消费者拉取消息
消费者创建拉取请求的准备工作,和生产者创建生产请求的准备工作类似,它们都必须和分区的主副本交互。一个生产者写入的分区和消费者分配的分区都可能有多个,
同时多个分区的主副本有可能在同一个节点上 。 为了减少客户端和服务端集群的网络连接,客户端并不是以分区为粒度和服务端交互,而是以服务端节点为粒度 。
如果分区的主副本在同一个节点上,应当在客户端先把数据按照节点整理好,把属于同一个节点的多个分区作为一个请求发送出去 。 一个消费者可以允许同时向多个主
副本节点发送请求,这个请求包括属于这个主副本节点的多个分区 。
创建拉取请求的一个重要数据,是需要指定从分区的什么位置开始拉取。 消费者的订阅状态中保存了分配给消费者所有分区的状态信息,其中就包括拉取偏移量( position变量)。
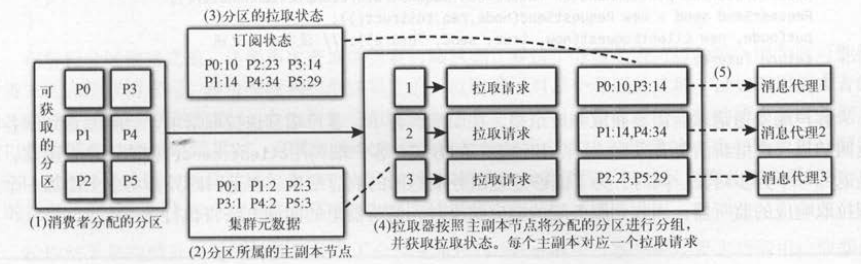
如下图所示,从消费者分配分区开始,结合使用集群的元数据( Cluster)和消费者的订阅状态( SubscriptionState ),
向每个目标节点发送拉取请求,具体步骤如下 。
( 1) 消费者向协调者申请加入消费组,并得到分配给它的分区 。
( 2) 集群的元数据记录了分区及其所属主副本节点的信息 。
( 3) 消费者的订阅状态记录了分区及其最近拉取偏移量的信息 。
( 4) 拉取器工作时,会将所有的分区按照主副本节点整理 。
( 5) 每个主副本对应一个拉取请求,消费者向服务端节点发送拉取请求 。
1 发送拉取请求
拉取器的准备工作做好后,接着通过消费者网络客户端( ConsumerNetworkClient )将请求发送出去 。 调用send ()方法实际上并不会将请求通过
网络发送到服务端 , 只有等到轮询的时候才会真正发送出去 。 这也是消费者轮询时在发送请求后,需要调用客户端轮询方法的原因 。
拉取器的发送拉取请求方法还添加了一个监听器 , 它的作用类似于“轮询与结果”中的回调对象 。 当客户端轮询到拉取请求对应的响应结果,
便会调用这个监听器的回调方法 , 来处理响应结果。 下面3段代码是Kafka消费者、拉取器、消费者网络客户端完成发送拉取请求调用逻辑的过程。
客户端发送请求后需要获取响应结果,在旧消费者中,客户端发送拉取请求, 会阻塞直到服务端返回结果 。 这里新消费者采用“异步和轮询” 的方式 :
客户端调用client.send ()方法不会被阻塞 ,而是返回一个异步对象。 同时 ,为了能够处理服务端返回的响应结果,在返回的异步对象上添加一个处
理拉取响应的监听器,当收到服务端的响应结果时,监昕器里的回调方法将执行。
2 . 处理拉取响应
客户端发到指定服务端节点的拉取请求可能包括多个分区,所以拉取请求对应的响应结果也包含了多个分区的数据。 拉取请求对象( FetchRequest )
的分区数据表示客户端从分区的哪个位置开始拉取,拉取响应对象( FetchResponse ) 的分区数据表示服务端返回了哪些消息 。
监听器调用的处理拉取响应方法( handleFetchResponse() ),会将每个分区数据的字节数组记录集( recordSet ),转换成一条条可以被消费者
