前言
在前端开发中,缓存有利于加快网页的加载速度,同时缓存能够被反复利用,所以可以减少流量和带宽的开销。
缓存的分类有很多种,CDN缓存、数据库缓存、代理服务器缓存和浏览器缓存。本篇将来讲解一下Web开发中的浏览器缓存。这个在实际开发环境中往往也会被问到,或者使用到。如何去准确认清楚缓存的概念,是前端必须要去学习的
浏览器的缓存问题,主要指的是http的缓存——即协议层。而h5新增的storage和数据库缓存,那是应用层缓存,并不被计入本篇的分析内容里面。下面我们正式开始来进行缓存的分析。
正文
有时当你使用chrome开发者工具的network发现了细节:

这是怎么一回事呢,当然这是上述说的缓存方式,虽然这两个看起来都是从缓存中读取,但还是有一些不一样的!
webkit资源的分类
webkit的资源分类主要分为两大类:主资源和派生资源。
http状态码
200 from memory cache //不访问服务器,直接读缓存,从内存中读取缓存。此时的数据时缓存到内存中的,当kill进程后,也就是浏览器关闭以后,数据将不存在。但是这种方式只能缓存派生资源。一般脚本、字体、图片会存在内存当中。 200 from disk cache //不访问服务器,直接读缓存,从磁盘中读取缓存,当kill进程时,数据还是存在。这种方式也只能缓存派生资源,一般是css
200 资源大小数值 //从服务器下载最新资源 304 Not Modified //访问服务器,发现数据没有更新,服务器返回此状态码(不返回资源)。然后从缓存中读取数据。
一般样式表会缓存在磁盘中,不会缓存到内存中,因为css样式加载一次即可渲染出页面。但是脚本可能会随时执行,如果把脚本存在磁盘中,在执行时会把该脚本从磁盘中提取到缓存中来,这样的IO开销比较大,有可能会导致浏览器失去响应。
几种状态的执行顺序
现加载一种资源(例如:图片):访问-> 200OK -> 退出浏览器 -> 再进来-> 200(from disk cache) -> 刷新 -> 200(from memory cache)
