前言
用Java如何设计一个阻塞队列,这个问题是在面滴滴的时候被问到的。当时确实没回答好,只是说了用个List,然后消费者再用个死循环一直去监控list的是否有值,有值的话就处理List里面的内容。回头想想,自己真是一个大傻X,也只有我才会这么设计一个阻塞队列(再说,我这也不是阻塞的队列)。
结果自己面试完之后,也没去总结这部分知识,然后过了一段时间,某教育机构的面试又被问到类似的问题了,只不过是换了一个形式,“请用wait方法和notify方法实现一套有生产者和消费者的这种逻辑”。然后我就又蒙圈了,追悔莫及,为啥我没有去了解一下这部分知识,所以这次我准备好好总结一下这部分内容。
具体实现
如果说实现一个队列,那么一个LinkedList的这种实现了Queue接口的都可以直接使用,或者自己写一个先进先出的Array都可以。
但是要做到阻塞就还需要进行阻塞的实现,就是说当队列是空时,如果再继续从队列中获取数据,将会被阻塞,直到有新的数据入队列才停止阻塞;还有当队列已经满了(到达设置的最大容量),再往队列里添加元素的操作也会被阻塞,直到有数据从队列中被移除。
这里首先要有一个锁,保证同时只能有一个线程执行出队列、同时只能有一个线程执行入队列。而执行出队列和入队列的线程的阻塞和唤醒,是靠wait()方法和notifyAll()方法来实现的。
代码实现如下:
public class MyBlockQueue {
/**
* 队列长度默认为10
*/
private int limit = 10;
private Queue queue = new LinkedList<>();
/**
* 初始化队列容量
* @param limit 队列容量
*/
public MyBlockQueue(int limit){
this.limit = limit;
}
/**
* 入队列
* @param object 队列元素
