事故过程
周二下午得到消息, 希望帮忙分析dump文件.
告知dump大小为42G大小. 一般机器没这么大的内存进行处理.
建议现场上传到百度云盘, 然后我这边进行下载.
时间进度为:
11.57创建的dump
现场打包压缩, 拉取上传百度云盘. 速度大概只有500KB/S.
压缩后文件6G, 时间大约是 4小时左右上传完.
我这边接收到百度云盘已经晚上七点半.
下载耗时大约1h+
九点开始解析, 九点五十五分出结果.
分析情况:
机器内存 96G 16vCPU
mat使用56G内存作为堆区分析dump文件
分析42G的dump文件, 分析结果堆区为27.5G,最大的一个现场使用23.3G的内存.
分析耗时 50min.
OOM的一些分析
dump解析完成只有
在overview 的截面处明显看到有一个巨大的内存对象.
左键最大的内存区域 打开java-basic 然后可以查看thread details
可以看到占用最大内存的区域是什么进程在使用.
因为mat 较为卡顿, 建议将整个堆栈区域复制出来进行分析.
排除掉springboot java 以及类加载器相关的堆栈, 基本上就可以定位到是那一块业务代码
然后根据模块信息找到具体开发, 然后进一步存在具体的业务功能.
针对分析出来的业务功能去查看业务逻辑以及SQL等内容.
OOM的一些分析
注意 OOM 分析的时间跟CPU有关系也跟内存大小和磁盘IO性能有关系.
他分析过程中会形成大量的文件, 作为索引, 如果出现了停止响应, 可以杀掉进程
重新打开待分析的dump文件. 速度会比较快.
分析完threads 之后 可以分析一下 dominator_tree 里面会有响应的堆区内存的详细信息.
需要按照retained heap 的大小进行排序, 打开最大占用内存的线程信息就可以.
一直选中占用内存最大对想进行展开.
我这次例子中 hashmap的对象下面有多个hashmapnode
简单统计了下:
没一个hashmap对象占用 3KB左右的内存空间. 一共先是有800多万个对象. 简单计算为:
3KB*8M=24GB. 很明显就可以将内存使用情况计算出来.
然后继续打开每一个 hashmapnode
发现第一个node的数值都是一样的, 将数据取出.放入第一步业务开发分析出来的SQL.
验证查询展示出来的数据结果集是否是八百万多.
优化的方向
JVM的堆区和GC类型的设置还是需要关注
bean数量的差异,以及实例化对象多寡对内存的要求是不一样的.
堆区,栈区,方法区,以及元数据区,还有直接内存还有系统自己剩余的内存
必须严格控制, 建议关闭swap, 避免swap出现时磁盘读写降低系统性能.
建议服务器必须专用 堆区还是足够大比较好,
足够大的堆区能够容忍部分垃圾代码, 和降低异常产生的频率和次数.
不能因为OOM时dump文件过大就因噎废食. 可以通过改善工具的方式来解决问题
而不是为了好解决问题和不顾及问题发生的频率.
分析优化
突然想这次OOM 可能不全通过dump分析应该也可以定位到.
猜测一下分析方式:
top -Hp threadid 查看占用CPU最多的进程信息
然后jstack -l 将堆栈信息打出
查看堆栈详细内容. 进行排查.
理论上效率应该能快很多.
另外建议现场有高配置的机器. 能够直接分析dump
没有人能够靠眼睛分析出来所有的问题. 必须有趁手的兵器才可以.
优化的方向
left join左连接产生的是笛卡尔积,
即两个10行的表左连接,首先是生成一个10*10行的表,
然后根据on后面的条件筛选符合条件的行。
消除笛卡尔乘积最根本的原因不是在于连接,而是在于唯一ID,
就像学号,一个学生就只有一个学号,学号就是这个学生的唯一标识码。
左连接只是以左边的表为基准,左边的ID和右边ID都是唯一,
就不会产生笛卡尔现象,如果右边有两个ID对应左边一个ID,
就算你是左连接,一样会产生1对多的现象。
SQL连接的简单学习
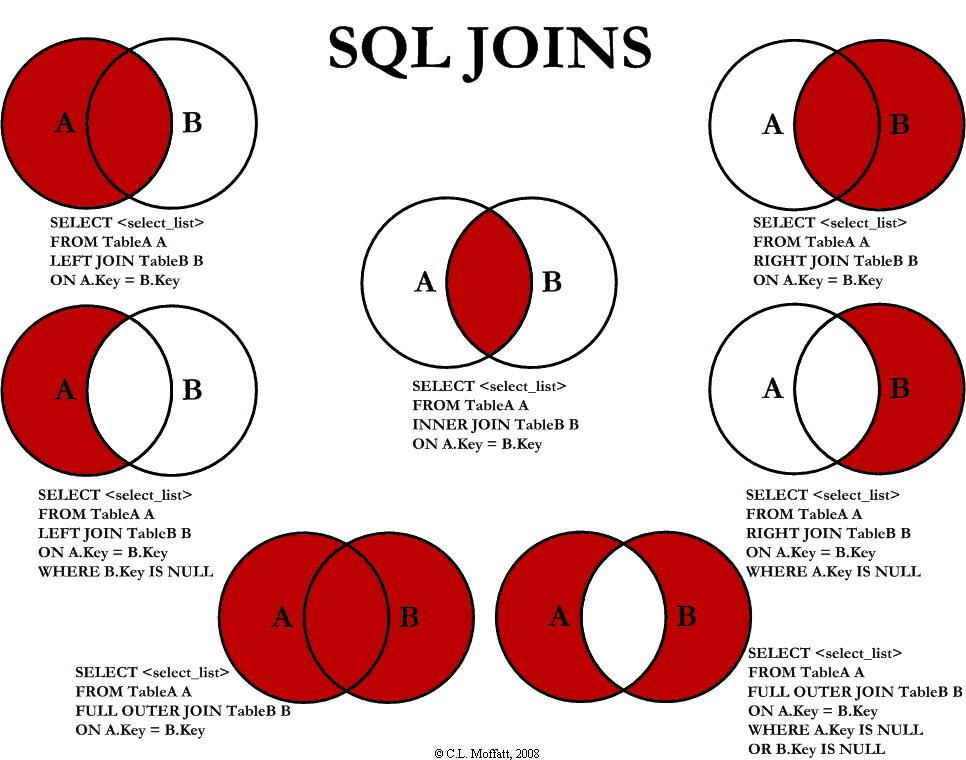
代码排查方面
简单数据的情况下不会有这样的问题.
但是如果连接的 关联条件查询出来的数据不唯一
会导致笛卡尔积,比两个表的数量都放大.
业务SQL的严格准确很重要, 一定不要有笛卡尔积的结果出现.
本次例子里面两个子表 在同一个条件下 各有 2932条数据.
简单的笛卡尔积 就导致了接近 9m 的数据量.
因为查询的结果集字段比较多, 导致一次查询就会使用 24GB的堆区
直接导致OOM