正则表达式-菜鸟教程:
https://www.runoob.com/regexp/regexp-syntax.html
先看一个实例
String text = "#My# <name> is 'ZhangSan',18 <years> old this year."; //文本
String regex = ".+"; //正则表达式, ".+"意思是匹配所有的内容
@Test
public void regexTest() {
Pattern compile = Pattern.compile(regex); //传入正则表达式,新建模板类(Pattern)的对象
Matcher m = compile.matcher(text); //传入文本,用模板类的对象新建匹配类(Matcher)的对象
while(m.find()) { //用匹配器(m)的find()方法查看是否能够匹配到内容,返回boolean
System.out.print(m.group() + "_"); //用匹配器的group()方法捕获匹配到的内容,并以String类型返回
}
}
结果是
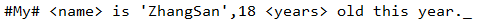
只有一个下划线"_",可见整个句子都被一次匹配到了.
从上边的例子可以看到,在JAVA中,使用正则表达式用到两个类,分别是
Pattern和Matcher
使用Pattern的静态方法compile()来获取一个Pattern对象,再用此对象的matcher()方法获取一个Matcher对象,最后使用while循环来遍历匹配的结果
匹配符和限定符
匹配符用于表达正则表达式的匹配内容.
限定符用于控制正则表达式匹配的机制,写在匹配符后.
匹配符:
abc ==> 匹配字符串中的"abc"
[abc] ==> 匹配字符串中"a"或"b"或"c"
[a-zA-Z0-9] ==> 匹配字符串中的一个字母或数字
[^0-9] ==> 匹配字符串中地一个数字以外的内容, 在中括号内,^表示'非'
d ==> digital 匹配数字
D ==> 匹配非数字内容
w ==> 匹配字母数字下划线,等价于[A-Za-z0-9_]
W ==> 匹配非字母数字下划线的内容
s ==> 匹配空白字符(空格)
S ==> 匹配空白符意外内容
. ==> 匹配任意内容,除了 (回车符)和 (换行符)
PS : 以上红色匹配符,都是一次只匹配一个字符(比如a,或8,等等),如果要一次匹配多个字符,需要添加限定符
限定符:
PS:限定符只作用于它前边的1个字符(或者一个小括号分组),比如ab+,这个+号只作用于b
{n} ==> 出现n次
{n,} ==> 出现至少n次
{n,m} ==> 出现最少n次,最多m次
+ ==> 出现1-n次,等价于{1,}
* ==> 出现0-n次,等价于{0,}
? ==> 出现0-1次,等价于{0,1},可以写在其他限定符后,表示懒惰匹配
贪婪匹配和懒惰匹配
贪婪匹配 : 除?以外的限定符,都是贪婪匹配
懒惰匹配 : 在其他限定符后加上?,则是懒惰匹配.
//一个用来匹配的字符串
String sentence = "cb-ceb-ceeb-ceeeb-ceeeeb";
//正则表达式
String regex1 = "c.{2}b";
//结果是"ceeb"
String regex1 = "c.{2,}b";
//结果是 "cb-ceb-ceeb-ceeeb-ceeeeb",可以看到,贪婪模式下整个字符串都被一次匹配
String regex1 = "c.{2,}?b"; //懒惰模式,其中"."匹配2至多个,且尽可能少地匹配"."
//结果是 "cb-ceb" "ceeb" "ceeeb" "ceeeeb",贪婪模式下,只要满足条件就匹配.
String regex1 = "c.{2,4}b";
//结果是"cb-ceb" "ceeb" "ceeeb" "ceeeeb"
String regex1 = "c.+b"; //
//结果是"cb-ceb-ceeb-ceeeb-ceeeeb", 整个字符串都被匹配下来
String regex1 = "c.+?b";
//结果是"cb-ceb" "ceeb" "ceeeb" "ceeeeb"
//没有"ceb"是因为先匹配到地"ce-ceb"包含了"ceb"
String regex1 = "c.*b"; //以贪婪模式匹配以c和b为首尾,0至多个"."
//结果是"cb-ceb-ceeb-ceeeb-ceeeeb",整个字符串被匹配
String regex1 = "c.*?b"; //以懒惰模式,匹配c和b为首位,0至多个".",且匹配尽可能少的"."的个数
//结果是 "cb" "ceb" "ceeb" "ceeeb" "ceeeeb"
关于汉字匹配
匹配汉字文字:
[u4e00-u9fa5]
匹配非汉字字符:
[^u4e00-u9fa5]
匹配双字节字符(汉字、中文标点符号等):
[^x00-xff]
示例
//用来匹配的句子 String sentence = "我的名字是barry,来自NewYork."; String regex = "[^\x00-\xff]+"; //结果是 "我的名字是" "来自"
Pattern类
f
Matcher类
f
f