* @throws InterruptedException
*/
public synchronized boolean push(Object object) throws InterruptedException{
// 如果队列已满,再来添加队列的线程就直接阻塞等待。
while (this.queue.size() == this.limit){
wait();
}
// 如果队列为空了,就唤醒所有阻塞的线程。
if(this.queue.size() == 0){
notifyAll();
}
// 入队
boolean add = this.queue.offer(object);
return add;
}
/**
* 出队列
* @return
* @throws InterruptedException
*/
public synchronized Object pop() throws InterruptedException{
// 如果出队列时,队列为空,则阻塞队列。
while (this.queue.size() == 0){
wait();
}
// 如果队列重新满了之后,唤醒阻塞的所有线程。
if(this.queue.size() == this.limit){
notifyAll();
}
Object poll = this.queue.poll();
return poll;
}
}
Java中阻塞队列的实现
首先我们先来归纳一下,Java中有哪些已经实现好了的阻塞队列:
| 队列 | 描述 |
|---|---|
ArrayBlockingQueue |
基于数组结构实现的一个有界阻塞队列 |
LinkedBlockingQueue |
基于链表结构实现的一个有界阻塞队列 |
PriorityBlockingQueue |
支持按优先级排序的无界阻塞队列 |
DelayQueue |
基于优先级队列(PriorityBlockingQueue)实现的无界阻塞队列 |
SynchronousQueue |
不存储元素的阻塞队列 |
LinkedTransferQueue |
基于链表结构实现的一个无界阻塞队列 |
LinkedBlockingDeque |
基于链表结构实现的一个双端阻塞队列 |
我们这次主要来看一下ArrayBlockingQueue和LinkedBlockingQueue这两个阻塞队列。
在介绍这两个阻塞队列时,先普及两个知识,就是ReentrantLock和Condition的几个方法。因为JDK中的这些阻塞队列加锁时基本上都是通过这两种方式的API来实现的。
ReentrantLock
- lock():加锁操作,如果此时有竞争会进入等待队列中阻塞直到获取锁。
- lockInterruptibly():加锁操作,但是优先支持响应中断。
- tryLock():尝试获取锁,不等待,获取成功返回true,获取不成功直接返回false。
- tryLock(long timeout, TimeUnit unit):尝试获取锁,在指定的时间内获取成功返回true,获取失败返回false。
- unlock():释放锁。
Condition
通常和ReentrantLock一起使用的
- await():阻塞当前线程,并释放锁。
- signal():唤醒一个等待时间最长的线程。
ArrayBlockingQueue
构造方法
首先来看一下ArrayBlockingQueue的初始化方法

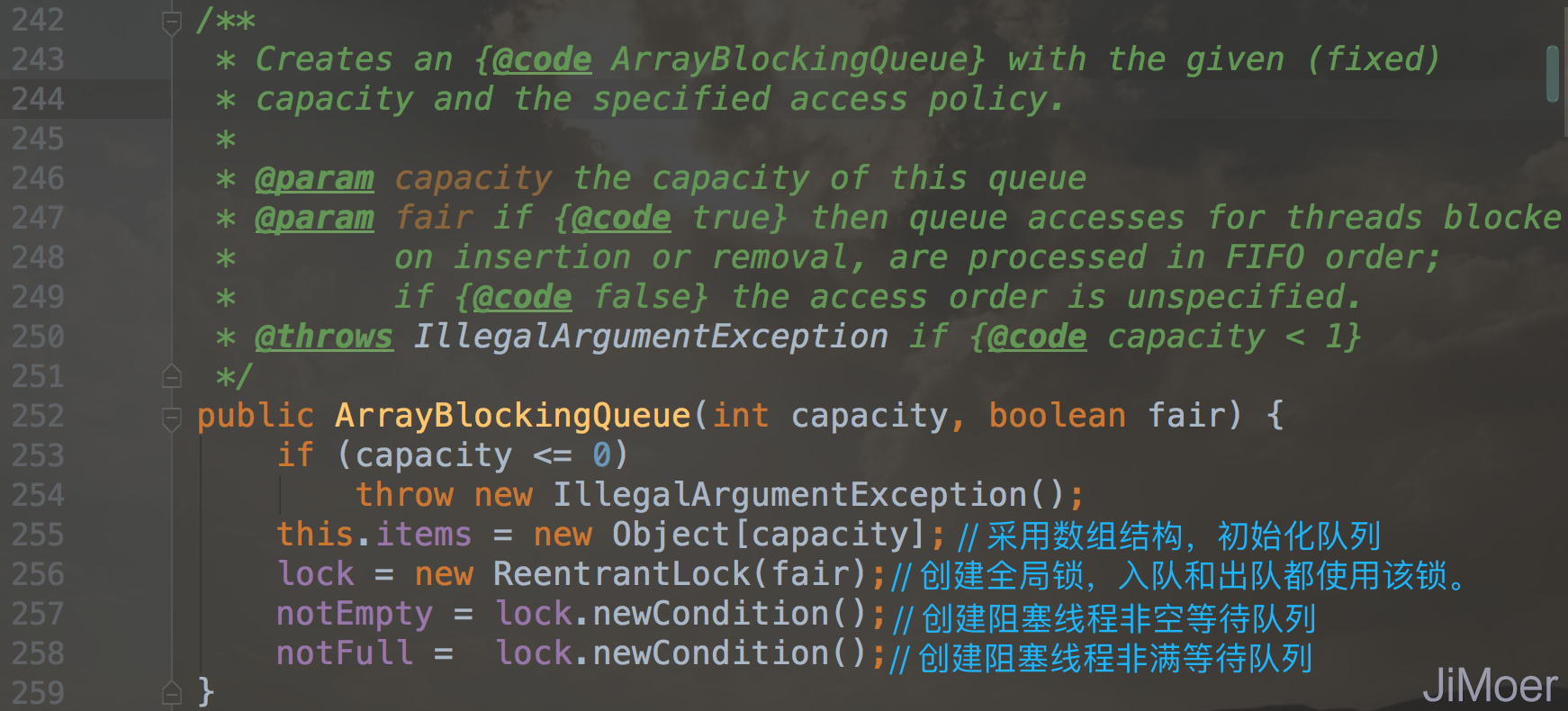
ArrayBlockingQueue是有三个构造方法的,但是都是基于ArrayBlockingQueue(int capacity, boolean fair)来实现的,所以只要了解这一个构造方法即可。
主要是:
- 采用数组结构来初始化队列,并定义队列长度;
- 然后创建全局锁,出队和入队时都要先获取锁再执行操作;
- 创建阻塞线程的非空等待队列;
- 创建阻塞线程的非满等待队列;
入队列
下面来看一下入队列操作

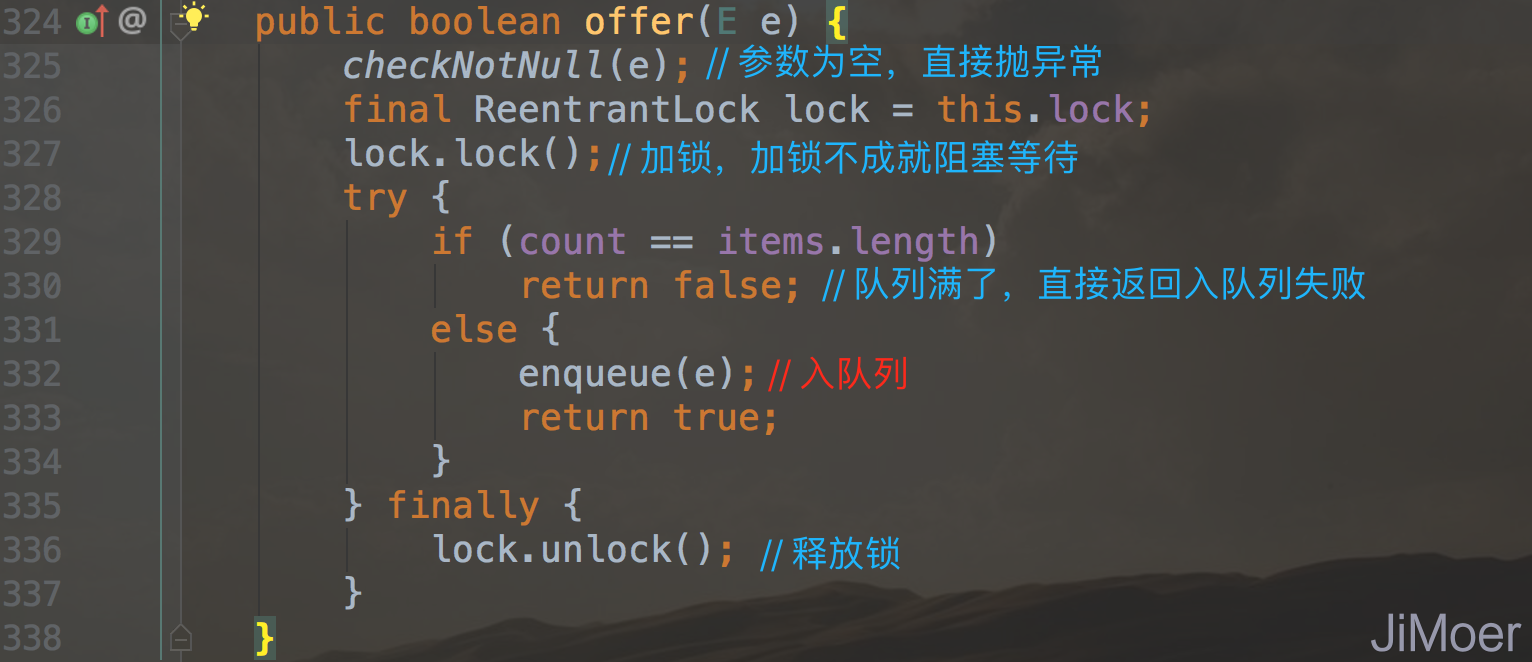
无论put()方法还是offer()方法,在入队列时都是先加锁,然后最终入队列都是调用的enqueue()方法,只不过put方法是阻塞入队列,就是说如果队列已满,入队列的线程会被阻塞,而offer方法则不会阻塞入队列不成功的线程,offer执行入队列不成功的线程直接返回失败,其实还有一个add方法也是入队列,和offer方法一直都是非阻塞入队。
下面来一下enqueue()方法。

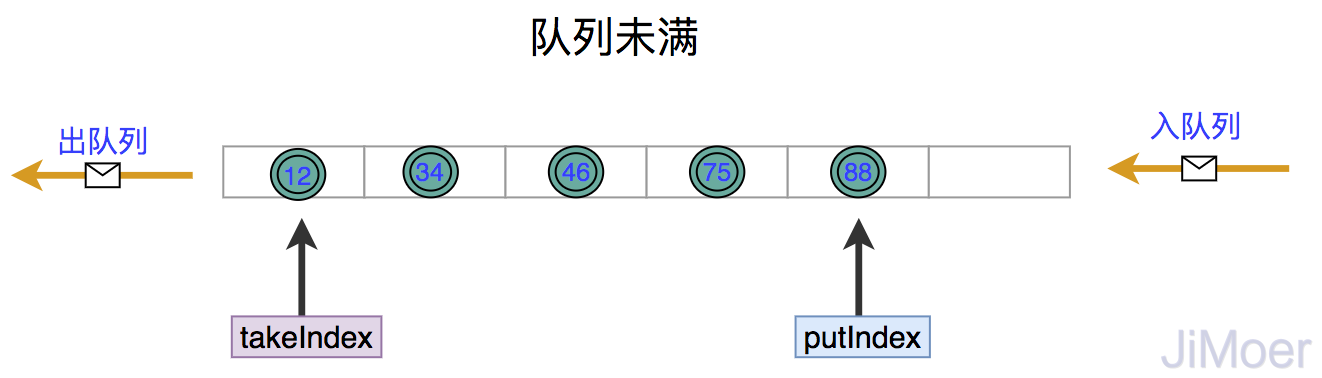
enqueue()方法其实步骤也不复杂,主要是入队列操作是从数组的尾部入,然后出队列是从队列的头部出,这样当队列满了的时候,下一次再入队列时的位置应该从队列的头部开始入了。所以才会有重置putIndex的操作。
如果不能理解可以看下面的图片,正常队列未满时,从数组尾部入队列,头部出队列。
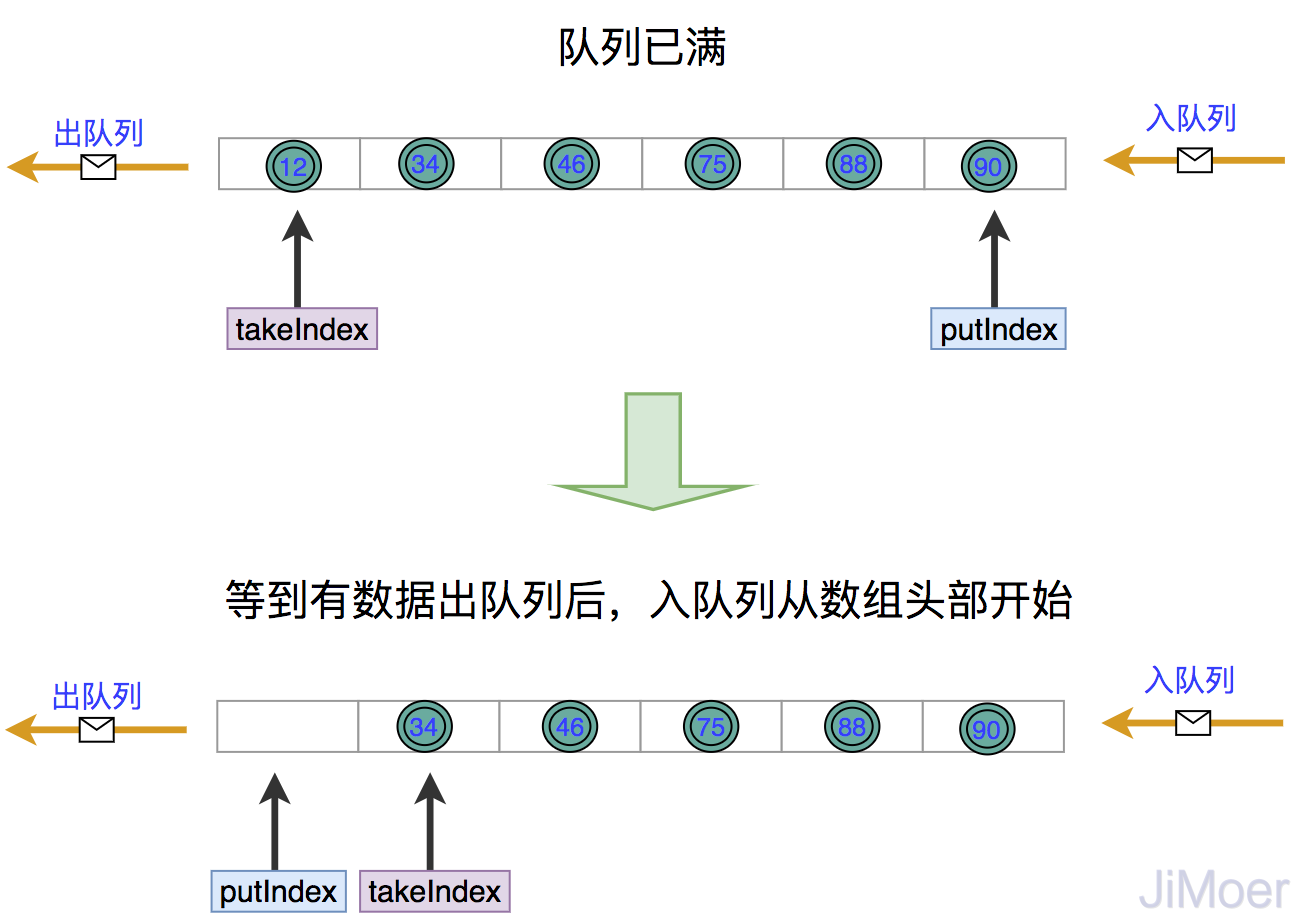
当队列满了之后,入队列就要从数组头部位置开始了。
出队列
下面来看一下ArrayBlockingQueue的出队列方法
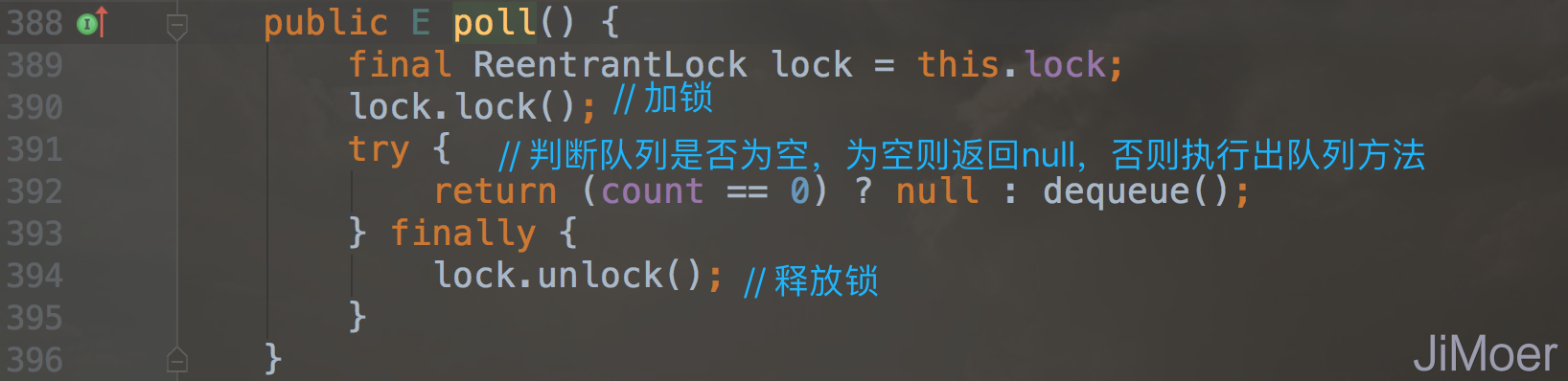
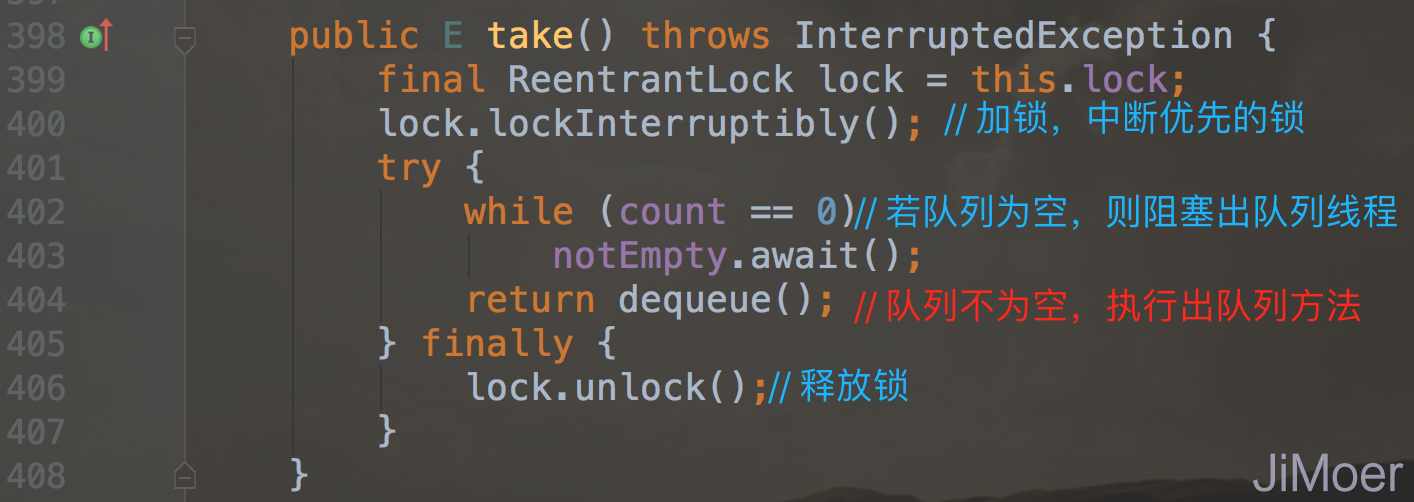
我们通过上面两张源码的截图可以看出来,无论是poll()方法还是take()方法,最终出队列调用的都是dequeue()方法,只不过take()是阻塞的方式出队列,当队列为空时直接将出队列线程阻塞并放到等待队列中。
那么dequeue()是如何出队列的呢?

