冒泡排序
冒泡排序介绍
冒泡排序(Bubble Sort),是一种计算机科学领域的较简单的排序算法。
它重复地走访过要排序的元素列,依次比较两个相邻的元素,如果顺序(如从大到小、首字母从Z到A)错误就把
他们交换过来。走访元素的工作是重复地进行直到没有相邻元素需要交换,也就是说该元素列已经排序完成。
这个算法的名字由来是因为越小的元素会经由交换慢慢“浮”到数列的顶端(升序或降序排列),就如同碳酸饮料中
二氧化碳的气泡最终会上浮到顶端一样,故名“冒泡排序”。
冒泡排序的算法原理
冒泡排序算法的原理如下:
比较相邻的元素。如果第一个比第二个大,就交换他们两个。
对每一对相邻元素做同样的工作,从开始第一对到结尾的最后一对。在这一点,最后的元素应该会是最大的数。
针对所有的元素重复以上的步骤,除了最后一个。
持续每次对越来越少的元素重复上面的步骤,直到没有任何一对数字需要比较。
算法描述
ef bubble_sort(nums):
for i in range(len(nums) - 1): # 这个循环负责设置冒泡排序进行的次数
for j in range(len(nums) - i - 1): # j为列表下标
if nums[j] > nums[j + 1]:
nums[j], nums[j + 1] = nums[j + 1], nums[j]
return nums
print(bubble_sort([45, 32, 8, 33, 12, 22, 19, 97]))
# 输出:[8, 12, 19, 22, 32, 33, 45, 97]
画图详细介绍(来自摘抄)
什么是冒泡排序呢?冒泡排序的英语名是Bubble Sort,是一种最基础的交换排序。
大家一定都喝过汽水吧,汽水中常常有许多小小的气泡,往上飘,这是因为组成小气泡的二氧化碳比水要轻,所
以小气泡才会一点一点的向上浮。而冒泡排序之所以叫冒泡排序,正是因为这种排序算法的每一个元素都可以向小
气泡一样,根据自身大小,一点一点向着数组的一侧移动。具体如何移动呢?我们来看一下例子:

有8个数组组成一个无序数列:5,8,6,3,9,2,1,7,希望从大到小排序。按照冒泡排序的思想,我们要把相邻的元素两
两进行比较,根据大小交换元素的位置,过程如下:
第一轮排序:
1、首先让5和8进行交换,发现5比8小,因此元素位置不变。
2、接下来让8和6比较,发现8比6大,所以要交换8和6的位置。
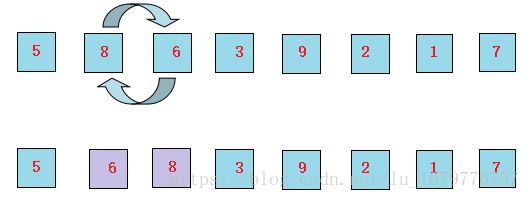
3、继续让8和3比较,发现8比3要大,所以8和3 交换位置。

4、继续让8和9进行比较,发现8比9小,不用交换
5、9和2进行比较,发现9比2大,进行交换

6、继续让9和1进行比较,发现9比1大,所以交换9和1的位置。
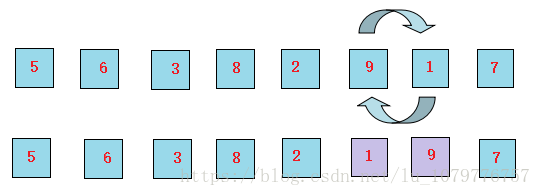
7、最后,让9和7交换位置

这样一来,元素9作为数列的最大元素,就已经排序好了。

下面我们来进行第二轮排序:
1、首先让5和6比较,发现5比6小,位置不变
2、接下来让6和3比较,发现6比3大,交换位置
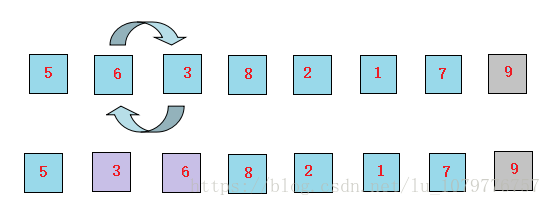
3、接下来让6和8比较,6比8小,位置不变
4、8和2比较。8比2大,交换位置
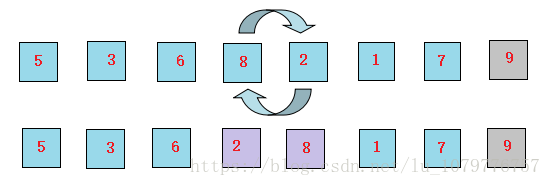
5、接下来让8和1比较,8比1大,因此交换位置

6、继续让8和7比较,发现8比7大,交换位置
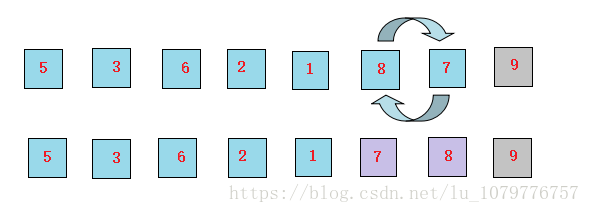
第二轮的状态为:

第三轮的状态为:

第四轮的状态为:

第五轮的状态为:

第六轮的状态:

第七轮状态为:(已经有序了)

第八轮的状态为:

到此为止,所有的元素欧式有序的了,这就是冒泡排序的整体思路。
原始的冒泡排序是稳定的,由于该排序算法的每一轮都要遍历一遍所有的元素,轮转的次数和元素数量相当,所以时间复杂度为O(N^2)。
原文链接:https://blog.csdn.net/lu_1079776757/article/details/80459370
冒泡排序就是一个双次遍历,循环将左右俩个数值的大小交换位置,从而实现一轮轮的将最大的数值冒到最上面
第一次遍历为要交换的次数,第二次遍历为比较大小和互换数值位置.
案例: 不允许用Python内置的排序方法实现对列表排序
# 题目要求:不允许用Python内置的排序方法实现对列表排序
lis_1 = [3, 7, 8, 9, 12, 100, 400, 540, 30, 4, 2, 1, 2, 9, 12]
lis_2 = [5, 6, 10, 13, 25, 30, 350, 340, 200, 130, 7, 8, 6, 5]
# 排序结果:[1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 12, 13, 25, 30, 100, 130, 200, 340, 350, 400, 540]
# 使用内置方法min()删除和添加方法
def func(l1, l2):
l = list(set(l1 + l2))
new_l = []
for i in range(len(l)):
new_l.append(min(l))
l.remove(min(l))
return new_l
# 使用冒泡排序
def bubble_sort(nums):
for i in range(len(nums)): # 这个循环负责设置冒泡排序进行的次数
for j in range(len(nums) - 1): # j为列表的下标
if nums[j] > nums[j + 1]:
nums[j], nums[j + 1] = nums[j + 1], nums[j] # 将小的排到前面,大的继续往后比较
return nums # 此时的nums已经排好序.
print(bubble_sort(list(set(lis_1 + lis_2))))