三级缓存原理
- 先去内存看,如果有,直接加载
- 如果内存没有,择取硬盘获取,如果有直接加载
- 如果硬盘也没有,那么就进行网络请求
- 加载到的资源缓存到硬盘和内存
浏览器中的缓存又是什么
缓存即是离线的资源;对于浏览器开发者而言,缓存不是我们用浏览器下载了什么, 而是比如我们通过浏览器打开过一个网页,这个网页里面所包含的资源(图片、css文件、js文件等)在无感知的情况下,缓存在了本地;
浏览器缓存,有时候我们需要他,因为他可以提高网站性能和浏览器速度,提高网站性能。但是有时候我们又不得不清除缓存,因为缓存可能误事,出现一些错误的数据。像股票类网站实时更新等,这样的网站是不要缓存的,像有的网站很少更新,有缓存还是比较好的。
览器通常会将常用资源缓存在你的个人电脑的磁盘和内存中。如Chrome浏览器的缓存存放位置就在:UsersYour_AccountAppDataLocalGoogleChromeUser DataDefault中的Cache文件夹和Media Cache文件夹中。
浏览器中缓存的步骤是什么样的
我们知道浏览器会有缓存,那么是我们每次去打开之前已经打开过的网站,都是用的缓存吗?当然不是!!!浏览器有一套协议来管理什么时候需要去请求服务器,什么时候使用本地缓存;这套协议就叫做缓存协议(缓存机制);
一起来看一下这套机制的流程是什么样的:
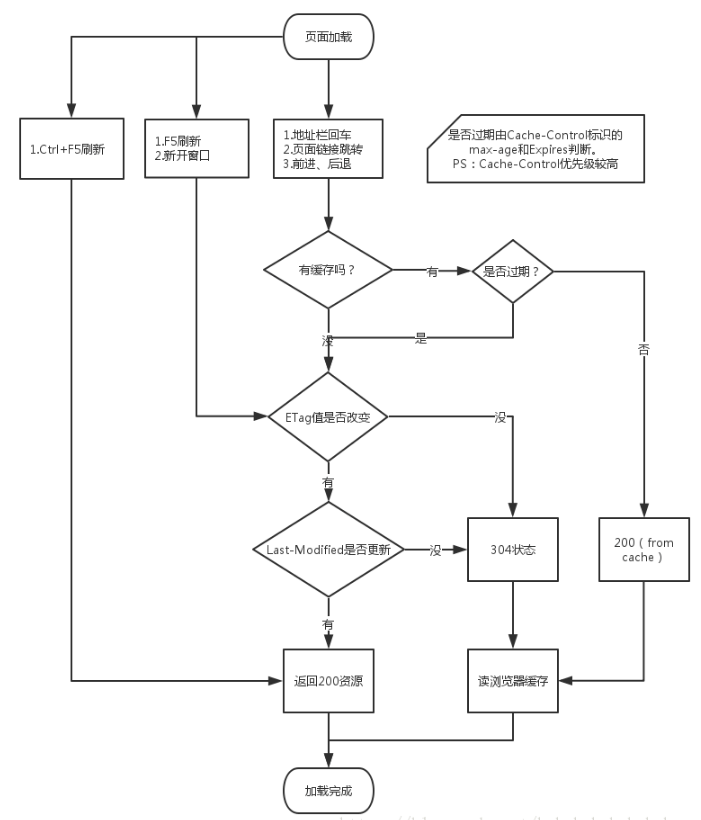
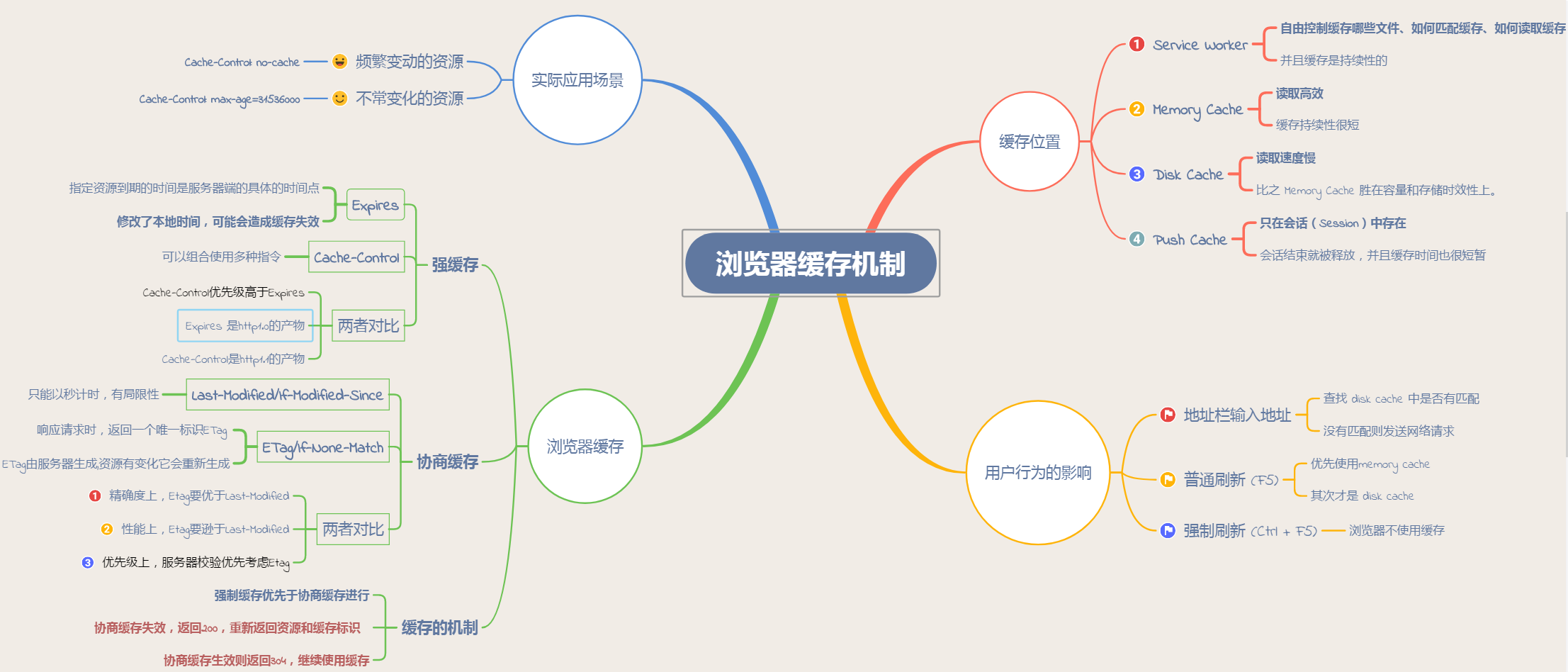
http header:(与缓存有关的请求头部)
max-age //web中的文件被用户访问(请求)后的存活时间,是个相对的值,相对Request_time(请求时间)
Expires //Expires指定的时间根据服务器配置可能有两种:(GMT时间),文件最后访问时间,文件绝对修改时间