直接读取的消费者记录 ( ConsumerRecord ),并添加到拉取器的 this.records全局成员变量中 。 由于响应结果已经按照分区组织好了,所以拉取器构
造的分区记录集( PartitionRecords ) 也是每个分区对应一批拉取结果 。
在解析分区数据之前,还要再次查询消费者订阅状态,看这个分区是否可以拉取 。 因为有可能消费者发送完拉取请求后,在没有收到拉取结果之前,
就取消了对某个分区的拉取( 比如调用消费者的pause ()方法暂停分区的拉取)。 由于服务端无法感知这个动作,它还是会返回之前的所有分区数据 。
所以拉取器在处理拉煎结果时,还需要再次判断分区数据是不是客户端想要的 。 比如消费者分配了[P0, P1, P2 ]这 3个分区,然后发送包含这 3个分区
的拉取请求,接着暂停了 P1 分区 。 服务端会返回 3个分区的数据,但是实际上客户端现在只需要 [P0, P2]两个分区 。
拉取结果集按照分区进行封装后放在了全局变量this.records 中,客户端还要主动调用拉取器的fetchedRecords ()方法才能获取到拉取结果 。
虽然客户端轮询、异步请求对象、回调方法这些组合都是异步的,但是为了获取消息 ,消费者必须主动调用,而不能被动获取结果 。 这也是客户端主
动拉取消息,而不是服务端推送消息给客户端的体现。
消费者获取记录
拉取器处理拉取响应时已经将原始的响应数据封装成了分区记录集,并放到全局的成员变量this.records 中 。 但要真正被消费者可用,还需要封装成
消费者记录( ConsumerRecord )。拉取器的获取记录集生成的全局成员变量,作为数据源构成最终的拉取结果。 既然数据已经在全局成员变量中了,
那么要提供给客户端使用,就可以直接返回 。 但实际上拉取器在这一步还做了下面几点优化 。
- 一次轮询发送两次拉取请求 , 必须确保第一个请求获取到结果后,才允许发送第二个请求 。
- 全局的 this.records成员变量不会同时存放两个请求的拉取结果 。
- 客户端轮询时可以设置每个分区的拉取阔值和最大记录数,防止客户端处理不了 。
- 如果分区的记录集没有被客户端处理完,新的拉取请求不会拉取这个分区 。
1. 保存每次拉取结果的全局成员变量
拉取器的 this.records也是个全局变量 , 在客户端的一次轮询里会发送两次拉取请求 。 虽然第二次发送请求后是无阻塞的快速轮询, 但第二次的
请求也可能立即产生结果。而每个拉取请求的回调方法都会将自己请求的拉取结果添加到全局变量中 。 为了保证同一次轮询里两个拉取请求的结果数据不会
互相混淆,必须确保第一个请求获取到结果后,才允许发送第二个请求 。
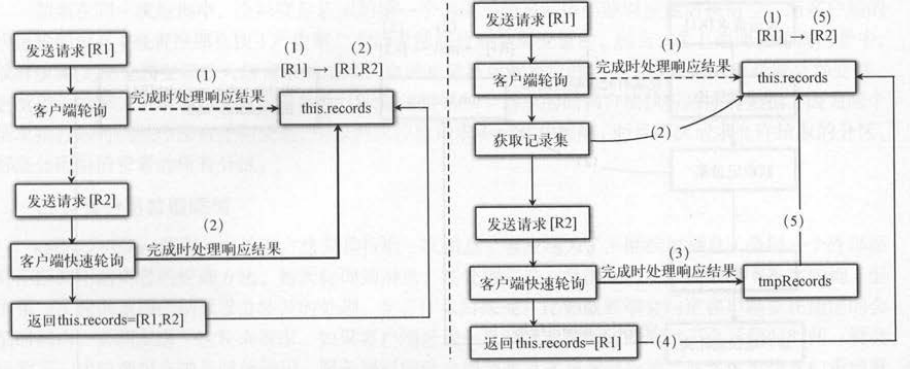
如下图(左)所示,如果没有获取到第一个请求的结果就发送第二个请求,快速轮询返回的结果也会放到全局变量中 。
最后客户端获取的全局变量包括了两个请求的结果,显然有问题。 如图 (右)所示,快速轮询的第二个请求结果会先用临时变量保存。 当第一个请求
