优化方式
1.空间换时间(冗余)
2.时间换空间
字段优先使用类型
int > date > char > varchar > text
索引类型
btree索引、hash索引
索引的叶子下,存放一个信息指向所在行的数据地址。
btree有利于范围查询,hash有利于精确查询。
btree用的更多一些。
btree索引的常见误区
1.在where条件的常用的列上都加上索引
(因为索引同时只能用上一个)
可以用多列联合索引来处理多条件查询。
优化要实地调研,结合实际场景,然后加上多列索引。
联合索引的顺序很重要,影响着查询的效果。
为什么商品表,在价格price上加了索引,查询速度没有提升?
答:正常的查询都是复合查询,根据多条件查询,比如分类下商品的价格。可以加上(cat_id,price)复合索引来解决这个问题。
索引作用
1.提高查询速度
2.提高排序速度
3.提高分组统计速度
myisam(非聚簇索引)和innodb(聚簇索引)引擎
对应非聚簇索引和聚簇索引(都是btree索引)
非聚簇索引,索引和数据是分开的。
聚簇索引的叶子节点比较大,直接存储其他的字段的数据。
聚簇索引,当你找到索引的位置时候,就不需要回行去找数据了。直接就获取了数据。
myisam(非聚簇索引)索引指向行在磁盘上的位置。
innodb(聚簇索引)次级索引指向对主键索引的引用。
聚簇索引,乱序插入数据,最终的数据仍然是有序的。非聚簇索引,如果是乱序插入,最终的数据就会是乱序的。
Btree索引的图解,如果是性别索引,将会分成三块,男、女、null。每个对应很多数据。所以,即便快速知道男女,还是要逐条查询获取数据。
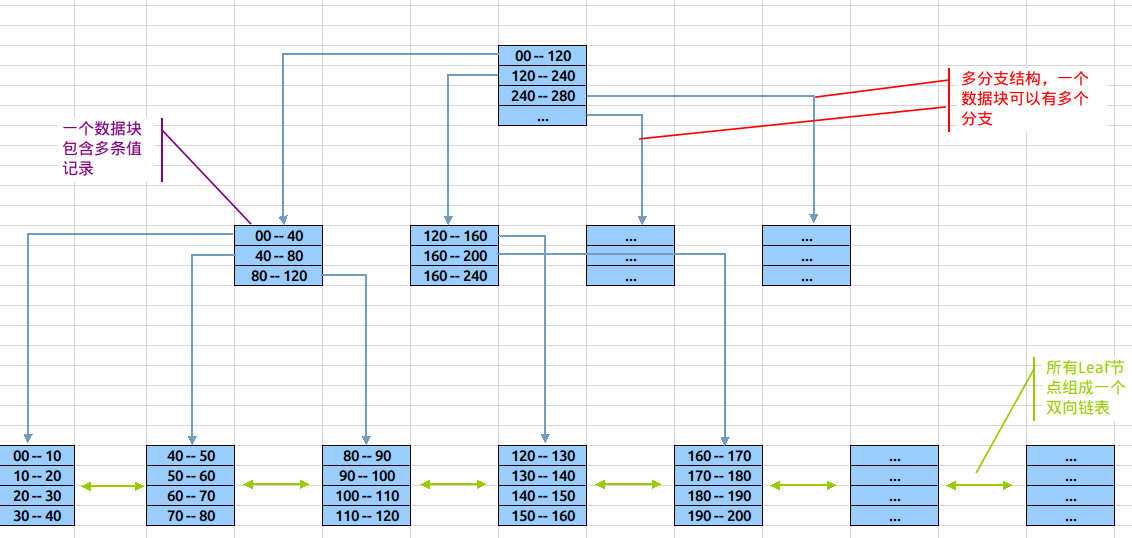

什么是索引覆盖?
如果查询的内容,能直接从索引上获取,那么就不需要回行到磁盘上去找数据了。这种查询效率很快。
理想的索引
查询频繁,
区分度高(不要给性别加索引),
长度小,
尽可能覆盖常用查询字段。
如果有1000条数据,去除重复后,有200个。那个相当于5条数据共用一个索引。
如果是1000条性别数据,去除重复后,只有男、女。那么相当于500条数据共用一个索引。区分度不高。
索引的添加要分析用户查询的习惯,分析查询日志,合理的添加索引。
重复索引和冗余索引
重复索引是指在同一个列,或者顺序相同的几个列,建立多个索引。
重复索引没有任何帮助,只会增加索引文件,拖累更新速度。
冗余索引允许存在。
index arttag(artid,tag) index tagart(tag,artid)
这两个索引,列有重叠,但是顺序不一样,称为冗余索引。可以利用索引的索引覆盖,快速获取数据。
索引碎片
在长期的数据更改过程中,索引文件和数据文件,都将产生空洞,形成碎片。
修复碎片,就是讲表和索引重建一下,将其码放整齐了。
sql语句优化
查找
取出
如何查的快?
