语义分割是将标签分配给图像中的每个像素的过程。这与分类形成鲜明对比,其中单个标签被分配给整个图片。语义分段将同一类的多个对象视为单个实体。另一方面,实例分段将同一类的多个对象视为不同的单个对象(或实例)。通常,实例分割比语义分割更难。

本博客探讨了使用经典和深度学习方法执行语义分割的一些方法。此外,还讨论了流行的损失函数选择和应用。
经典方法
在深度学习时代开始之前,使用了大量的图像处理技术将图像分割成感兴趣的区域。下面列出了一些常用的方法。
灰度分割
最简单的语义分段形式涉及分配区域必须满足的硬编码规则或属性,以便为其分配特定标签。规则可以根据像素的属性(例如灰度级强度)来构建。使用此技术的一种方法是拆分和合并算法。该算法递归地将图像分割成子区域,直到可以分配标签,然后通过合并它们将相邻的子区域与相同的标签组合。
这种方法的问题是规则必须是硬编码的。而且,仅使用灰度信息来表示诸如人类的复杂类别是极其困难的。因此,需要特征提取和优化技术来正确地学习这种复杂类所需的表示。
条件随机场
考虑通过训练模型来分割图像以为每个像素分配一个类。如果我们的模型不完美,我们可能会获得在本质上可能不可能的噪声分割结果(例如与猫像素混合的狗像素,如图所示)。

这些可以通过考虑像素之间的先验关系来避免,例如物体是连续的,因此附近的像素倾向于具有相同的标记。为了模拟这些关系,我们使用条件随机场(CRF)。
CRF是一类用于结构化预测的统计建模方法。与离散分类器不同,CRF可以在进行预测之前考虑“邻近上下文”,例如像素之间的关系。这使其成为语义分割的理想候选者。本节探讨了CRF在语义分割中的用法。
图像中的每个像素与一组有限的可能状态相关联。在我们的例子中,目标标签是可能的状态集。将状态(或标签u)分配给单个像素的(x)成本称为一元成本。为了模拟像素之间的关系,我们还考虑将一对标签分配给称为成对成本(u,v)的一对像素(x,y) 的成本。我们可以考虑作为其直接邻居的像素对(网格CRF),或者我们可以考虑图像中的所有像素对(密集CRF)

所有像素的一元和成对成本之和被称为CRF的能量(或成本/损失)。可以最小化该值以获得良好的分割输出。
深度学习方法
深度学习极大地简化了管道,以执行语义分割,并产生令人印象深刻的质量结果。在本节中,我们将讨论用于训练这些深度学习方法的流行模型体系结构和损失函数。
1.模型架构
用于语义分割的最简单和最流行的架构之一是完全卷积网络(FCN)。在论文FCN for Semantic Segmentation中,作者使用FCN首先通过一系列卷积将输入图像下采样到更小的尺寸(同时获得更多通道)。这组卷积通常称为编码器。然后通过双线性插值或一系列转置 - 卷积对编码输出进行上采样。这组转置卷积通常称为解码器。