的结果返回给客户端时,会将临时变量赋值给全局变量 , 第二种方案的具体步骤如下 。
(1) 拉取器发送第一个请求,并轮询得到结果 , 放入全局变量中 。
(2) 拉取器获得第一个请求的记录集 。
(3) 拉取器发送第二个请求,并快速轮询得到结果,暂存到临时变量 。
(4) 将步骤 ( 1)生成的全局变量返回给客户端 。
(5 ) 将步骤(3)暂存的临 时变量赋值给全局变量,用于下一次的轮询 。
上面第二种做法虽然保证了返回结果的准确性,但是在具体的实现上一旦返回结果给客户端,就不好做步骤(5)的控制。一种更好的办法是用一个临时变量( drained )
来保存第一个请求的结果,返回给客户端的结果也是这个临时变量 。 实际上, 发送拉取请求 → 处理拉取结果 → 添加到全局变量→
将全局变量赋值给临时变量→ 清空全局变量,这几步是严格有序的,下一个请求只能接着上一个请求的最后一步“清空全局变量”开始执行。
第一个请求的临时变量肯定不会包含第二个请求的拉取结果:在生成第一个请求的临时变量时,第二个请求根本就还没有机会执行 ; 而第二个请求开始执行时,第
一个请求的临时变量已经尘埃落定,不会再被更改了 。 所以用临时变量作为第一个请求的拉取结果返回值是没有问题的 。
如下图所示,还可以将步骤(5)提前到步骤(4)之前,并且将步骤(3)和步骤(5)进行合并 : 即不需要再用一个中间变量( tmpRecords ),
而是直接更新全局变量 。虽然步骤(3)中将临时变量赋值给全局变量会更新全局变量的值,但是因为最后要返回给客户端的并不是这个全局变量,而是临时变量,所
以结果仍然是准确的 。 以第一次轮询为例,全局变量和临时变量的变化步骤如下 。
(1)拉取器发送第一个请求,并轮询得到结果,放入全局变量中 。
(2)拉取器获得第一个请求的记录集,将全局变量赋值给临时变量,并清空全局变量 。
(3)拉取器发送第二个请求,并快速轮询得到结果,也放入全局变量中 。
(4)拉取器获取步骤(2)的临时变量作为返回值 。

2. 设置分区拉取阈值
KafkaConsumer用一次轮询方法只是拉取一次消息 。 客户端为了不断拉取消息,会用一个外部循环不断调用消费者的轮询方法 。 每次轮询到消息,在处理完这一批消息后,
才会继续下一次轮询 。 但如果一次轮询返回的结果没办法及时处理,会有什么后果呢?比如服务端会约定客户端要在指定的会话时间内,必须发送一次轮询请求 。
如果客户端处理一批消息花费的时间超过了会话超时时间,就会导致下一次轮询没有被及时地调用,服务端可能就会把消费者客户端移除掉,显然这不是我们希望看
到的 。
那么有什么办法来解决上面的问题呢?客户端拉取消息时有下面两个相关的配置项 。
- 消息大小阈值( Message.Max.bytes 。服务端允许接收一条消息的最大字节 , 超过这个大小的消息不会被服务端接受,默认值为 1000012 ( 976 KB ) 。
- 分区拉取阔值( Max.partition.fetch.bytes )。 客户端拉取每个分区的消息时 , 返回的每个分区最大字节,默认值为 1048576 ( 1 MB ) 。
