时间:2018年
Introduction
end-to-end encoder-decoder模型存在一个问题:当将一张包括未见过的场景输入到网络中时,返回的结果仅仅就是一些显著的object,比如“there is a dog on the floor”,这样的结果与object detection几乎没有区别
认知上的证据表明,基于视觉的语言并非是end-to-end的,而是与高层抽象的符号相关,如果我们将scene抽象成符号,生成过程就会十分清晰,比如对于这幅图片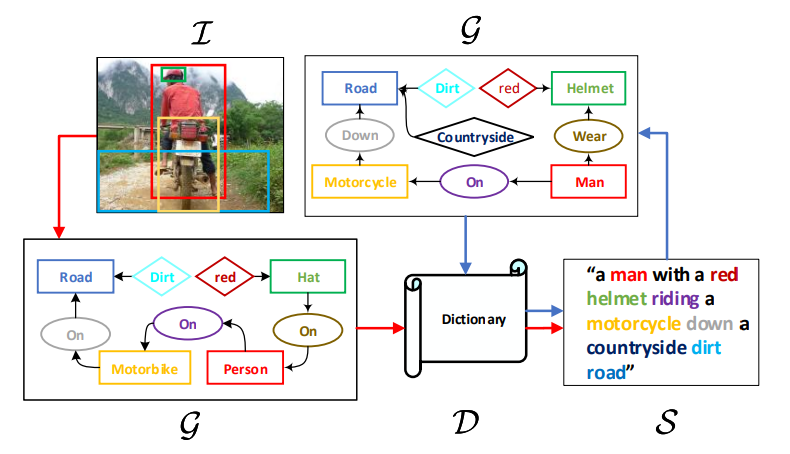
scene abstraction是“helmet-on-human”和"road dirty",我们则可以生成"a man with a helmet in contryside"通过使用一个常识:country road is dirty,这种推断就是inductive bias
本文将inductive bias融合到encoder-decoder中来进行image captioning,利用符号推理和端到端多模型特征映射互补,通过scene graph(G)来bridge它们,一个scene graph(G)是一个统一的表示,它连接了以下几个部分
- objects(or entities)
- their attributes
- their relationships in an image(I) or a sentence(S),通过有向边表示
key insight:the vector representations are expected to transfer the inductive bias from the pure language domain to the vision-language domain
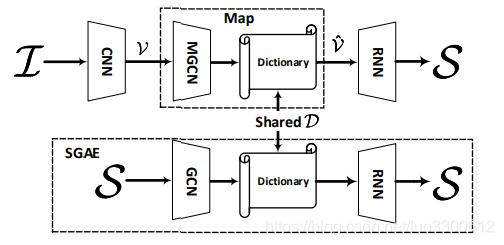
作者提出了Scene Graph Auto-Encoder(SGAE),作为一个句子重建网络,其过程是S → G → D → S
其中D是一个 可训练的字典,用来记录结点特征,S→G使用现成的scene graph language parser[1],D→S是一个可训练的RNN decoder,注意D是"juice"——即language inductive bias,在训练SGAE中得到,通过将D共享给encoder-decoder的pipline:I→G→D→S,即可利用语言先验来指导端到端模型,具体的I→G是一个visual scene graph detector[52],引入multi-modal GCN来进行G→D的过程,来补足detection的不足之处,有趣的是,D可以被视作为一个working memory,用来从I→S re-key encoded nodes,以更小的domain gap来得到一个更一般的表达,
Contrubution
- 一个先进的SGAE模型,可以学习language inductive bias的特征表达
- 一个multi-model 图卷积网络,用来调节scene graph到视觉表达
- 一个基于SGAE的 encoder-decoder image captioner with a shared dictionary guiding the language decoding
Encoder-Decoder
