进行了解,网络结构是针对谷歌论文中的识别任务构建的,可以对其进行修改。
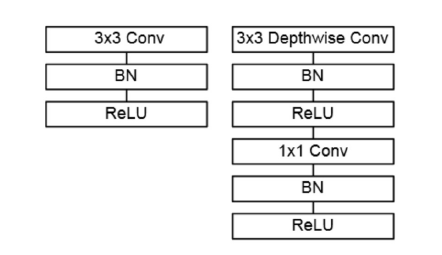
图3.带有BN和ReLU的标准卷积层与DSC
表1.MobileNet的网络结构
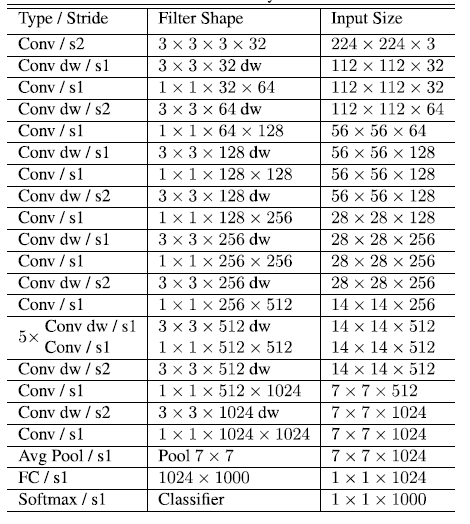
表2.MobileNet网络的计算与参数分布
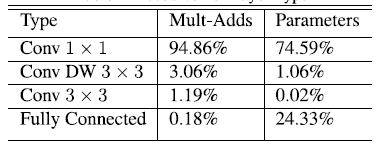
从上面可以看出MobileNet的计算主要集中在1*1的卷积中,约占95%,拥有着75%的参数。另一个主要的参数分布在全连接层。卷积一般通过一种im2col的方式实现,其需要内存重组,但当卷积核为1*1时,其实就不需要这种操作了,底层就可以有更快的实现。
MobileNet瘦身:
之前提到的是MobileNet的基准模型,有时候需要对MobileNet瘦身,这个时候就需要引入两个超参数:width multiplier(宽度乘数)和 resolution multiplier(分辨率乘数)。
对于宽度乘数a:
1、其是按比例减少通道数。
2、取值范围(0,1]。
3、引入宽度乘数后,计算量变成:Dk*Dk*a*M*Df*Df+a*M*a*N*Df*Df。
4、由于主要计算量在后一项,所以width multiplier可以按照a^2的比例降低计算量,其参数量也会下降。
对于分辨率乘数p:
1、按比例降低特征图的大小。
2、在引入宽度乘数和分辨率乘数之后,计算量变成:Dk*Dk*a*M*p*Df*p*Df+a*M*a*N*p*Df*p*Df。
3、分辨率乘数仅影响计算量,不改变参数量。
论文中对引入两个超参数之后的效果进行了比较,具体如下:
表3.使用超参数之后的性能对比
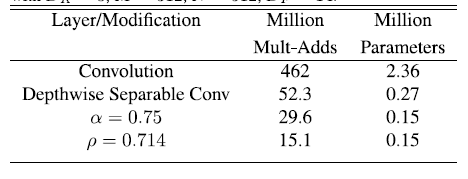
表4.MobileNet的宽度乘数对网络的影响
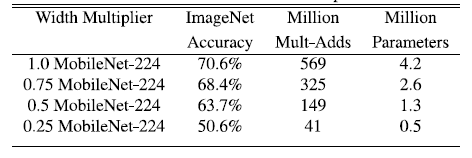
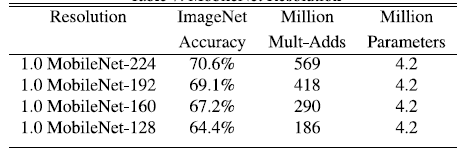
表5.MobielNet的分辨率乘数对网络的影响
总的来说,引入的两个参数会降低MobileNet网络的性能,具体实验分析可以查阅论文。其是在accuracy 和 computation,以及accuracy 和 model Size 之间做了这种。论文的最后还使用该网络进行了COCO data等数据集的验证,具体请下载论文阅读。