分区:
(1).一种分区技术,可以在创建表时应用分区技术,将数据以分区形式保存。
(2).可以将巨型表或索引分割成相对较小的、可独立管理的部分。
(3).表分区时必须为表中的每一条记录指定所属分区。
对表进行分区优点:
增强可用性;
维护方便;
均衡I/O;
改善查询性能。
创建分区表
分区方法:范围分区、散列分区、列表分区、组合范围散列分区和组合范围列表分区;
1、范围分区:是对数据表中某个值的范围,使用partition by range子句进行分区。
1 create table testscore(
2 id number primary key,
3 name varchar2(8),
4 subject varchar2(10),
5 score number
6 )
7 --指定按照score列,进行范围分区
8 partition by range(score)
9 (
10 --将表分成3个区,分别为range1、range2、range3,并存在不同的三个表空间上
11 partition range1 values less than(60) tablespace AAA,
12 partition range2 values less than(80) tablespace BBB,
13 partition range3 values less than(maxvalue) tablespace CCC
14 );
--向表testscoe中插入数据
1 insert into testscore values (1,'tyou','maths',50);
2 insert into testscore values (2,'zhangsa','maths',90);
3 insert into testscore values (3,'thm','english',76);
4 insert into testscore values (4,'tya','maths',98);
5 insert into testscore values (5,'jionjion','yuwen',32);
6 insert into testscore values (6,'haha','wuli',66);
7 commit;
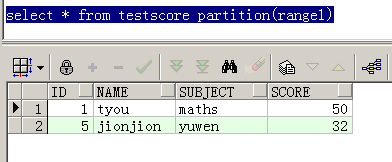
--查询分区range1的结果如下:
select * from testscore partition(range1);
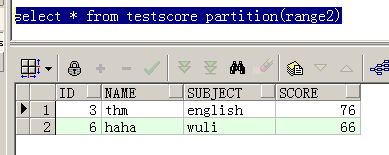
--查询分区range2的结果如下:
select * from testscore partition(range2);
2、散列分区:通过哈希hash算法均匀分布数据,通过在I/O设备上进行散列分区,可以使得分区的大小一致。使用partition by hash子句。
1 create table testid(
2 id number primary key,
3 name varchar2(8),
4 subject varchar2(10),
5 score number
6 )
7 --指定按照id列,进行散列分区
8 partition by hash(id)
9 (
10 partition part1 tablespace AAA,
11 partition part2 tablespace BBB,
12 partition part3 tablespace BBB
13 );
3、列表分区:适用于分区列的值为非数字或日期数据类型,并且分区列的取值范围较少时,使用partition by list子句。
--例如,成绩表中的subject科目列取值较少。
1 create table testsubject(
2 id number primary key,
3 name varchar2(8),
4 subject varchar2(10),
5 score number
6 )
7 --指定按照id列,进行散列分区
8 partition by list(subject)
9 (
10 partition part1 values('maths','yuwen') tablespace AAA,
11 partition part2 values('english','wuli') tablespace BBB,
12 partition part3 values('huaxue') tablespace CCC
13 );
--向表testsubject中插入数据
1 insert into testsubject values (1,'tyou','maths',50);
2 insert into testsubject values (2,'zhangsa','maths',90);
3 insert into testsubject values (3,'thm','english',76);
4 insert into testsubject values (4,'tya','maths',98);
5 insert into testsubject values (5,'jionjion','yuwen',32);
6 insert into testsubject values (6,'haha','wuli',66);
7 insert into testsubject values (7,'hehe','huaxue',66);
8 commit;
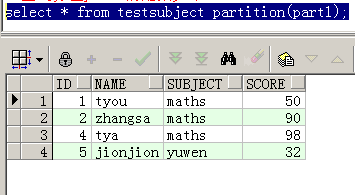
--查询分区part1的结果如下:
select * from testsubject partition(part1);
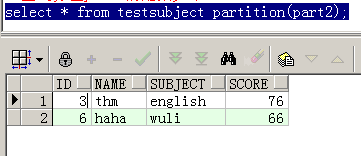
--查询分区part2的结果如下:
select * from testsubject partition(part2);
--查询分区part3的结果如下:
select * from testsubject partition(part3);

4、组合范围散列分区:结合范围分区和散列分区
1 create table testRanHas(
2 id number primary key,
3 name varchar2(8),
4 subject varchar2(10),
5 score number
6 )
7 --指定按照score列范围分区分成3个分区
8 partition by range(score)
9 --然后,再使用subpartition by子句进行散列分区
10 subpartition by hash(id)