给一张图片I mathcal{I}I,我们需要生成一句话S = { w 1 , w 2 , . . . , w T },state-of-the-art的image captioner是如下形式
通常,encoder是一个卷积神经网络,map是一个attention mechanism,将feature编码到一个更加informative的空间中,decoder是一个RNN-based 语言decoder,来预测S,给定labelS ∗ 和 I通过最小化交叉熵函数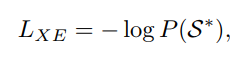
或者通过强化学习最大化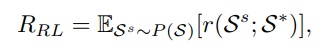
这是目前几乎所有state-of-the-art的image captioning模型的基本架构,但它有 dataset bias,为了解决这个问题,我们使用language inductive bias,可以表示为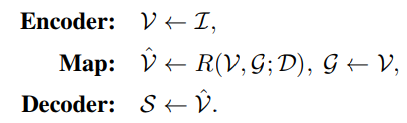
随后我们将使用SGAE来学习D,通过sentence self-reconstruction with the help of scene graphs,然后我们将encoder-decoder equip上SGAE作为全局的image captioner,特别的是我们使用D和Multi-model 图卷积网络来re-encode 图像的 features
Auto-Encoding Scene Graphs
本节介绍如何通过self-reconstructing学习D,如图所示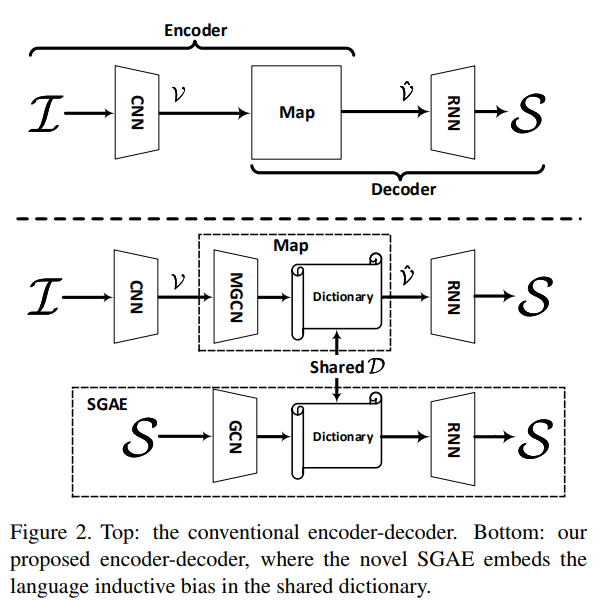
SGAE的过程如下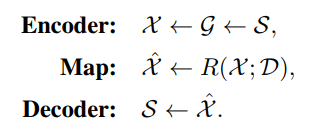
Scene Graphs
S→G,从sentence到scene graph,scene graph是一个元组G=(N,ε),其中N和ε是边节点和边的集合,有三种N:目标结点o oo,属性结点a,以及关系结点r,记oi是第i个目标,ai,l是oi的第 l个属性,每个结点以d-维向量表示,作者的实验中d=1000,结点的特征是可训练的label embedding
边ε的有以下几种
- 如果一个目标oi有属性ai,l,则oi到ai,l有一条有向边
- 如果存在三元组关系<oi−rij−oj>,则oi到rij和rij到oj均有两条边
下图给了一个例子,其中包括七个结点六条边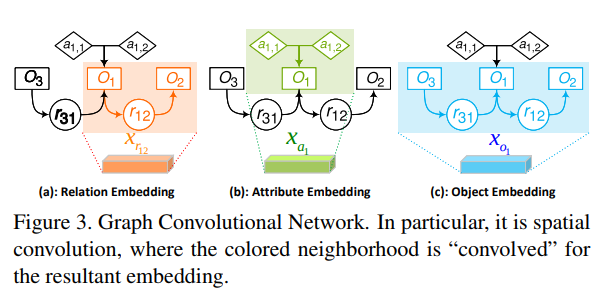
使用[1]中的scene graph parser来得到G mathcal{G}G
graph convolution network
G→X,将node embedding eo,ea,er转化成context-aware embedding X,X包括三种d维 embedding:关系embedding xri,j for 关系结点ri,j,目标embedding for 目标结点oi,以及属性结点xaifor目标结点oi,作者使用d=1000,使用四个空间图卷积(spatial graph convolutions):gr,ga,gs,go来生成上述的embedding,这四个网络有一样的结构,相互独立的参数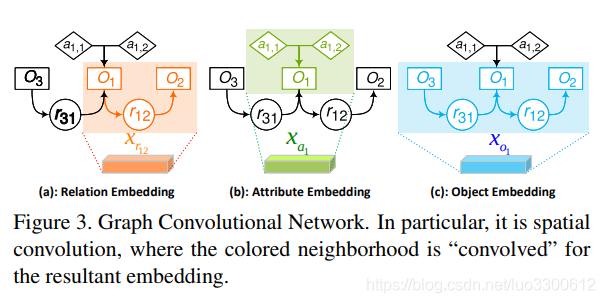
Relationship Embedding xri,j
对每个三元组<oi−rij−oj>,xri,j综合上下文信息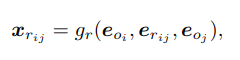
