2018/10/29 21:07:38
linux—awk 简介
awk不仅仅是linux系统中的一个命令,而且是一种编程语言。可以用来处理数据和生成报告(excel)处理的数据可以是一个或多个文件,可以是来自标准输入,也可以通过管道获取标准输入。awk可以在命令行上直接编辑命令进行操作,也可以编写成awk程序来进行更为复杂的运用。Awk -F
_—F;是指awk按照什么标准进行文件的切割,切割成一列一列的。
awk有参数-F可以指定awk按照什么符号切割文件内容,将源文件内容切割成一列一列的。
awk [options] ‘pattern {action}’ file
Awk 格式 options参数 pattern模式 {action}动作
一部分模式 一部分动作 {}里的是动作 {}外的是模式
模式是条件 根据条件来筛选数据 先有模式再有动作 模式过滤完后在动作
如果我们不指定-F参数 awk默认按照 空格进行文本的切割{}
中的print代表输出的意思。 print打印
:输出以冒号分割符的第一列
$0;默认输出全部内容(取文件的全部内容)
$NF;默认取每行的最后一列
Awk -F “:” ‘NR>3 && NR<8 {print $0}’yunjisuan.txt
1、根据参数(-F)先切割
2、根据‘单引号的模式进行内容过滤
3、符合模式条件的在进行动作输出



冒号:七行


第6 5 4 3 2 1
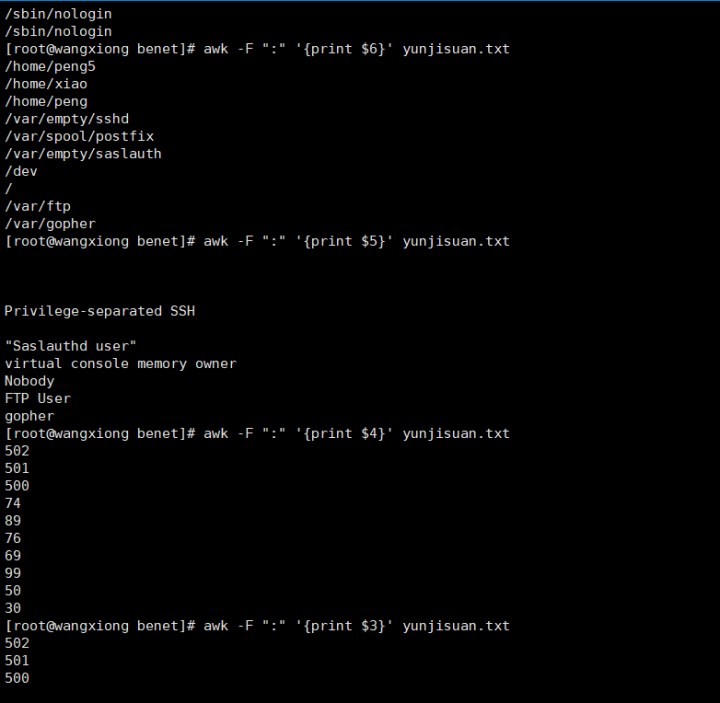

加[]和加号+ 【】+


[:/ ]+

基本模式;
Awk -F “:” ‘NR>=2 && NR<=6 {print NR,$1}’ /etc/passwd
命令说明;
—F 指定分隔符为冒号,相当于以“:”为菜刀,进行字段的切割。 NR>=2 && NR<=6;这部分表示模式,是一个条件,表示取第2行到第六行。 {print NR,$1};这部分表示动作,表示要输出NR行号和$1第一列。

只有模式

命令说明;
-F指定分割符为冒号
NR>=2&&<=6这部分条件,表示取第二行到第6行
但是这里没有动作,这里大家需要了解如果只有条件(模式)没有动作,awk默认整行。
只有动作

多个模式和动作

-F指定分割符号为冒号
这里有多个条件与动作的组合
NR==1表示条件,行号(NR)等于1的条件满足的时候,执行{print NR,$1}动作,输出行号与第一列
NR==2表示条件,行号早(NR)等于2的条件满足的时候,执行{print NR,$NF}动作,输出行号与最后一列($N

awk 执行过程
怎么处理文件

过程演示

命令说明;
条件NR>=2,表示行号大于等于2时候,执行{print $0}显示整行
awk是通过一行一行的处理文件,这条命令中包含模式部分(条件)和动作部分(动作),awk将处理模式(条件)指定的行
awk -F 参数 ‘BEGIN模块{}模式{动作}END模块{}’后面加文件名 也就是AWK有两个模块一个开始一个结尾。