注意,分区拉取阔值必须比消息大小阔值大 。 如下图 所示,假设服务端设置消息大小阈值等于1MB , 表示最大允许接收 1MB的消息 。 如果分区拉取阔值设置为512KB ,
低于1 MB ,对于那些小于 1 MB但大于 512 KB的消息,就永远无法被消费者获取到,因为服务端返回的分区消息最多只有 512 KB 。
消息大小阈值是服务端的选项,用户通常无法直接控制,但Kafka针对主题级别还提供了另外一个配置项message.bytes ,用来控制消息大小的阈值。
分区拉取阈值是消费者客户端的选项,每个消费者都可以向定义这个阈值大小 。 所以如果消费者的处理性能不够好,可以将分区拉取阈值设置低
一点,保证每次拉取的分区数据都能很快地处理完成。

3. 设置轮询记录阈值
假设客户端一次拉取到了 10000条消息,如果处理时并不想要(或者根本没办法) 一次性处理完,而是期望按照每次 100条分批处理,就做不到了 。
前面的分区拉取阔值选项只能用来控制拉取的消息大小 , 但无法精确控制消息的数量 。 新版本( 0 .1 0 )的消费者客户端可以通过设置轮询记录阈值
( max.poll.records ) , 控制客户端调用 一次轮询方法最多允许处理多少条记录,默认值为 2147483647( 21 亿)。 实际上,这是一种批处理的方式,
若一次处理不完全部记录,就会分成多次。
轮询记录阈值配置项表示的并非“服务端最多返回这些记录”,而是“客户端的一次轮询最多能处理多少条记录” 。 比如客户端发送一次拉取请求从
服务端得到了 1000条记录 , 但是客户端最多一次只处理 100条记录,那么客户端需要分 10次 , 才能处理完一次拉取请求的所有数据。
如下图(上)所示,(对应方案一 )在获取记录集时将全局变量赋值给临时变量,并且清空了全局变量,但客户端只处理小批量的记录就结束了 ,
因此会丢失剩余的记录。 解决这个问题的办法是(方案二 ) : 在客户端循环处理获取到的所有记录,每次只处理一小批数据。 但这种方法无
法解决客户端每次轮询时必须处理完所有拉取记录,才能再次执行新的轮询调用的问题 ,仍可能出现前面说过的“处
理超时”问题。
如下图(下)所示(对应方案三 ),将全局变量添加到临时变量时 , 就限制消息数量 , 确保通过“获取记录集”返回的 临时变量只是一小部分消息 ,
足够保证客户端的处理性能 。 同时 ,剩余未被处理的记录会继续留在全局变量中 。 当下一次轮询时会继续获取全局变量中剩余的记录。 即使下一次轮
询时拉取到新的消息,也会一起放入全局变量。 并且,我们还能保证上次剩余的消息相较于新拉取的消息会被优先处理 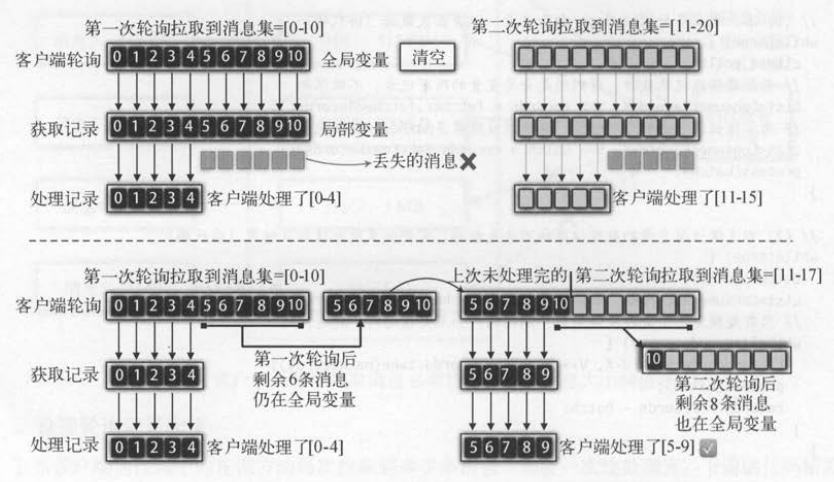
4 . 分区的记录集分多次消费
批处理的实现方式是,调用拉取器的 fetchedRecords ()方法从全局变量中获取数据, 一次最多只返回 maxRecords条记录 。
因为全局变量包括了分配给消费者所有分区的数据,而每个分区可能需要调用多次获取记录的方法才会全部返回,所以在迭代每个分区
只有一个分区完全被消费完,才会从迭代器中移除 。