尽管这种基本架构有效,但它具有许多缺点。一个这样的缺点是由于转置 - 卷积(或反卷积)操作的输出的不均匀重叠而存在棋盘伪像。

另一个缺点是由于编码过程中的信息丢失而在边界处的分辨率较差。
提出了几种解决方案来改善基本FCN模型的性能质量。以下是一些被证明有效的流行解决方案:
U-NET
该U形网是一个升级到简单FCN架构。它跳过了从卷积块输出到相同级别的转置卷积块的相应输入的连接。
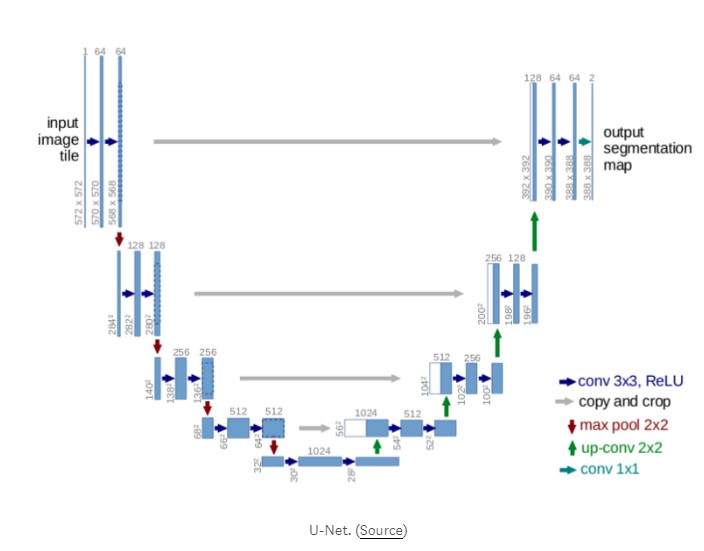
此跳过连接允许渐变更好地流动并提供来自图像大小的多个比例的信息。来自较大尺度(上层)的信息可以帮助模型更好地分类。来自较小尺度(较深层)的信息可以帮助模型段/更好地本地化。
Tiramisu 模型
该提拉米苏模式是类似U-Net的,除了它使用卷积致密块,并作为做换位,回旋的事实DenseNet纸。密集块由若干层卷积组成,其中所有前面层的特征图用作所有后续层的输入。由此产生的网络具有极高的参数效率,可以更好地访问旧层的功能。

这种方法的缺点是,由于多个ML框架中的连接操作的性质,它的内存效率不高(需要运行大型GPU)。
MultiScale方法
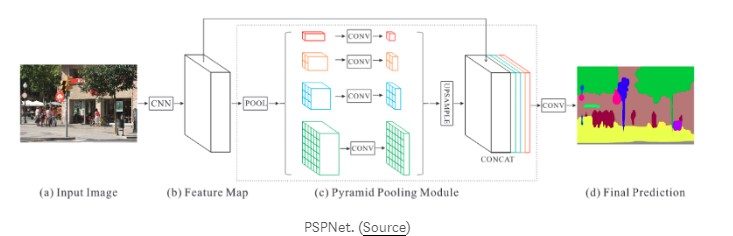
一些深度学习模型明确地引入了从多个尺度合并信息的方法。例如,金字塔场景分析网络(PSPNet)使用四种不同的内核大小执行池化操作(最大或平均),并跨越CNN的输出特征映射,例如ResNet。然后,它使用双线性插值对所有合并输出和CNN输出特征图的大小进行上采样,并沿通道轴连接所有这些输出。对该级联输出执行最终卷积以生成预测。
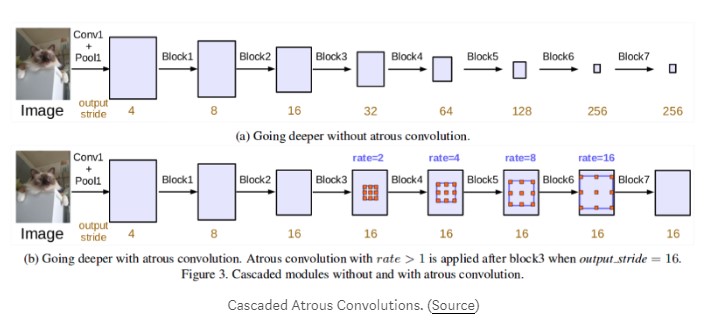
Atrous(Dilated)Convolutions提供了一种有效的方法来组合多个尺度的特征而不会大量增加参数的数量。通过调节膨胀率,相同的过滤器使其重量值在空间中展开得更远。这使它能够学习更多全局背景。
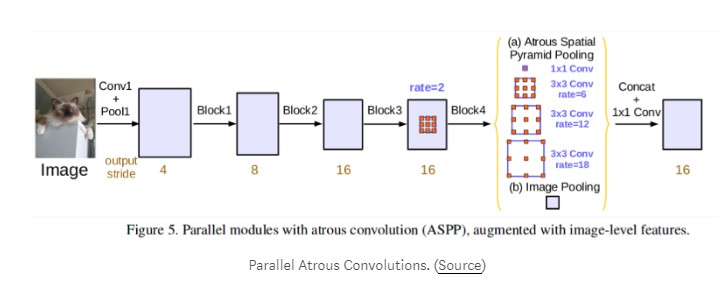
该DeepLabv3本文采用Atrous卷积不同的扩张速率捕捉来自多尺度信息,而在图像尺寸显著损失。他们尝试以级联方式(如上所示)使用Atrous卷积,并以Atrous Spatial Pyramid Pooling(如下所示)的形式以并行方式。
混合CNN-CRF方法
一些方法使用CNN作为特征提取器,然后将这些特征用作密集CRF的一元成本(潜在)输入。由于CRF能够模拟像素间关系,因此这种混合CNN-CRF方法提供了良好的结果。
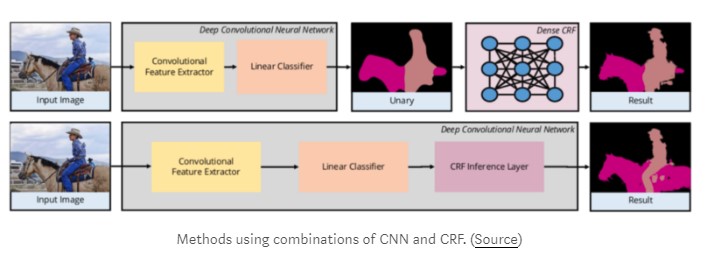
某些方法将CRF并入神经网络本身,如CRF-as-RNN中所示,其中密集CRF被建模为递归神经网络。这使得端到端训练成为可能,如上图所示。
2.损失函数
与普通分类器不同,必须为语义分段选择不同的损失函数。以下是一些用于语义分割的常用损失函数:
具有交叉熵的像素级Softmax
用于语义分割的标签具有与原始图像相同的尺寸。标签可以用单热编码形式表示,如下所示:

由于标签是方便的单热形式,因此可以直接用作计算交叉熵的基础事实(目标)。但是,在应用交叉熵之前,必须在预测输出上逐像素地应用softmax,因为每个像素可以属于我们的任何目标类别。
焦点损失
RetinaNet论文中引入的Focal Loss 建议升级到标准的交叉熵损失,以便在极端不平衡的情况下使用。
考虑标准交叉熵损失方程的图,如下所示(蓝色)。即使在我们的模型对像素类(例如80%)非常有信心的情况下,它也有一个有形的损失值(这里,大约0.3)。另一方面,gamma=2当模型对一个类有信心时,Focal Loss(紫色,with )不会对模型进行如此大的惩罚(即,对于80%的置信度,损失几乎为0)。
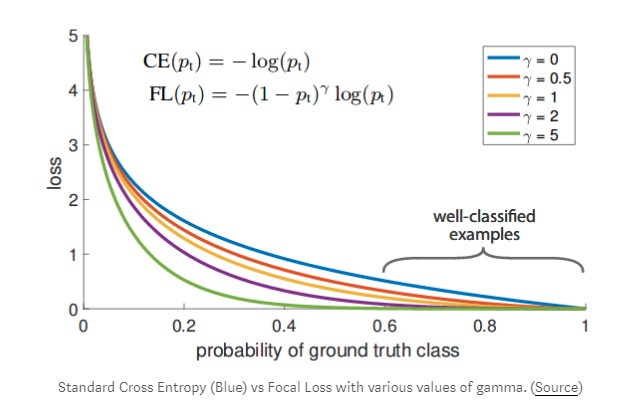
让我们通过一个直观的例子来探讨为什么这是重要的。假设我们有一个10000像素的图像,只有两个类:背景类(单热形式为0)和目标类(单热形式为1)。让我们假设97%的图像是背景,3%的图像是目标。现在,假设我们的模型80%确定背景像素,但只有30%确定目标类像素。
在使用交叉熵的同时,由于背景像素引起的损失(97% of 10000) * 0.3等于等于2850 并且由于目标像素引起的损失等于(3% of 10000) * 1.2等于360。显然,由于更自信的阶级所造成的损失占主导地位,并且模型学习目标阶层的动机很小。相比之下,由于焦点损失,背景像素引起的损失等于(97% of 10000) * 00.这使得模型能够更好地学习目标类。
骰子损失
骰子丢失是另一种流行的损失函数,用于具有极端类不平衡的语义分割问题。在V-Net论文中引入,Dice Loss用于计算预测类和地面实况类之间的重叠。骰子系数(D)表示如下:
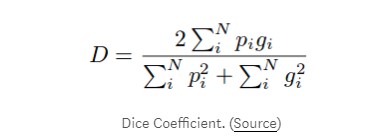
我们的目标是最大化预测真实类和基础真值类之间的重叠(即最大化骰子系数)。因此,我们通常最小化(1-D) 以获得相同的目标,因为大多数ML库仅提供最小化的选项。
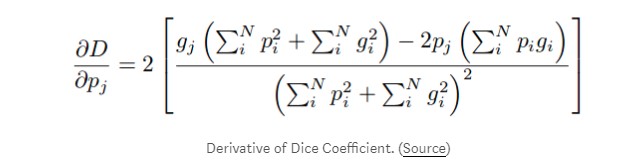
尽管Dice Loss对于具有类不平衡的样本效果很好,但计算其导数的公式(如上所示)在分母中具有平方项。当这些值很小时,我们可能会得到很大的梯度,导致训练不稳定。
应用
语义分段用于各种现实生活中。以下是语义分段的一些重要用例。
自动驾驶
语义分割用于识别车道,车辆,人和其他感兴趣的对象。结果用于做出明智的决定以正确地引导车辆。