记录和字段,为了方便理解可以把记录就当行即记录==行,字段相当于列,字段==列




awk输出是它以什么符号输出就以什么符号换行。
模式和动作都不输出代表全部默认输出。
以冒号不默认输出而换行


读入换行符
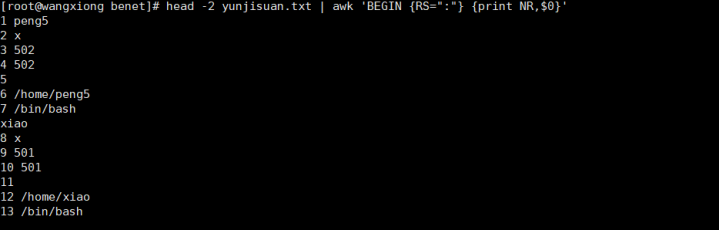
输入换行符修改了输出换行符 分割符号ORS

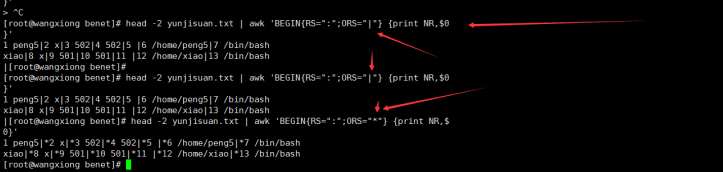

除了字母全部换掉

打开文件
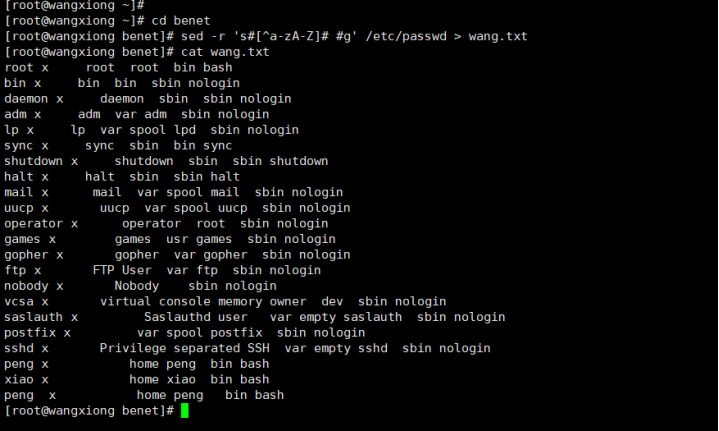
变成一行
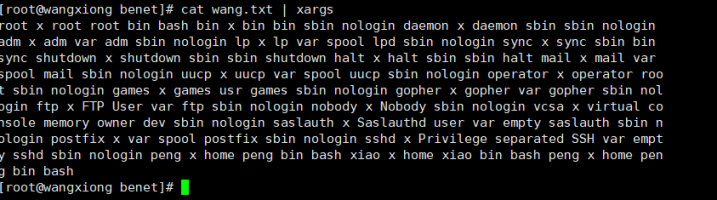
xargs -NL变成竖行

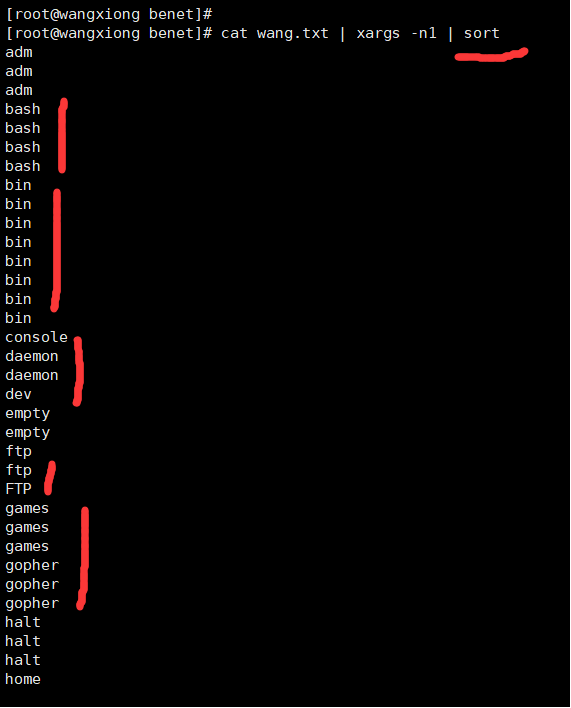
排序sort
uniq所有相同的单词取消定重

Uniq -c 表示去重还显示行数

Sort -n 让它按着数字排列 sort是默认输出26个字母
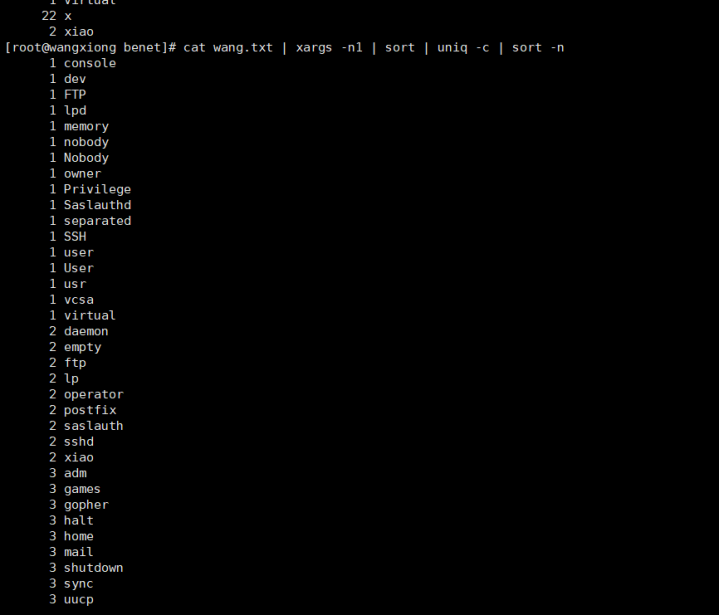
sort -rn 逆转排序