last-modified //WEB 服务器认为对象的最后修改时间,比如文件的最后修改时间,动态页面的最后产生时间
ETag //对象(比如URL)的标志值,就一个对象而言,文件被修改,Etag也会修改
Cache-Control //简单理解,强缓存,前两者来验证资源新鲜度,后两者来验证资源的有效值。
注:如果max-age和Expires同时存在,则被Cache-Control的max-age覆盖,因为后者优先级更高
注:除了Expires 和Cache-Control 两个特性的缓存可以让browser完全不发请求的话,别忘了还有一个html5的新特性 Application Cache。
http报文中与缓存相关的首部字段
1. 通用首部字段(就是请求报文和响应报文都能用上的字段)

2. 请求首部字段
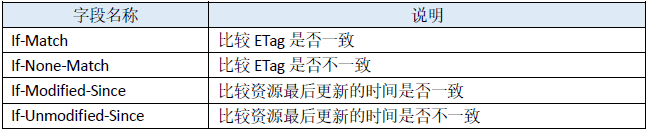
3. 响应首部字段

4. 实体首部字段

石器时代的缓存方式
在 http1.0 时代,给客户端设定缓存方式可通过两个字段——“Pragma”和“Expires”来规范。虽然这两个字段早可抛弃,但为了做http协议的向下兼容,你还是可以看到很多网站依旧会带上这两个字段。
1. Pragma
当该字段值为“no-cache”的时候(事实上现在RFC中也仅标明该可选值),会知会客户端不要对该资源读缓存,即每次都得向服务器发一次请求才行。
Pragma属于通用首部字段,在客户端上使用时,常规要求我们往html上加上这段meta元标签(而且可能还得做些hack放到body后面去):
<meta http-equiv="Pragma" content="no-cache">
它告诉浏览器每次请求页面时都不要读缓存,都得往服务器发一次请求才行。
BUT!!! 事实上这种禁用缓存的形式用处很有限:
1. 仅有IE才能识别这段meta标签含义,其它主流浏览器仅能识别“Cache-Control: no-store”的meta标签(见出处)。
