论文的三个贡献
(1)提出了two-stream结构的CNN,由空间和时间两个维度的网络组成。
(2)使用多帧的密集光流场作为训练输入,可以提取动作的信息。
(3)利用了多任务训练的方法把两个数据集联合起来。
Two stream结构
视屏可以分成空间与时间两个部分,空间部分指独立帧的表面信息,关于物体、场景等;而时间部分信息指帧间的光流,携带着帧之间的运动信息。相应的,所提出的网络结构由两个深度网络组成,分别处理时间与空间的维度。

可以看到,每个深度网络都会输出一个softmax层,最后会通过一种方法把两个softmax层的输出融合:一种是平均层,一种是训练一个以这些softmax输出作为特征的SVM。
空间卷积网络
网络的输入是单帧,这样的分类网络其实有很多,例如AlexNext,GoogLeNet等,可以现在imageNet上预训练,再进行参数迁移。
光流场卷积网络(时间维度网络)
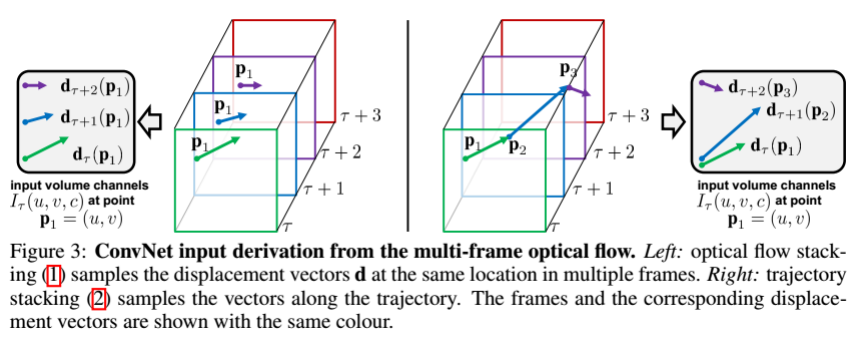
光流场卷积网络的输入是 stacking optical flow displacement fields between several consecutive frames(不会翻译……),就是多层两帧间的光流场,可以从上图看出。因为光流场可以描述物体的运动信息。
简单光流场叠加
方法是计算每两帧间的光流,简单地叠加在一起。假设需要追踪L+1帧(会产生L帧的光流),那么会把光流分解成X,Y两个方向的光流,这时会有2L个通道。
轨迹追踪光流叠加
假设一帧的像素点,可以通过光流来追踪它在视频中的轨迹点,从而计算它在每一帧的相应位置的光流向量。同样的会把光流分解成X,Y两个方向的光流,这时会有2L个通道。
对于这种方法,我想到DT的论文中谈到的一个问题就是:像素点的“漂移”,这很可能会出现在追踪多帧之后。猜想的是,这个L帧应该不是指训练视频的所有帧,这种方法可以很好地区分出前景和背景。
减去平均光流
这主要是为了消去摄像头运动引起的相对运动。
多任务训练
对于空间卷积网络,因为它输入的只是图像,而且只是一个分类网络,它有大量的数据集可供预训练,这是为了应对过拟合的问题。
但是对于时间卷积网络,可供训练的视频集很少。作者使用多任务训练的方法,提供两个softmax输出层,但网络只有一个。论文的依据是,提供两个softmax输出层相当于正则化的过程。这样融合两个数据集对网络进行训练时,其中一个softmax层对其中一个数据集的视频进行分类,另一个softmax层对另一个数据集进行分类,在最后BP算法时,把两个softmax层的输出加和,作为总的误差执行BP算法更新网络的权值。
一些细节问题
1、计算光流是预处理后保存的,因为这会影响网络的速度。
2、测试时,对于一个输入视频,随机抽样固定数的帧,它们的时间维度间隔是一样的。对于每帧,又计算它的光流场叠加。而每一帧又会在不同的位置采样,对于一个视频的误差,就是总的误差的平均。