sort -k2 参数 -r -n -k k2 指定列排序




awk 进阶
模式与动作
1、正则表达式作为模式
显示第9行是正则表达式的IP地址
awk '$9~/^200$/' test
awk '$9~/^200$/{print $1}' test
2、比较模式
NR>=3&&<=8
取出文件/etc/services的10-20行
awk 'NR>=10&&NR<=20' /etc/services
awk 'NR>10&&NR<20' /etc/services
# awk -F":" '$5=="root"'
# awk -F":" '$5~/^root$/'
找出工资在(40000,60000)之间的员工名字
# awk -F: ‘$3>=”40000” && $3<=”60000” {print $1}’ test2
范围模式
显示第二行到第五行的行好和整行的内容
# awk 'NR==2,NR==5{print NR,$0}' count.txt
显示以bin开头,到第五行的行号及整行内容
# awk '/^bin/,NR==5{print NR,$0}' awkfile.txt
从第三列以bin开始的行到以lp开头的行并显示其行号和整行内容
awk -F":" '$5~/^bin/,/^lp/{print NR,$0}' awkfile.txt
从第三列以bin开头字符串的行到第三列以lp开头字符串的行
# awk -F: '$5~/^bin/,$5~/^lp/{print NR,$0}' awkfile.txt
(1)定义内置变量(-F本质式修改的FS变量)
# ifconfig eth0|awk -F "(addr:)|( Bcast:)" 'NR==2{print $2}'
相当于# ifconfig eth0 | awk 'BEGIN{FS="(addr:)|( Bcast:)"} NR==2{print $2}'
# ifconfig eth0 | awk -F "[ :]+" 'NR==2{print $4}'
相当于# ifconfig eth0 | awk 'BEGIN{FS="[ :]+"}NR==2{print $4}'
# ifconfig eth0 | awk -F "[^0-9.]+" 'NR==2{print $2}'
相当于# ifconfig eth0 | awk 'BEGIN{FS="[^0-9.]+"}NR==2{print $2}'
(2)在读取文件之前,输出提示性信息(表头)
# awk -F ":" 'BEGIN{print "1111","2222"} {print $1,$3} ' test.txt
# awk -F ":" 'BEGIN{print "1111","2222"} {print $1,$3} END{print "asdf","asdfg"}' test.txt
(3)使用BEGIN 模块的特殊性质,进行一些测试(计算)
计算数值
# awk 'BEGIN{print 10/3}'
赋值变量
# awk 'BEGIN{a=1;b=2;print a,b,a+b}'
awk中字母会被认为是变量,给一个变量赋值字母(字符串),用双引号
# awk 'BEGIN{abcd=123456;a=abcd;print a}'
123456
# awk 'BEGIN{a="abcd";print a}'
abcd
表示a的b次方
# awk ‘BEGIN{a=2;b=3;print a**b}’
查看/etc/services空行个数
方法一:
# grep -c “^$” /etc/services
方法二:
# awk ‘/^$/ {i=i+1} END{print i}’ /etc/services
其中,i=i+1 等同于i++
查看test文件一共有多少行
# awk ‘{i++}END{print i}’ test
求test文件每行的值之和
# awk ‘{i=i+$0}END{print i}’ test
求 test文件每行的值之积(BEGIN初始变量设定位置)
# awk ‘BEGIN{i=1}{i=i*$1}END{print i}’ test
awk数组
用一个变量表示多组数据,通常优先考虑数组,eg:变量名[数字]=不同的值
awk数组结构
arrayname[string]=value
arrayname为数组名
string为元素名
value为值
循环语句
for(变量1 in 变量2) 表示变量1在变量2 中取值,变量1被变量2循环赋值
统计域名访问次数
(1)取出域名
(2)将域名去重
(3)统计次数
方法一:
# awk -F “/+” ‘{print $2}’ wangxiong | sort uniq -c
方法二:
# awk -F "[ /]+" '{h[$2]++}END{for(i in h)print i,h[i]}' wangxiong
统计域名访问次数并累计流量
(1)取出域名
(2)将域名去重
(3)统计流量大小
# awk -F "[ /]+" '{h[$2]=h[$2]+$4}END{for(i in h)print i,h[i]}' wangxiong
第一列字母去重,并求和
# awk ‘{h[$1]+$2}END{for(i in h)print i,h[i]}’ test