一个分区记录集对象包括分区信息、记录集以及拉取偏移量。 可能有些分区记录集的记录数比轮询记录 阈值( maxRecords )配置项要多,
那么拉取器每次获取一批记录集的方法就需要调用多次,才能完全消费完这个分区 。
在分区记录集对象的 take ()方法返回最多maxRecords条记录给“获取记录集”方法之前 , 会更新分区记录集对象的拉取变量,然后在
“获取记录集”方法中也会更新订阅状态中分区状态的拉取偏移量, 即分区记录集对象的拉取偏移盐和分区状态的拉取偏移量要保持一致的数据 。
如下图所示,新API中构建拉取请求使用的拉取偏移量来自于分区状态的拉取偏移量,而不是分区记录集对象。分区记录集表示的是拉取到的分区数据结果
只会用于将分区结果放入全局变量中 ,它的作用并不是很大 。 拉取器获取拉取记录集后更新偏移量的具体步骤如下。
(1)拉取器发送拉取请求 , 将订阅状态 中分区的 position作为拉取偏移量 。
(2)消费者收到拉取请求后, 创建存储拉取结果的分区信息对象,并存储到全局变量。
(3)消费者调用拉取器的获取记录集方法,会从步骤 (2) 的全局变量中获取数据 。
(4)为了保证应用程序处理记录 的性能 ,会对每次返回的记录集数量进行限制 。
(5)在返回记录集给应用程序之前,会更新订阅状态中分区信息的 position 。
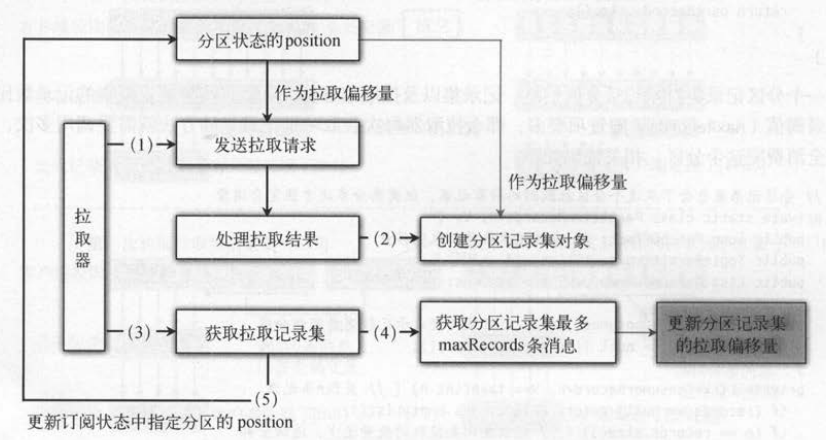
5 新请求不会拉取没有处理完的分区
采用轮询记录阈值每次只处理一小批记录 , 而不是拉取到的全部记录 。 那么每个分区记录集可能会分成多次才被完全处理,
这就带来了一个新的问题 : 如果这个分区还没有被客户端处理完成 , 新的拉取请求就不会处理这个分区 。
全局变量(this.records )表示的是“未被客户端处理的所有记录” ,获取记录集方法中的临时变量( drained )表示的是“本次会被客户端处理的记录” 。
每次调用获取记录集方法 , 最多只会从全局变量取出 maxRecords条记录放入临时变量,返回给客户端处理, 而剩余未被客户端处理的记录仍然保
留在全局变量中 。 拉取器在发送新的拉取请求时,如果分区记录集仍然存在全局变量,这个分区就不需要拉取。
如下表所示,假设“轮询记录阔值”为 100 ,消费者分配了 [P0-P9]共 10个分区,每个分区都有 1000条消息 。 第一次轮询后只会处理分区P0序号为[0-100)
的 100条消息 。此时全局变量中的分区仍然是[P0-P9) ,所以下一次发送拉取请求时,不会拉取任何分区,因为分配给消费者的 10个分区都还没有处理完 。
分区P0的 1000条消息要分成 10次才能消费完,所以调用 10次“获取记录集” 方法(对应 10次轮询)后,分区P0才会从全局变量中移除,接着才会处理P1分
区的消息 。这时如果再次发送拉取请求,才会开始拉取分区内的现消息。
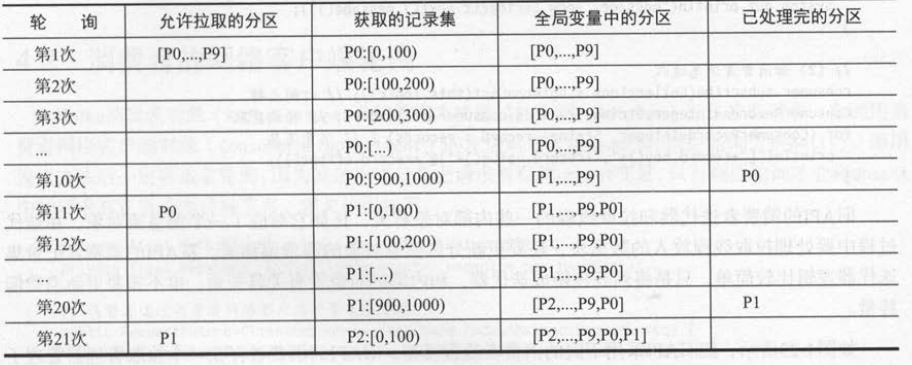
以第 11次轮询为例,之前拉取请求返回 的分区P0 , 它的所有消息已经都消费完成了(第一次到第十次轮询),所以新的拉取请求允许拉取分区P0。