2. 在IE中识别到该meta标签含义,并不一定会在请求字段加上Pragma,但的确会让当前页面每次都发新请求(仅限页面,页面上的资源则不受影响)。
做了测试后发现也的确如此,这种客户端定义Pragma的形式基本没起到多少作用。
不过如果是在响应报文上加上该字段就不一样了:
如上图红框部分是再次刷新页面时生成的请求,这说明禁用缓存生效,预计浏览器在收到服务器的Pragma字段后会对资源进行标记,禁用其缓存行为,进而后续每次刷新页面均能重新发出请求而不走缓存。
2. Expires
有了Pragma来禁用缓存,自然也需要有个东西来启用缓存和定义缓存时间,对http1.0而言,Expires就是做这件事的首部字段。
Expires的值对应一个GMT(格林尼治时间),比如“Mon, 22 Jul 2002 11:12:01 GMT”来告诉浏览器资源缓存过期时间,如果还没过该时间点则不发请求。
在客户端我们同样可以使用meta标签来知会IE(也仅有IE能识别)页面(同样也只对页面有效,对页面上的资源无效)缓存时间:
<meta http-equiv="expires" content="mon, 18 apr 2016 14:30:00 GMT">
如果希望在IE下页面不走缓存,希望每次刷新页面都能发新请求,那么可以把“content”里的值写为“-1”或“0”。
注意的是该方式仅仅作为知会IE缓存时间的标记,你并不能在请求或响应报文中找到Expires字段。
如果是在服务端报头返回Expires字段,则在任何浏览器中都能正确设置资源缓存的时间:
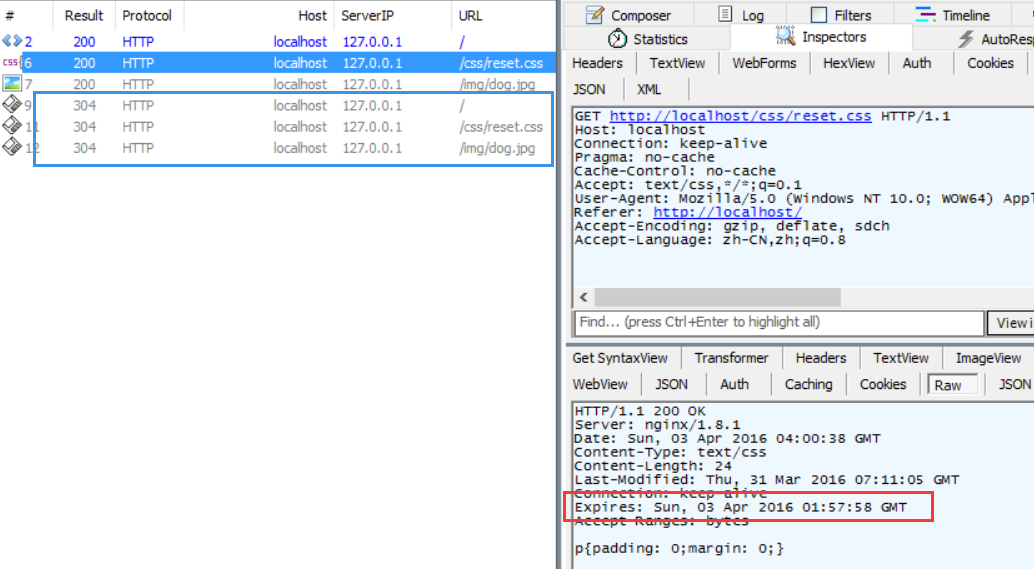
在上图里,缓存时间设置为一个已过期的时间点(见红框),则刷新页面将重新发送请求(见蓝框)
那么如果Pragma和Expires一起上阵的话,听谁的?我们试一试就知道了:
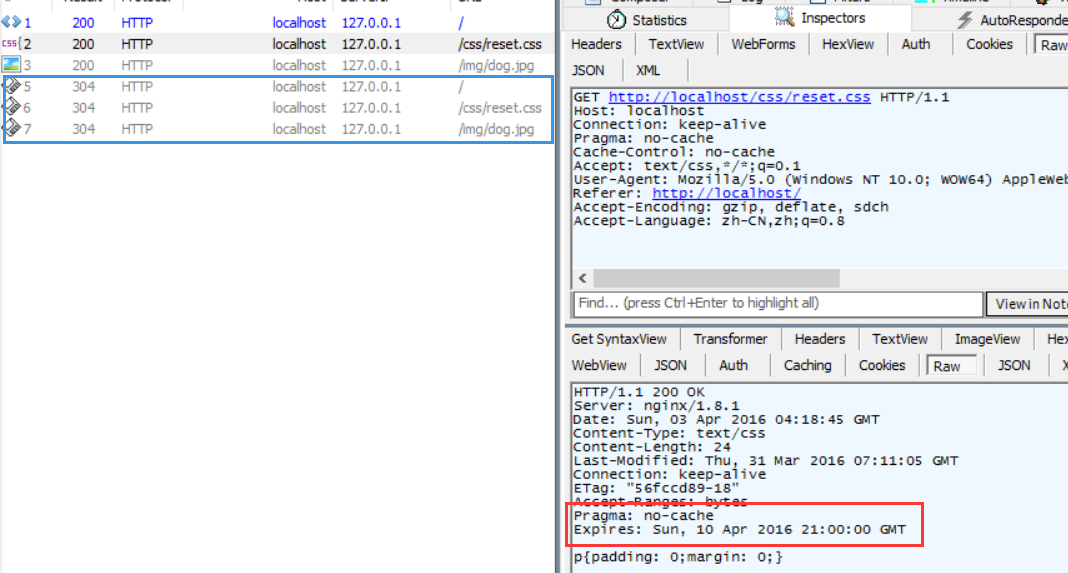