11 subpartitions 2 store in (AAA,BBB)
12 (
13 partition range1 values less than(60),
14 partition range2 values less than(80),
15 partition range3 values less than(maxvalue)
16 );
5、组合范围列表分区:结合范围分区和列表分区
1 create table testRanLis(
2 id number primary key,
3 name varchar2(8),
4 subject varchar2(10),
5 score number
6 )
7 partition by range(score)
8 subpartition by list(subject)
9 (
10 partition range1 values less than(60)
11 (
12 subpartition part1_1 values('maths','yuwen') tablespace AAA,
13 subpartition part1_2 values('english','wuli') tablespace BBB
14 ),
15 partition range2 values less than(80)
16 (
17 subpartition part2_1 values('maths','yuwen') tablespace AAA,
18 subpartition part2_2 values('huaxue') tablespace CCC
19 ),
20 partition range3 values less than(maxvalue)
21 (
22 subpartition part3_1 values('maths','yuwen') tablespace AAA,
23 subpartition part3_2 values('english','wuli') tablespace BBB,
24 subpartition part3_3 values('huaxue') tablespace CCC
25 )
26 );
分区表索引:3种类型,局部分区索引、全局分区索引和全局非分区索引
局部分区索引:
为分区表的各个分区单独建立的索引,各个分区索引之间相互独立的。
--先创建一个范围分区表
1 create table testscore(
2 id number primary key,
3 name varchar2(8),
4 subject varchar2(10),
5 score number
6 )
7 partition by range(score)
8 (
9 partition range1 values less than(60) tablespace AAA,
10 partition range2 values less than(80) tablespace BBB,
11 partition range3 values less than(maxvalue) tablespace CCC
12 );
--再创建局部分区索引
1 create index index_testscore
2 on testscore(name) local
3 (
4 partition index1 tablespace AAA,
5 partition index2 tablespace BBB,
6 partition index3 tablespace CCC
7 );
全局分区索引:
对整个分区表建立的索引,全局分区索引的各个分区之间不是相互对立的。
1 create index global_index_testscore
2 on testscore(score)
3 Global partition by range(score)
4 (
5 partition range1 values less than(60) tablespace AAA,
6 partition range2 values less than(80) tablespace BBB,
7 partition range3 values less than(maxvalue) tablespace CCC
8 );
注意:使用global建立全局分区索引,只能用于range分区!!!
全局非分区索引:
对整个分区表建立索引,但未对索引进行分区。
create index nopart_index_testscore
on testscore(subject);
分区表管理:
1、增加分区
为范围分区表增加分区:
--先创建一个test范围分区表
create table test(
id number primary key,
name varchar2(8),
subject varchar2(10),
score number
)
partition by range(score)
(
partition range1 values less than(60) tablespace AAA,
partition range2 values less than(80) tablespace BBB,
partition range3 values less than(100) tablespace CCC
);
--在最后一个分区之后增加分区
alter table test
add partition range4 values less than(150)
--在分区中间或开始出增加分区
--在80-100之间,增加一个90分开成两个分区,即range3分成range5和range6
1 alter table test
2 split partition range3 at(90)
3 into(
4 partition range5 tablespace AAA,
5 partition range6 tablespace BBB
6 );
为散列分区表增加分区:
alter table test2
add partition range4 tablespace AAA;
为列表分区表增加分区:
alter table test3
add partition range4 values('shengwu') tablespace AAA;
2、合并分区:
--将之前增加的分区合并
alter table test
merge partitions range5,range6 into partition range3;
3、删除分区:
alter table test
drop partition range4;