我们通过源码可知,出队列是根据出队列索引takeIndex来决定该出哪一个元素了,如果当前出队列的元素的索引正好是数组容量的最后一个元素,那么出队列索引takeIndex也要重新从头开始记录了。后面再更新迭代器中的数据,以及唤醒阻塞中的入队线程。
还有两个出队列的方法remove(Object o)和removeAt(final int removeIndex)这两个方法稍微复杂一些,因为首先要定位到要移除的元素的位置,然后再执行出队操作,remove最终执行的出队方法是依赖removeAt(final int removeIndex),而removeAt的出队操作是定位到要移除的元素位置后,将takeIndex位置的元素替换掉要移除的元素,就完成了出队操作 。
LinkedBlockingQueue
构造方法
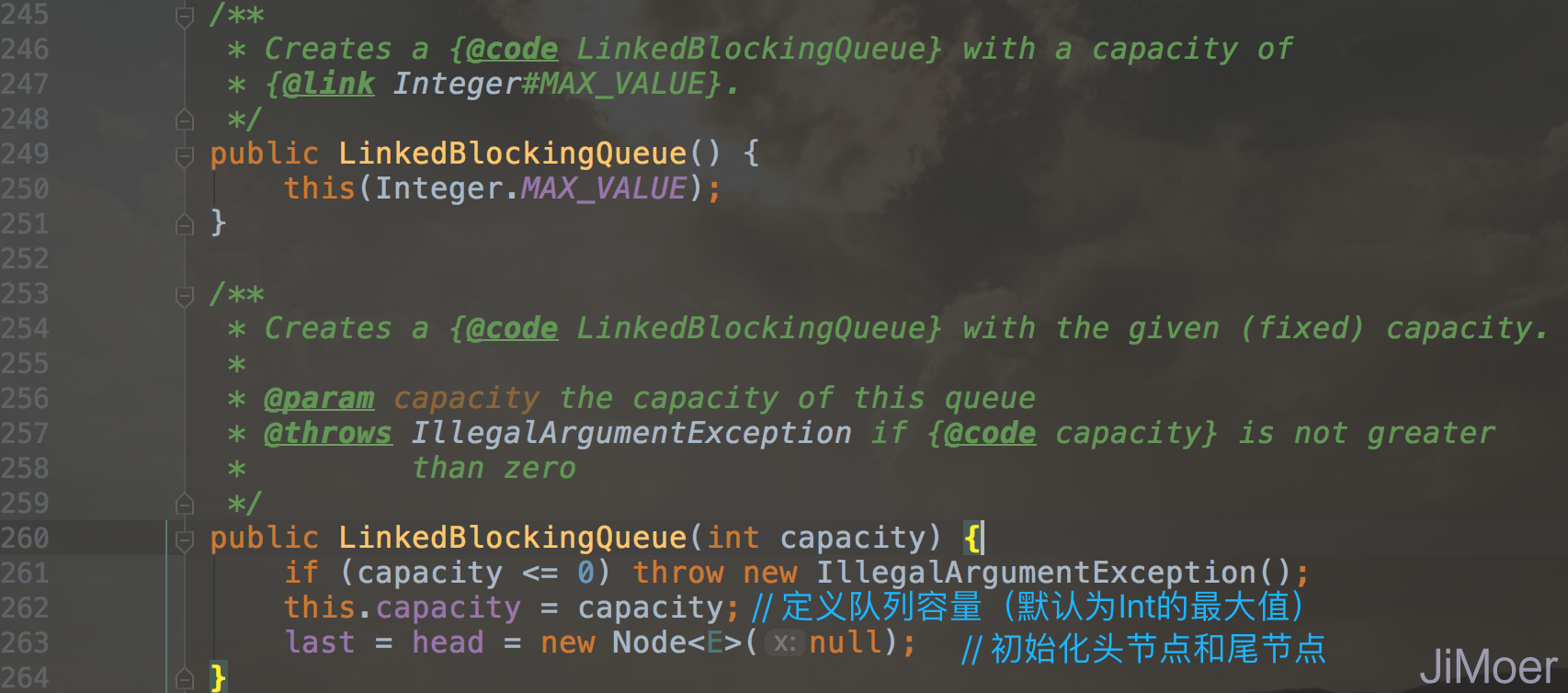
LinkedBlockingQueue的初始化队列的数据信息时是在构造方法中进行的,但是实现阻塞队列需要的核心能力是在JVM为对象分配空间时就初始化好了的。

入队列
从初始化数据的时候可以看到,LinkedBlockingQueue是有两个锁的,入队列有入队列的锁,出队列有出队列的锁,是两个独立的重入锁。这样入队列和出队列相互对立的处理,大大的提高了队列的吞吐量。