我们通过Pragma禁用缓存,又给Expires定义一个还未到期的时间(红框),刷新页面时发现均发起了新请求(蓝框),这意味着Pragma字段的优先级会更高。
BUT,响应报文中Expires所定义的缓存时间是相对服务器上的时间而言的,如果客户端上的时间跟服务器上的时间不一致(特别是用户修改了自己电脑的系统时间),那缓存时间可能就没啥意义了。
Cache-Control
针对上述的“Expires时间是相对服务器而言,无法保证和客户端时间统一”的问题,http1.1新增了 Cache-Control 来定义缓存过期时间,若报文中同时出现了 Pragma、Expires 和 Cache-Control,会以 Cache-Control 为准。
Cache-Control也是一个通用首部字段,这意味着它能分别在请求报文和响应报文中使用。在RFC中规范了 Cache-Control 的格式为:
"Cache-Control" ":" cache-directive
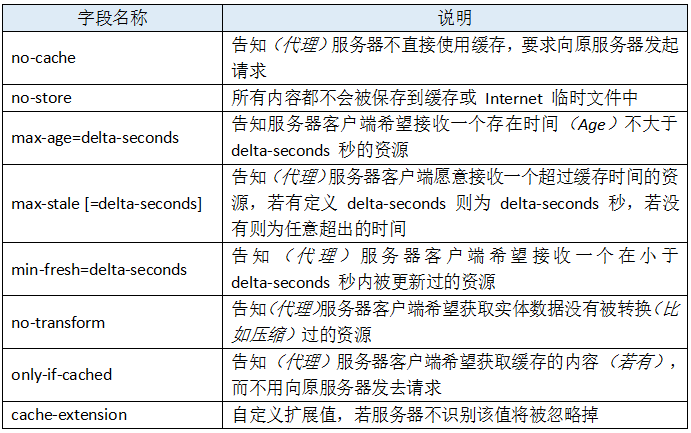
作为请求首部时,cache-directive 的可选值有:
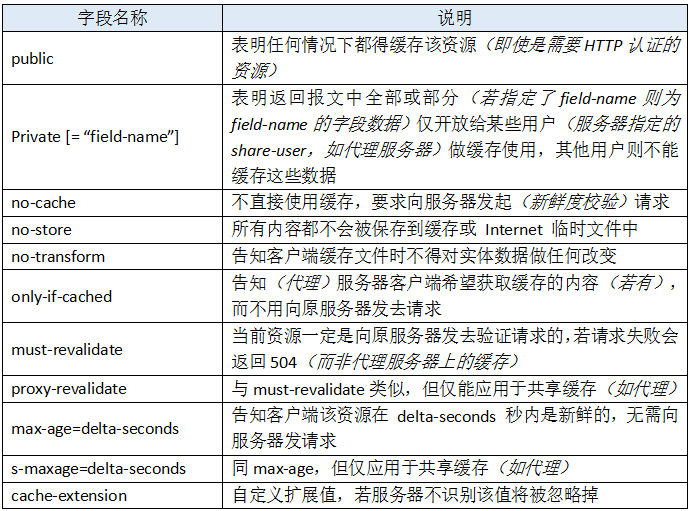
作为响应首部时,cache-directive 的可选值有:
我们依旧可以在HTML页面加上meta标签来给请求报头加上 Cache-Control 字段:
另外 Cache-Control 允许自由组合可选值,例如:
Cache-Control: max-age=3600, must-revalidate
它意味着该资源是从原服务器上取得的,且其缓存(新鲜度)的有效时间为一小时,在后续一小时内,用户重新访问该资源则无须发送请求。
当然这种组合的方式也会有些限制,比如 no-cache 就不能和 max-age、min-fresh、max-stale 一起搭配使用。