联合索引的顺序,区分度,长度
如何取得快?
索引覆盖
传输的少,更少的行和列
sql语句优化思路?
不查,少查,高效的查
不查,通过业务逻辑来计算
少查,尽量精准数据,少取行。评论等信息,一次获取10到30条左右。
必须要查,尽量走索引,走索引覆盖。
explain分析
select_type
simple 不含子查询
primary 含子查询,外层叫primary,里面分多种(derived、union、subquery....)
possible_key 可能用到的索引,只能用到一个。
key 最终用到的索引。
key_len用到索引的最大长度。
定长字段,int占四个字节、date占三个字节、char(n)占n个字符。
对于变成字段varchar(n),则有n个字符+两个字节。
不同的字符集,一个字符占用的字节数不同。latin1编码的,一个字符占用一个字节,gbk编码的,一个字符占用两个字节,utf8编码的,一个字符占用三个字节。
type
all查询所有数据。
index扫描所有的索引节点,相当于index_all。
range,查询范围。
ref,引用查询。
eq_ref,准确指到一行。
const,system,null 查询速度超快。
rows代表,估计要扫描多少行。
extra
using index,速度极快,用到了索引覆盖。
using where,用到了筛选。
using temporary ,用到了临时表。不太好。
using filesort ,用到了排序。
如果查询条件中有函数,或者表达式,索引在查询上将不会被使用。索引覆盖依然有可能使用到索引。
不鼓励三表联查,多表联查说明表设计的有问题。
少用in查询,它会全部逐行搜索查询对比,查询慢。
desc table_name; # 可以查看表字段详情
EXPLAIN sql; # 可以查看语句执行情况
MySQL Key值(PRI, UNI, MUL)的含义
PRI表示主键索引
UNI表示唯一索引
MUL表示可重复索引
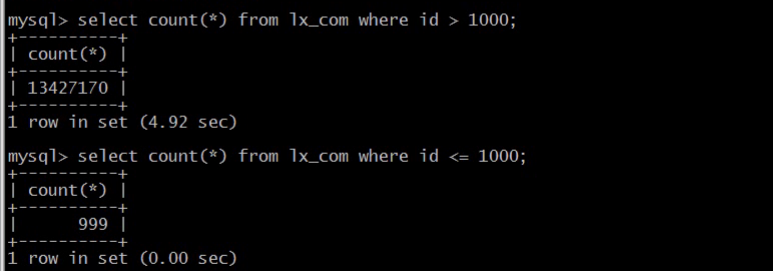
count
查询全部的很快,因为总数已经被记录。
但是只要加条件,就需要逐行统计。
看下面的图,大概sql逐行找,1,2,3...1000。就停止了。
沿着索引列,一边走,一边统计。

group by的列要有索引,可以避免临时表及文件排序。
order by的列要尽量跟group by 一致,否则也会引起临时表。(知其然,知其所以然。)
group by 是必排序的。
union必产生临时表。
数据少的话,sql没必要优化。但是数据量一旦指数级的增长,sql优化就非常的有必要了。
要想去重,就得排序,只要排序,数据就慢。
limit翻页优化
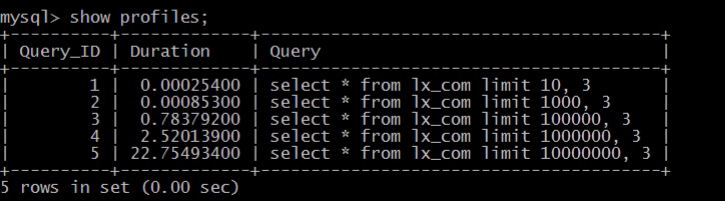
有意思的,当offset很大的时候,同样是取3条数据,却要20多秒。
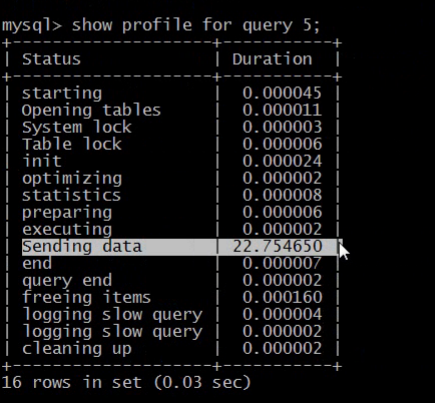
大量的数据,拿了仍,拿了仍导致的。
优化办法:
1.业务上,不允许翻过100页。
如果经理非让翻到10000页,先在心里骂他两句,然后接着干活。
2.不用offset,用条件查询。
limit 5,3;
where id > 5 limit 3;
但是数据不可以删除,否则计算出的分页跟实际的分页不一致。