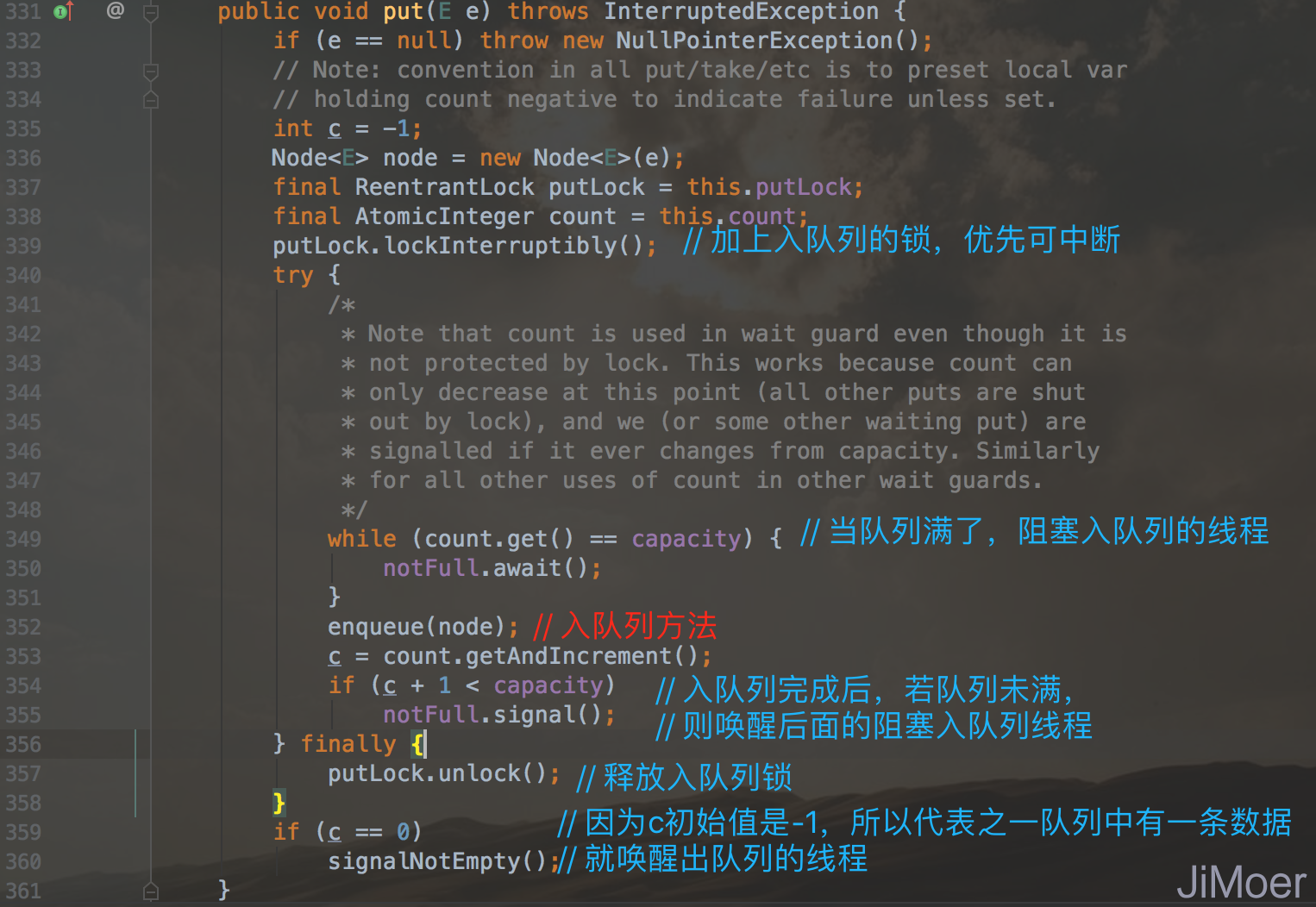
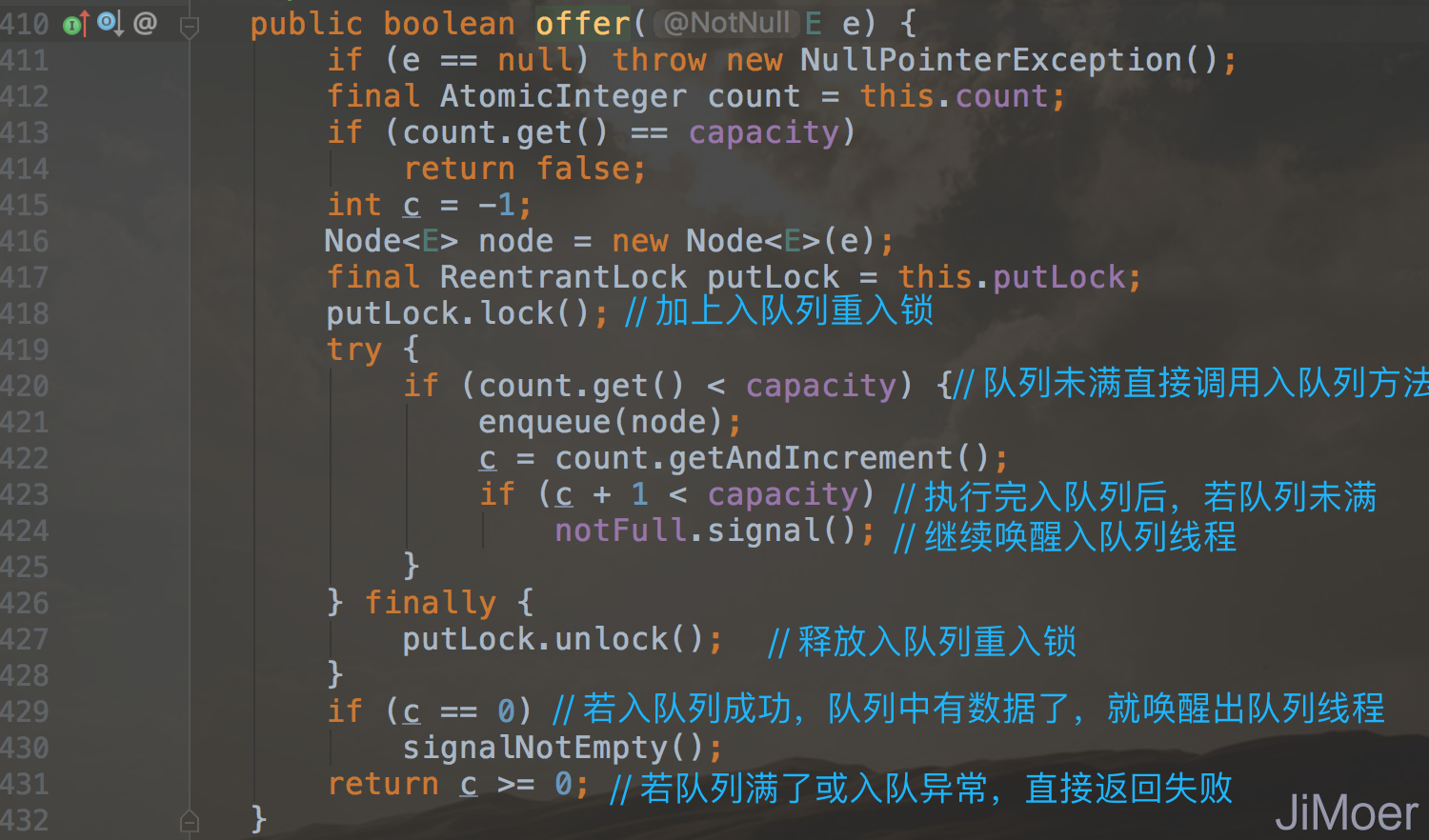
我们看到LinkedBlockingQueue的入队列的两个方法put和offer(其实还有一个add方法,但是具体实现也是调用的offer方法),put方法是阻塞入队,即当队列满了的时候阻塞入队列的线程,而offer则不是阻塞入队,入队列成功即返回true否则返回false。
这两个方法底层调用的都是enqueue()方法,我们看一下这个方法具体是怎么执行的入队列。

enqueue()方法逻辑比较简单,就是将元素添加到链表的尾部。

出队列
LinkedBlockingQueue的出队列方法,是先获取出队列的takeLock,然后再执行出队列方法。
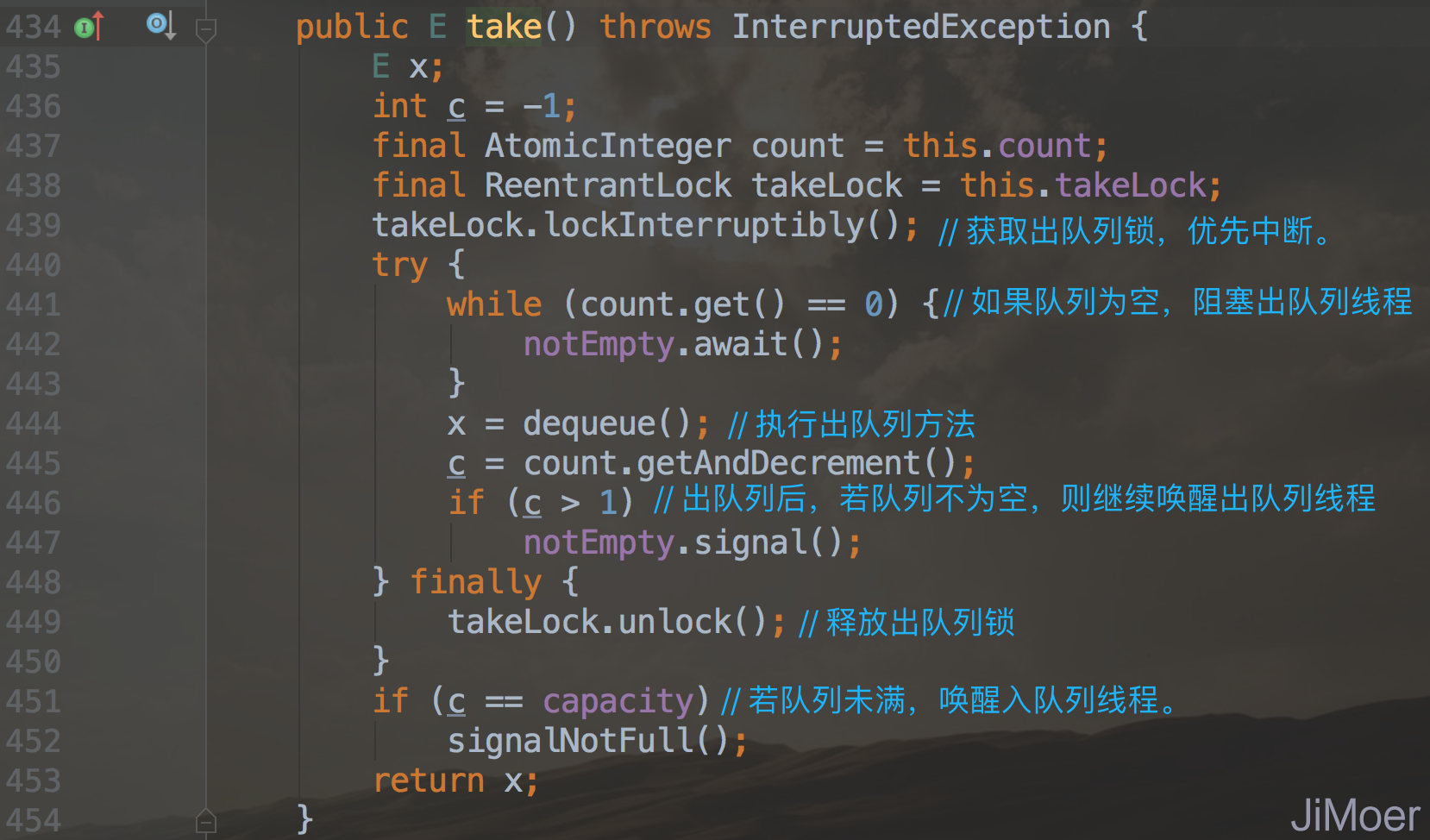

take方法和poll方法前者在队列为空后,会阻塞出队列的线程,后者poll方法则不会在队列为空时阻塞出队列线程,会直接返回null。
无论是take方法还是poll方法都是调用的dequeue()方法执行的出队列,那么看一下dequeue()方法的实现吧。一直忘记说了,我这次贴出来的源码都是JDK1.8版本的。