组合的形式还能做一些浏览器行为不一致的兼容处理。例如在IE我们可以使用 no-cache 来防止点击“后退”按钮时页面资源从缓存加载,但在 Firefox 中,需要使用 no-store 才能防止历史回退时浏览器不从缓存中去读取数据,故我们在响应报头加上如下组合值即可做兼容处理:
Cache-Control: no-cache, no-store
缓存校验字段
上述的首部字段均能让客户端决定是否向服务器发送请求,比如设置的缓存时间未过期,那么自然直接从本地缓存取数据即可(在chrome下表现为200 from cache),若缓存时间过期了或资源不该直接走缓存,则会发请求到服务器去。
我们现在要说的问题是,如果客户端向服务器发了请求,那么是否意味着一定要读取回该资源的整个实体内容呢?
我们试着这么想——客户端上某个资源保存的缓存时间过期了,但这时候其实服务器并没有更新过这个资源,如果这个资源数据量很大,客户端要求服务器再把这个东西重新发一遍过来,是否非常浪费带宽和时间呢?
答案是肯定的,那么是否有办法让服务器知道客户端现在存有的缓存文件,其实跟自己所有的文件是一致的,然后直接告诉客户端说“这东西你直接用缓存里的就可以了,我这边没更新过呢,就不再传一次过去了”。
为了让客户端与服务器之间能实现缓存文件是否更新的验证、提升缓存的复用率,Http1.1新增了几个首部字段来做这件事情。
1. Last-Modified
服务器将资源传递给客户端时,会将资源最后更改的时间以“Last-Modified: GMT”的形式加在实体首部上一起返回给客户端。
客户端会为资源标记上该信息,下次再次请求时,会把该信息附带在请求报文中一并带给服务器去做检查,若传递的时间值与服务器上该资源最终修改时间是一致的,则说明该资源没有被修改过,直接返回304状态码即可。
至于传递标记起来的最终修改时间的请求报文首部字段一共有两个:
⑴ If-Modified-Since: Last-Modified-value