对自动驾驶汽车的一个限制是性能必须是实时的。上述问题的解决方案是将GPU与车辆一起本地集成。为了增强上述解决方案的性能,可以使用更轻(低参数)的神经网络,或者可以实现在边缘上拟合神经网络的技术。
医学图像分割
语义分割用于识别医学扫描中的显着元素。识别肿瘤等异常特别有用。算法的准确性和低召回率对于这些应用来说非常重要。

我们还可以自动执行不太重要的操作,例如从3D语义分段扫描估计器官的体积。
场景理解
语义分段通常构成更复杂任务的基础,例如场景理解和视觉问答(VQA)。场景图或标题通常是场景理解算法的输出
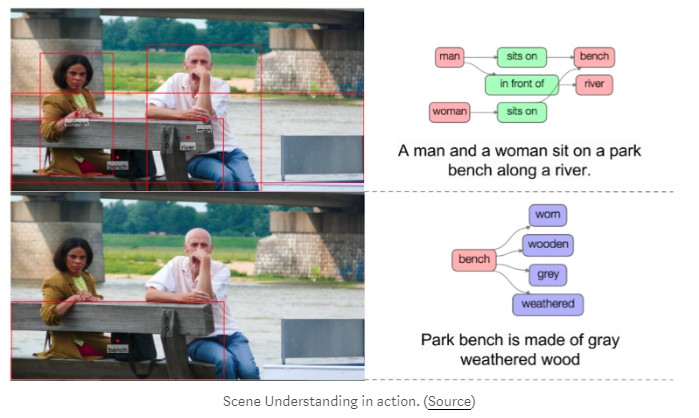
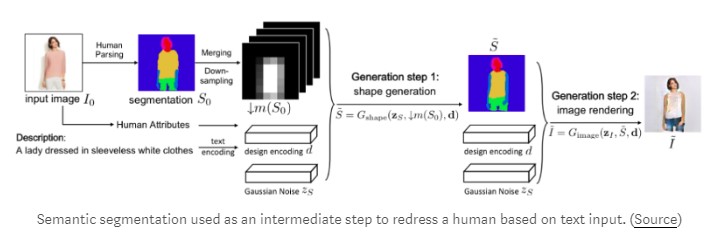
时尚产业
语义分割在时装业中用于从图像中提取服装项目以提供来自零售商店的类似建议。更高级的算法可以“重新装扮”图像中的特定服装项目。
卫星(或空中)图像处理
语义分割用于从卫星图像中识别陆地类型。典型的使用案例涉及分割水体以提供准确的地图信息。其他高级用例包括绘制道路,识别作物类型,识别免费停车位等。

结论
深度学习极大地增强和简化了语义分割算法,并为在现实生活中应用程序的更广泛采用铺平了道路。本博客中列出的概念并非详尽无遗,因为研究团队不断努力提高这些算法的准确性和实时性。然而,这篇博客介绍了这些算法的一些流行变体及其实际应用。