全局变量中还保留了 [P1-P9]共9个分区,调用“获取记录集” 方法返回的是分区P1的记录集 。因为分区P1的记录集也有 1000条 , 超过了“轮询记录阔值”
的100条限制,所以分区P1仍然还在全局变量中 。 又因为新拉取请求返回了分区内的新消息,所以分区P0也会重新加入全局变量中 。
最终全局变量的分区顺序是 [P1-P9,P0],注意 :分区P0在最后,它表示的是第二次拉取请求的新消息 ,而分区 [P1-P9]还只是第一次拉取请求的旧消息 。
以上分析了拉取器的 “获取记录集”方法的多个优化方案 , 这个方法是在消费者的轮询 中调用,并不是由消费者客户端应用程序调用的 。
如果要让应用程序获取记录集,就要把消费者内部的 “拉取器”对象也暴露给应用程序代码 。 应用程序应该只要调用消费者的轮询方法,就可以得到需要
的数据。消费者的轮询方法封装了拉取消息的流程,主要包括3个步骤 : 发送拉取请求 、 网络层轮询 、 获取记录集。 如果最后一步获取记录集没有得到数据,
并且在超时时间内,轮询方法会再次发送拉取请求,并执行网络轮询,直到有数据返回给应用程序,供其进行实际的业务逻辑处理。
消费消息
拉取器返回的记录集是消费者记录列表,在返回给客户端时,会被封装成消费者记录集( ConsumerRecords )迭代器,便于客户端直接进行迭代处理。
和旧消费者使用 ConsumerIterator类似,消费者记录集迭代器也实现了 Iterable接口,所以可以用for循环处理每条消息 。旧 API应用程序用到了消费者连接器、
消息流和消费者迭代器,新 AP I 只用到了消费者对象( KafkaConsumer)、消费者记录集迭代器 。 还有一个不同点是 :旧API返回的消费者迭代器消息是字节
数组,而新API直接返回消息的原始类型 。
旧 API的消费者迭代器和拉取线程的一些内部对象有关,比如它对应了 一个消息流对象,在迭代过程中要处理拉取线程放入的数据块,还要更新分区信息对象
的消费偏移量 。新API的消费者记录集迭代器逻辑比较简单,只是将列表转换成迭代器,和内部的对象没有关联关系,也不需要更新消费偏移量。
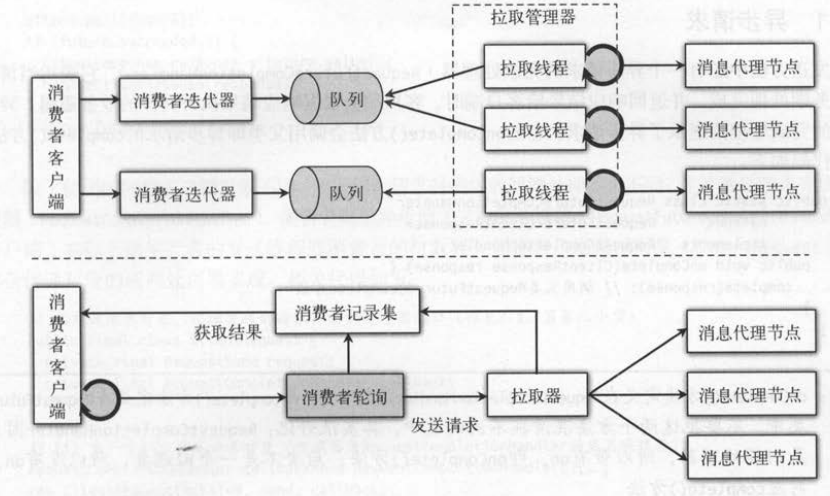
如下图所示,新旧API采用不同的消费者线程模型。 旧API的消费者存在一个拉取管理器管理了所有的拉取线程。拉取线程会不断地从服务端拉取数据,
并将拉取到的数据块填充到队列中 。消费者客户端应用程序订阅主题时可以设置线程数量,每个线程对应一个队列 。 因此如果有多个队列,客户
端需要读取所有的队列,才能完整地消费分配给消费者的所有分区数据。
新API的消费者没有在内部使用多线程的拉取线程,它是一个单线程的应用程序 。 客户端通过循环地轮询来获取数据 。 消费者拉取消息通过拉取器对象完成,
这个拉取器不是一个线程,只是负责把拉取请求发送给分区的主副本节点,并且会在客户端请求的回调方法中,将拉取结果存储到一个全局的成员变量。
客户端要获取拉取到的结果,也是通过消费者的轮询从拉取器的全局成员变量中获取数据。