示例为 If-Modified-Since: Thu, 31 Mar 2016 07:07:52 GMT
该请求首部告诉服务器如果客户端传来的最后修改时间与服务器上的一致,则直接回送304 和响应报头即可。
当前各浏览器均是使用的该请求首部来向服务器传递保存的 Last-Modified 值。
⑵ If-Unmodified-Since: Last-Modified-value
告诉服务器,若Last-Modified没有匹配上(资源在服务端的最后更新时间改变了),则应当返回412(Precondition Failed) 状态码给客户端。
当遇到下面情况时,If-Unmodified-Since 字段会被忽略:
- 1. Last-Modified值对上了(资源在服务端没有新的修改);
- 2. 服务端需返回2XX和412之外的状态码;
- 3. 传来的指定日期不合法
Last-Modified 说好却也不是特别好,因为如果在服务器上,一个资源被修改了,但其实际内容根本没发生改变,会因为Last-Modified时间匹配不上而返回了整个实体给客户端(即使客户端缓存里有个一模一样的资源)。
2. ETag
为了解决上述Last-Modified可能存在的不准确的问题,Http1.1还推出了 ETag 实体首部字段。
服务器会通过某种算法,给资源计算得出一个唯一标志符(比如md5标志),在把资源响应给客户端的时候,会在实体首部加上“ETag: 唯一标识符”一起返回给客户端。
客户端会保留该 ETag 字段,并在下一次请求时将其一并带过去给服务器。服务器只需要比较客户端传来的ETag跟自己服务器上该资源的ETag是否一致,就能很好地判断资源相对客户端而言是否被修改过了。
如果服务器发现ETag匹配不上,那么直接以常规GET 200回包形式将新的资源(当然也包括了新的ETag)发给客户端;如果ETag是一致的,则直接返回304知会客户端直接使用本地缓存即可。
那么客户端是如何把标记在资源上的 ETag 传去给服务器的呢?请求报文中有两个首部字段可以带上 ETag 值:
⑴ If-None-Match: ETag-value
示例为 If-None-Match: "56fcccc8-1699"
告诉服务端如果 ETag 没匹配上需要重发资源数据,否则直接回送304 和响应报头即可。
当前各浏览器均是使用的该请求首部来向服务器传递保存的 ETag 值。
⑵ If-Match: ETag-value
告诉服务器如果没有匹配到ETag,或者收到了“*”值而当前并没有该资源实体,则应当返回412(Precondition Failed) 状态码给客户端。否则服务器直接忽略该字段。
If-Match 的一个应用场景是,客户端走PUT方法向服务端请求上传/更替资源,这时候可以通过 If-Match 传递资源的ETag。
需要注意的是,如果资源是走分布式服务器(比如CDN)存储的情况,需要这些服务器上计算ETag唯一值的算法保持一致,才不会导致明明同一个文件,在服务器A和服务器B上生成的ETag却不一样。
如果 Last-Modified 和 ETag 同时被使用,则要求它们的验证都必须通过才会返回304,若其中某个验证没通过,则服务器会按常规返回资源实体及200状态码。
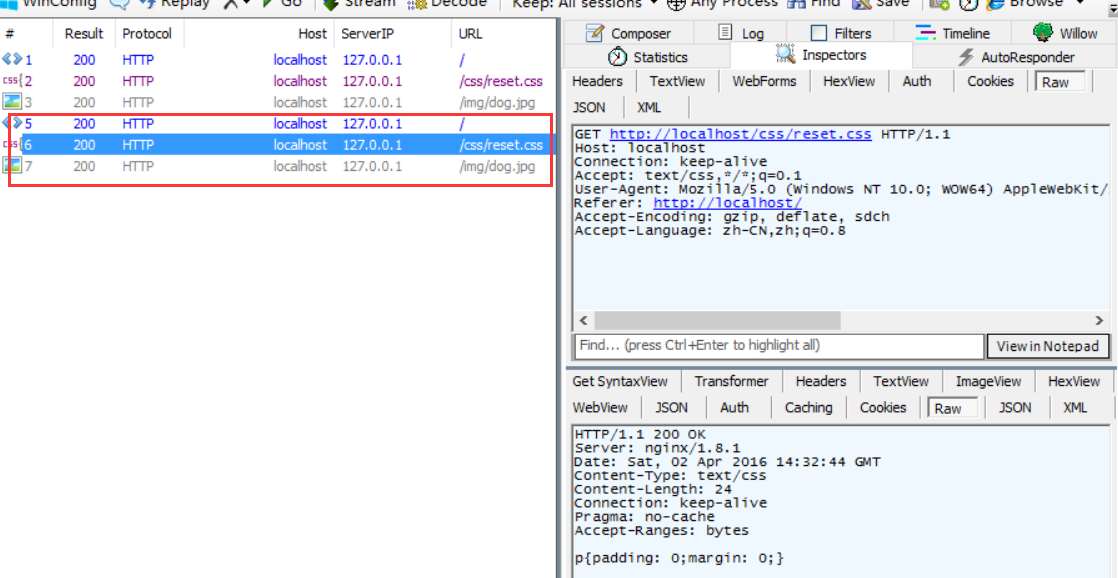
在较新的 nginx 上默认是同时开启了这两个功能的:
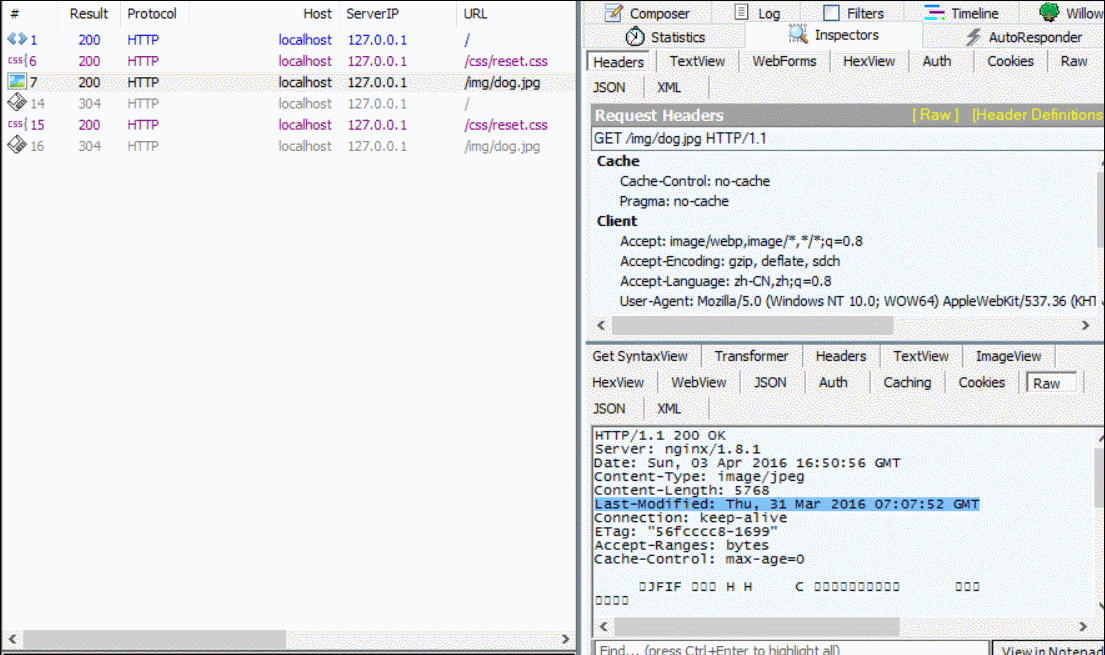
上图的前三条请求是原始请求,接着的三条请求是刷新页面后的新请求,在发新请求之前我们修改了 reset.css 文件,所以它的 Last-Modified 和 ETag 均发生了改变,服务器因此返回了新的文件给客户端(状态值为200)。
而 dog.jpg 我们没有做修改,其Last-Modified 和 ETag在服务端是保持不变的,故服务器直接返回了304状态码让客户端直接使用缓存的 dog.jpg 即可,没有把实体内容返回给客户端(因为没必要)。