采用模板类实现的好处是,不用拘泥于特定的数据类型。就像活字印刷术,制定好模板,就可以批量印刷,比手抄要强多少倍!
此处不具体介绍泛型编程,还是着重叙述链表的定义和相关操作。
链表结构定义
定义单链表的结构可以有4方式。如代码所示。
本文采用的是第4种结构类型
1、复合类:在Node类中定义友元的方式,使List类可以访问结点的私有成员
*************************************************************************/
class LinkNode
{
friend class LinkList;
private:
int data;
LinkNode *next;
};
class LinkList
{
public:
//单链表具体操作
private:
LinkNode *head;
};
/*************************************************************************
2、嵌套类:在List内部定义Node类,但是Node的数据成员放在public部分,使List
和Node均可以直接访问Node的成员
*************************************************************************/
class LinkList
{
public:
//单链表具体操作
private:
class LinkNode
{
public:
int data;
LinkNode *next;
};
LinkNode *head;
};
/*************************************************************************
3、继承:在Node类中把成员定义为protected,然后让List继承Node类,这样就可以
访问Node类的成员了。
*************************************************************************/
class LinkNode
{
protected:
int data;
LinkNode *next;
};
class LinkList : public LinkNode
{
public:
//单链表具体操作
private:
LinkNode *head;
};
/*************************************************************************
4、直接用struct定义Node类,因为struct的成员默认为公有数据成员,所以可直接
访问(struct也可以指定保护类型)。
*************************************************************************/
struct LinkNode
{
int data;
LinkNode *next;
};
class LinkList
{
public:
//单链表具体操作
private:
LinkNode *head;
};
单链表的模板类定义
使用模板类需要注意的一点是template<class T>必须定义在同一个文件,否则编译器会无法识别。
如果在.h中声明类函数,但是在.cpp中定义函数具体实现, 会出错。所以,推荐的方式是直接在.h中定义。
template<class T>
struct LinkNode
{
T data;
LinkNode<T> *next;
LinkNode(LinkNode<T> *ptr = NULL){next = ptr;}
LinkNode(const T &item, LinkNode<T> *ptr = NULL)
//函数参数表中的形参允许有默认值,但是带默认值的参数需要放后面
{
next = ptr;
data = item;
}
};
/* 带头结点的单链表定义 */
template<class T>
class LinkList
{
public:
//无参数的构造函数
LinkList(){head = new LinkNode<T>;}
//带参数的构造函数
LinkList(const T &item){head = new LinkNode<T>(item);}
//拷贝构造函数
LinkList(LinkList<T> &List);
//析构函数
~LinkList(){Clear();}
//重载函数:赋值
LinkList<T>& operator=(LinkList<T> &List);
//链表清空
void Clear();
//获取链表长度
int Length() const;
//获取链表头结点
LinkNode<T>* GetHead() const;
//设置链表头结点
void SetHead(LinkNode<T> *p);
//查找数据的位置,返回第一个找到的满足该数值的结点指针
LinkNode<T>* Find(T &item);
//定位指定的位置,返回该位置上的结点指针
LinkNode<T>* Locate(int pos);
//在指定位置pos插入值为item的结点,失败返回false
bool Insert(T &item, int pos);
//删除指定位置pos上的结点,item就是该结点的值,失败返回false
bool Remove(int pos, T &item);
//获取指定位置pos的结点的值,失败返回false
bool GetData(int pos, T &item);
//设置指定位置pos的结点的值,失败返回false
bool SetData(int pos, T &item);