我们看到dequeue()执行了一个比较绕的逻辑,主要意思是将头节点后的第一个不为null的节点移除队列了,并设置了新的头节点位置。
我们来仔细拆分一下步骤,就好理解了,初始时,头节点的值是null(new Node(null))但是next指向的是队列中的第二个节点。
- 第一步把head节点会把自己的next节点从指向第二节点,改成指向自己,这样,本来head节点的值就是null,然后现在next也是一个空节点了,这样的节点GC的时候就会被优先回收掉了。
- 第二步把原先head节点的下一个节点的值赋值给head,这样原先的第二节点就成为了head节点,然后将新head节点的数据返回。
- 将新head节点的值设置为null,这样就新的节点的也就和原先的head节点的数据形式一样了。
我们可以通过下面图来更清晰的看一下:

我们再来看一下出队列的另一个方法remove。
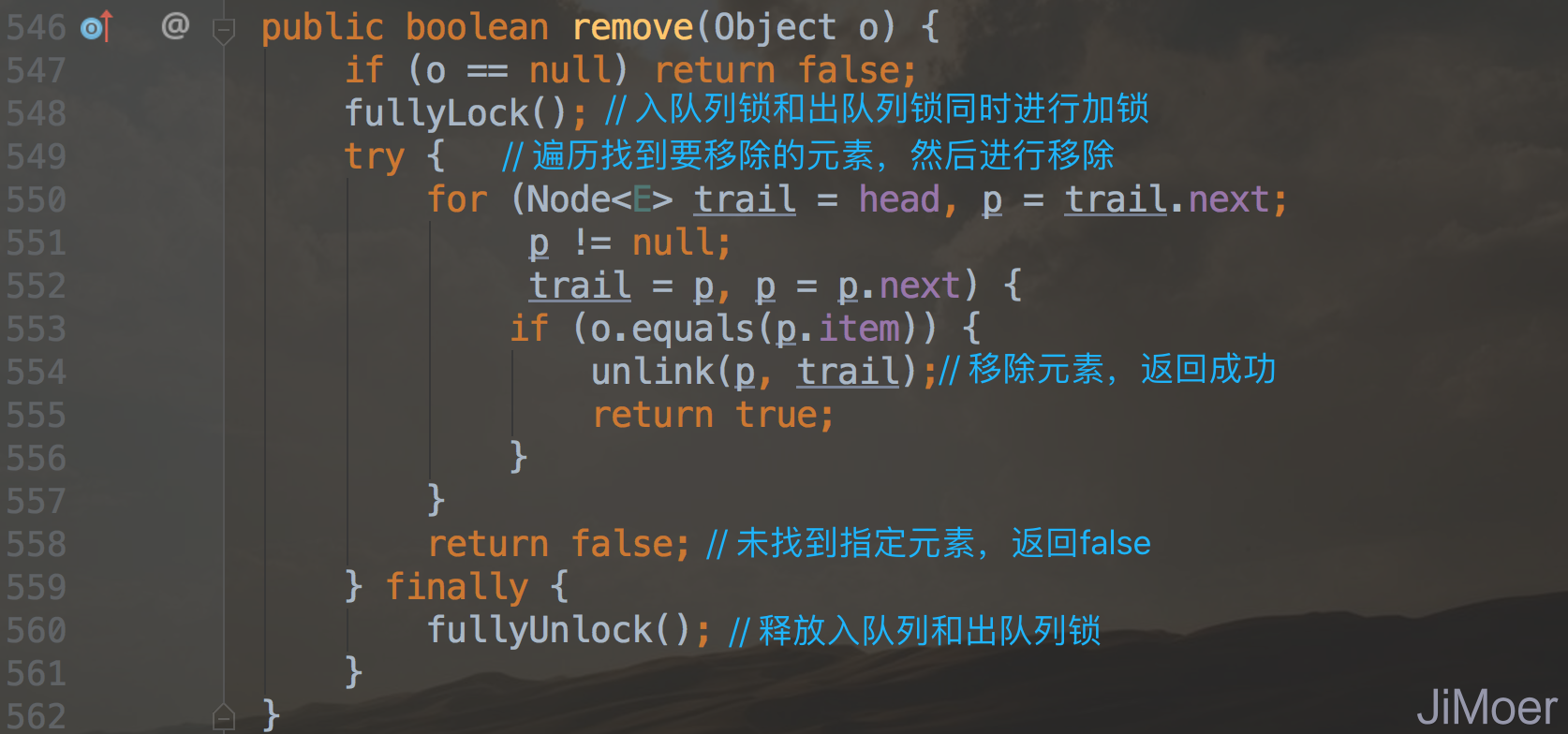
执行remove()方法的时候,要将出队列锁和入队列的锁都加上,这两个操作要等待remove()方法执行完毕后再操作。为了就是保证在remove()方法寻找指定元素时有入队和出队操作导致遍历操作混乱。
我们再来看一下unlink()方法,主要还是将元素从链表中移除,若移除的元素为last元素,做一些处理等。

总结
- 自己实现了阻塞队列,首先要有锁来保证入队列和出队列的线程在队列满和队列为空时阻塞主入队列线程和出队列线程。然后再队列有空间后唤醒入队列线程,在队列有数据时唤醒出队列线程。
ArrayBlockingQueue和LinkedBlockingQueue都是有界的阻塞队列(LinkedBlockingQueue的默认长度为Int的最大值也暂且归为是有界),ArrayBlockingQueue是通过数据来实现阻塞队列的,并且是依赖ReentrantLock和Condition来进行加锁的。LinkedBlockingQueue是通过链表来实现阻塞队列的,也是依赖ReentrantLock和Condition来完成加锁的。ArrayBlockingQueue采用的全局唯一锁,入队列和出队列只能有一个操作同时进行,LinkedBlockingQueue入队列和出队列分别采用对立的重入锁,入队列和出队列可分开执行,所以吞吐量比ArrayBlockingQueue更高。ArrayBlockingQueue采用数组来实现队列,执行过程中并不会释放内存空间,所以需要更多的连续内存;LinkedBlockingQueue虽然不需要大量的联系内存,但是在并发情况下,会创建和置空大量的对象,很依赖GC的处理效率。
