一、何为跳跃表
我们知道二叉搜索算法能够高效的查询数据,但是需要一块连续的内存,而且增删改效率很低。
跳表,是基于链表实现的一种类似“二分”的算法。在原链表的基础上提出多层索引 它可以快速的实现增,删,改,查操作。

当我们要在该单链表中查找某个数据的时候需要的时间复杂度为O(n).
怎么提高查询效率呢?如果我们给该单链表加一级索引,将会改善查询效率。
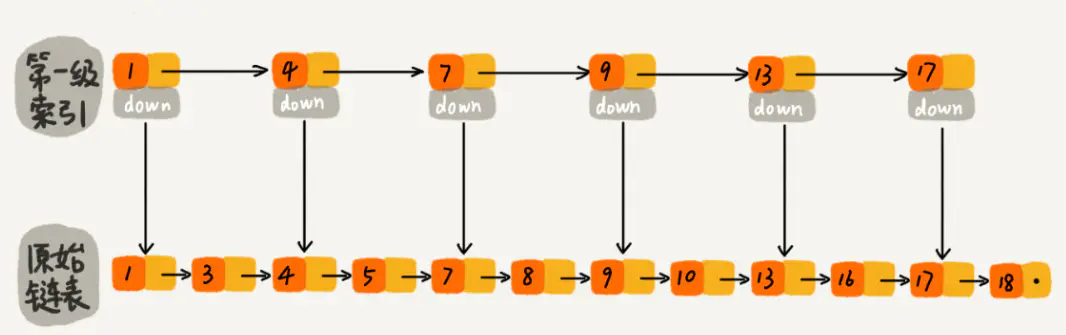
如图所示,当我们每隔一个节点就提取出来一个元素到上一层,把这一层称作索引,其中的down指针指向原始链表。
当我们查找元素16的时候,从上层到下层依次开始查找,单链表需要比较10次,而加过索引的两级链表只需要比较7次。当数据量增大到一定程度的时候,效率将会有显著的提升。
如果我们再加多几级索引的话,效率将会进一步提升。这种链表加多级索引的结构,就叫做跳表。
当我们查找元素16的时候,从上层到下层依次开始查找,单链表需要比较10次,而加过索引的两级链表只需要比较7次。当数据量增大到一定程度的时候,效率将会有显著的提升。
如果我们再加多几级索引的话,效率将会进一步提升。这种链表加多级索引的结构,就叫做跳表。
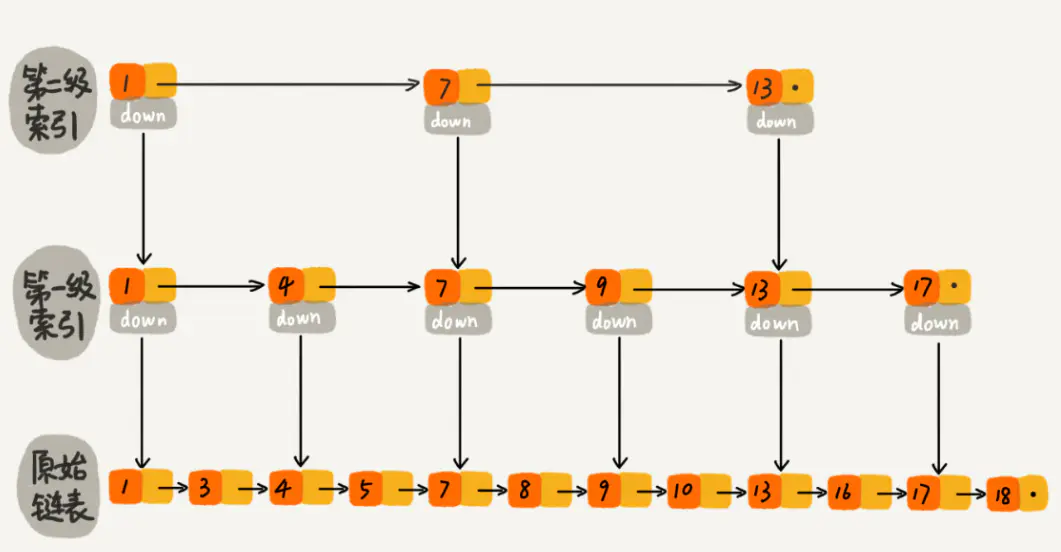
跳表的查询时间复杂度可以达到O(logn)
二、查询
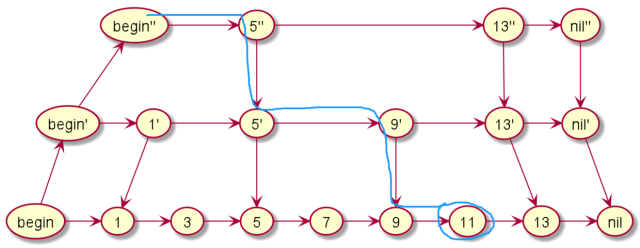
假如我们要查询11,那么我们从最上层出发,发现下一个是5,再下一个是13,已经大于11,所以进入下一层,下一层的一个是9,查找下一个,下一个又是13,再次进入下一层。最终找到11。
跳表的查询时间复杂度可以达到O(logn)
三、高效的动态插入和删除
跳表也可以实现高效的动态更新,定位到要插入或者删除数据的位置需要的时间复杂度为O(logn).
在插入的时候,我们需要考虑将要插入的数据也插入到索引中去。在这里使用的策略是通过随机函数生成一个随机数K,然后将要插入的数据同时插入到k级以下的每级索引中。
在插入的时候,我们需要考虑将要插入的数据也插入到索引中去。在这里使用的策略是通过随机函数生成一个随机数K,然后将要插入的数据同时插入到k级以下的每级索引中。
参考:https://www.jianshu.com/p/43039adeb122
参考:https://baijiahao.baidu.com/s?id=1633338040568845450&wfr=spider&for=pc