//判断链表是否为空
bool IsEmpty() const;
//打印链表
void Print() const;
//链表排序
void Sort();
//链表逆置
void Reverse();
private:
LinkNode<T> *head;
};
定位位置
/* 返回链表中第pos个元素的地址,如果pos<0或pos超出链表最大个数返回NULL */ template<class T> LinkNode<T>* LinkList<T>::Locate(int pos) { int i = 0; LinkNode<T> *p = head; if (pos < 0) return NULL; while (NULL != p && i < pos) { p = p->next; i++; } return p; }
插入结点
单链表插入结点的处理如图
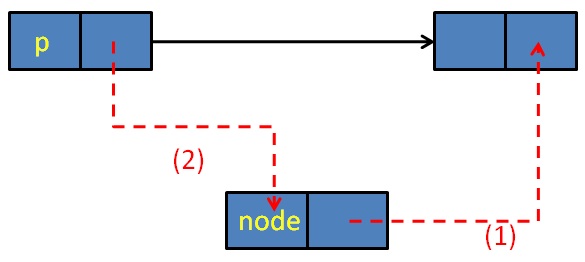
图:单链表插入操作
要在p结点后插入一个新结点node,(1)要让node的next指针指向p的next结点;(2)再让p的next指向node结点(即断开图中的黑色实线,改成红色虚线指向node)
接下来:node->next = p->next; p->next = node;
template<class T> bool LinkList<T>::Insert(T &item, int pos) { LinkNode<T> *p = Locate(pos); if (NULL == p) return false; LinkNode<T> *node = new LinkNode<T>(item); if (NULL == node) { cerr << "分配内存失败!" << endl; exit(1); } node->next = p->next; p->next = node; return true; }
删除结点
删除结点的处理如图:
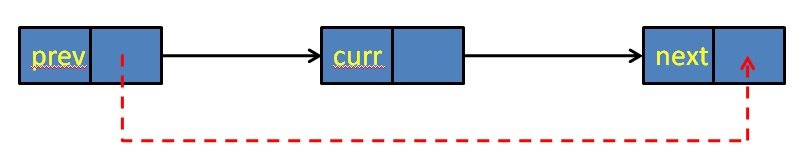
图:单链表删除
删除pos位置的结点,如果这个位置不存在结点,则返回false;
如果找到对应结点,则通过实参item输出要删除的结点的数值, 然后删除结点并返回true。
template<class T> bool LinkList<T>::Remove(int pos, T &item) { LinkNode<T> *p = Locate(pos); if (NULL == p || NULL == p->next) return false; LinkNode<T> *del = p->next; p->next = del->next; item = del->data; delete del; return true; }
清空链表
遍历整个链表,每次head结点的next指针指向的结点,直到next指针为空。
最后保留head结点。
template<class T> void LinkList<T>::Clear() { LinkNode<T> *p = NULL; //遍历链表,每次都删除头结点的next结点,最后保留头结点 while (NULL != head->next) { p = head->next; head->next = p->next; //每次都删除头结点的next结点 delete p; } }
求链表长度和打印链表
着两个功能的实现非常相近,都是遍历链表结点,不赘述。
template<class T> void LinkList<T>::Print() const { int count = 0; LinkNode<T> *p = head; while (NULL != p->next) { p = p->next; std::cout << p->data << " "; if (++count % 10 == 0) //每隔十个元素,换行打印 cout << std::endl; } } template<class T> int LinkList<T>::Length() const { int count = 0; LinkNode<T> *p = head->next; while (NULL != p) { p = p->next; ++count; } return count; }
单链表倒置
单链表的倒置处理如图:
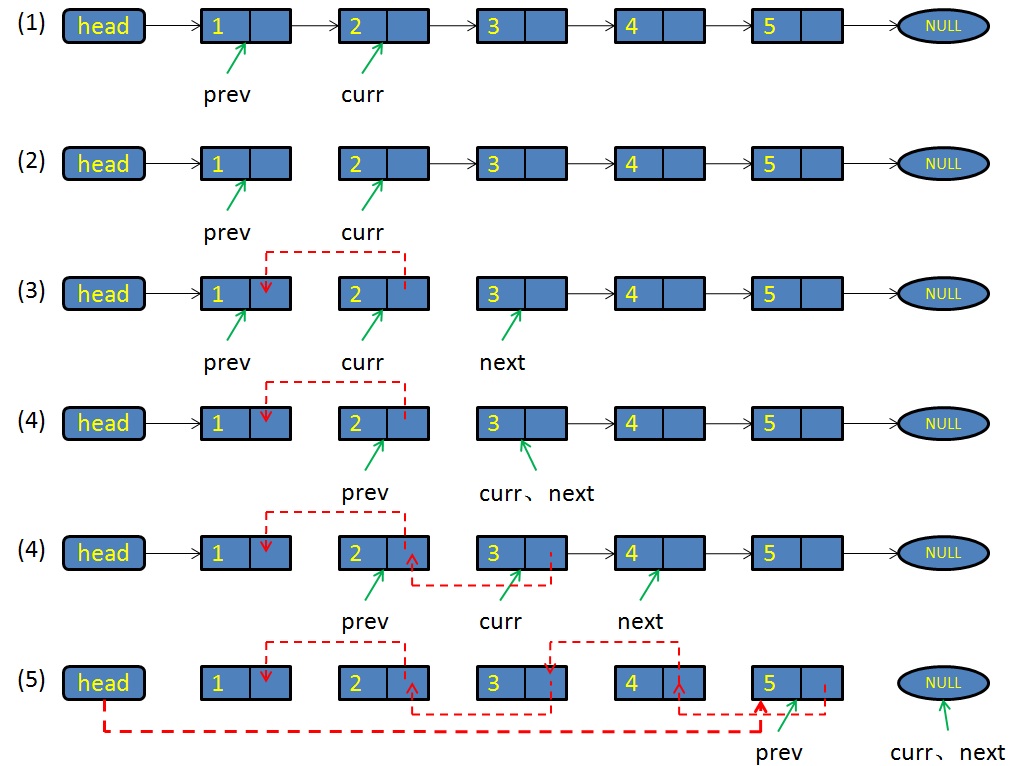
图:单链表倒置
(1)初始状态:prev = head->next; curr = prev->next;
(2)让链表的第一个结点的next指针指向空
(3)开始进入循环处理,让next指向curr结点的下一个结点;再让curr结点的next指针指向prev。即:next = curr->next; curr->next = prev;
(4)让prev、curr结点都继续向后移位。即:prev = curr; curr = next;
(5)重复(3)、(4)动作,直到curr指向空。这时循环结束,让haed指针指向prev,此时的prev是倒置后的第一个结点。即:head->next = prev;
template<class T> void LinkList<T>::Reverse() { LinkNode<T> *pre = head->next; LinkNode<T> *curr = pre->next; LinkNode<T> *next = NULL; head->next->next = NULL; while (curr) { next = curr->next; curr->next = pre; pre = curr; curr = next; } head->next = pre; }