Attribute Embedding xai
对一个object结点oi,xai综合它和它的所有属性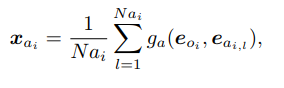
其中Nai是oi的属性个数
Object Embedding xoi
xoi需要综合oi在整个graph中的主客体关系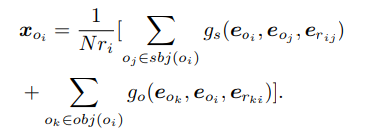
若oj∈sbj(oi)表示oi是subject,oj是object,N r i = ∣ s b j ( i ) ∣ + ∣ o b j ( i ) ∣
Dictionary
这一步学习D并用它re-encodeR(X;D)→X^的方法,核心观点是保留working memory来执行dynamic knowledge base for run-time inference。D的目标是embed language inductive bias到语言合成中。
这个过程就是学习一个字典D=d1,d2,...,dK∈Rd×K,文章设K=10,000,re-encode: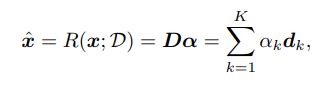
其中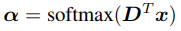
是memory network中的核心操作
使用[2]中的attention structure来reconstruction S,
Overall Model: SGAE-based Encoder Decoder
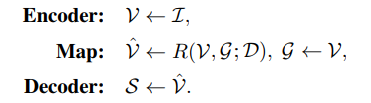
Multi-modal Graph Convolution Network
通过multi-modal图卷积网络将visual feature V转化成graph-modulated features V ′ ,此处的scene graph G是由image scene graph parser得到的,它包括一个object proposal detector(Faster-RCNN),一个attribute classifier(一个小的fc-ReLU-fc-Softmax network) 和一个relationship classifier(MOTIFS)。
将检测到的label embeddingeoi和visual featurvoi融合在一起成为新的结点特征uoi: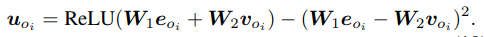
其余的embeddingurij和uai按照类似的方法生成,image G 和 sentence G的不同在于前者simpler,nosier,如图所示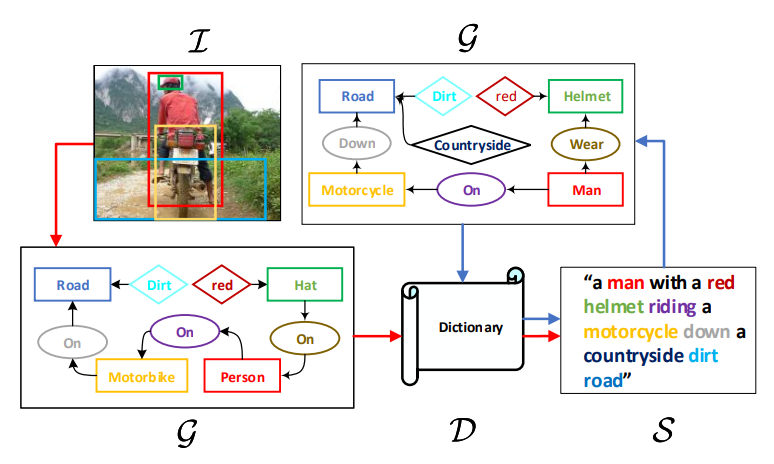
生成G之后,计算embedding和re-encode的过程与处理sentence G类似
结论
本文将 language inductive bias 融合到了image caption中,实现了more human-like的 language generation,主要方法是使用基于scene graph G的feature,学习并共享一个字典 D来re-encode这个feature。
问题
- pure language domain 和 vision-language domain 有啥区别
- 有了边表示关系那关系结点是干啥的
表示不同的关系,比如wear hold等等