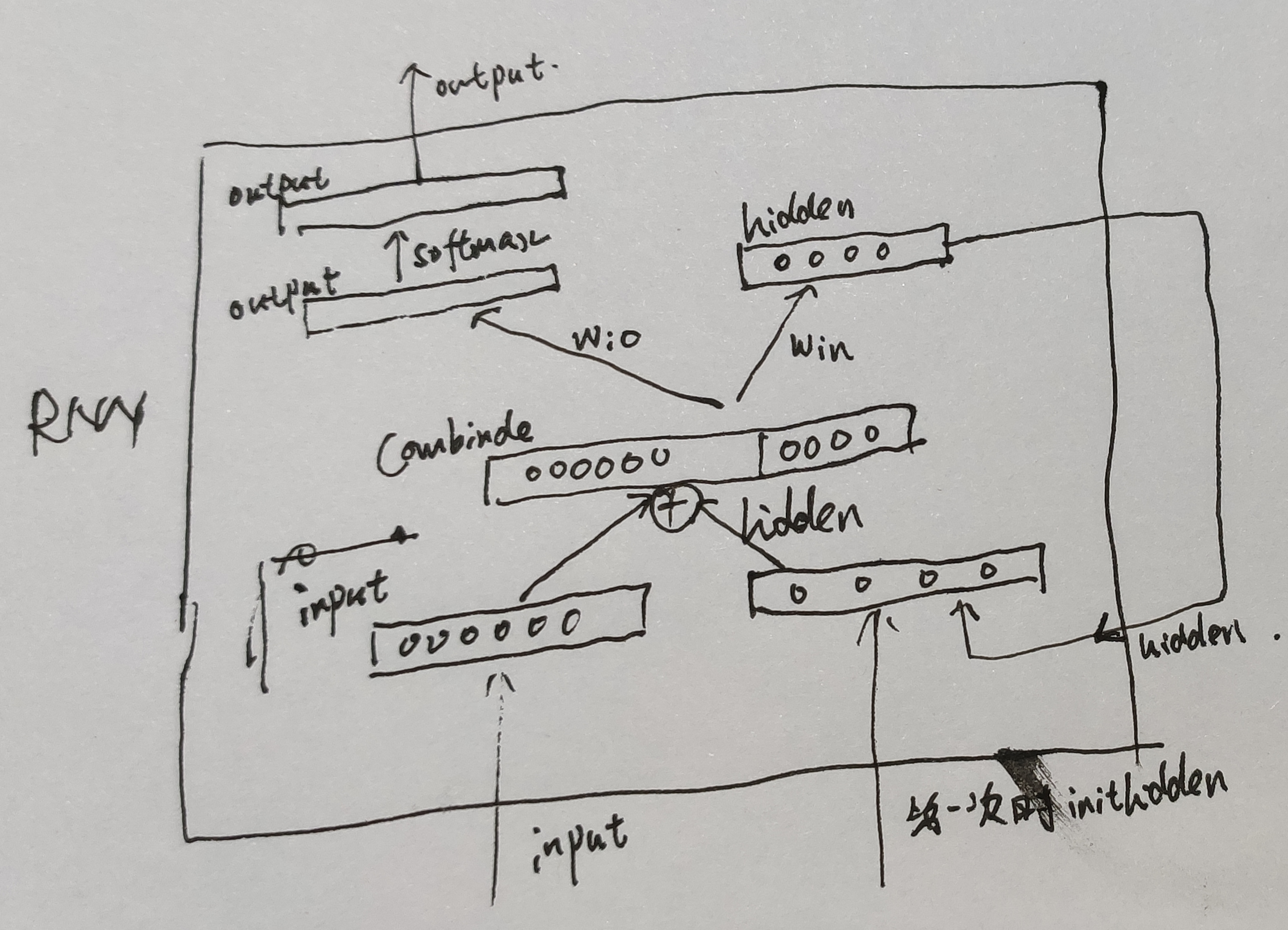
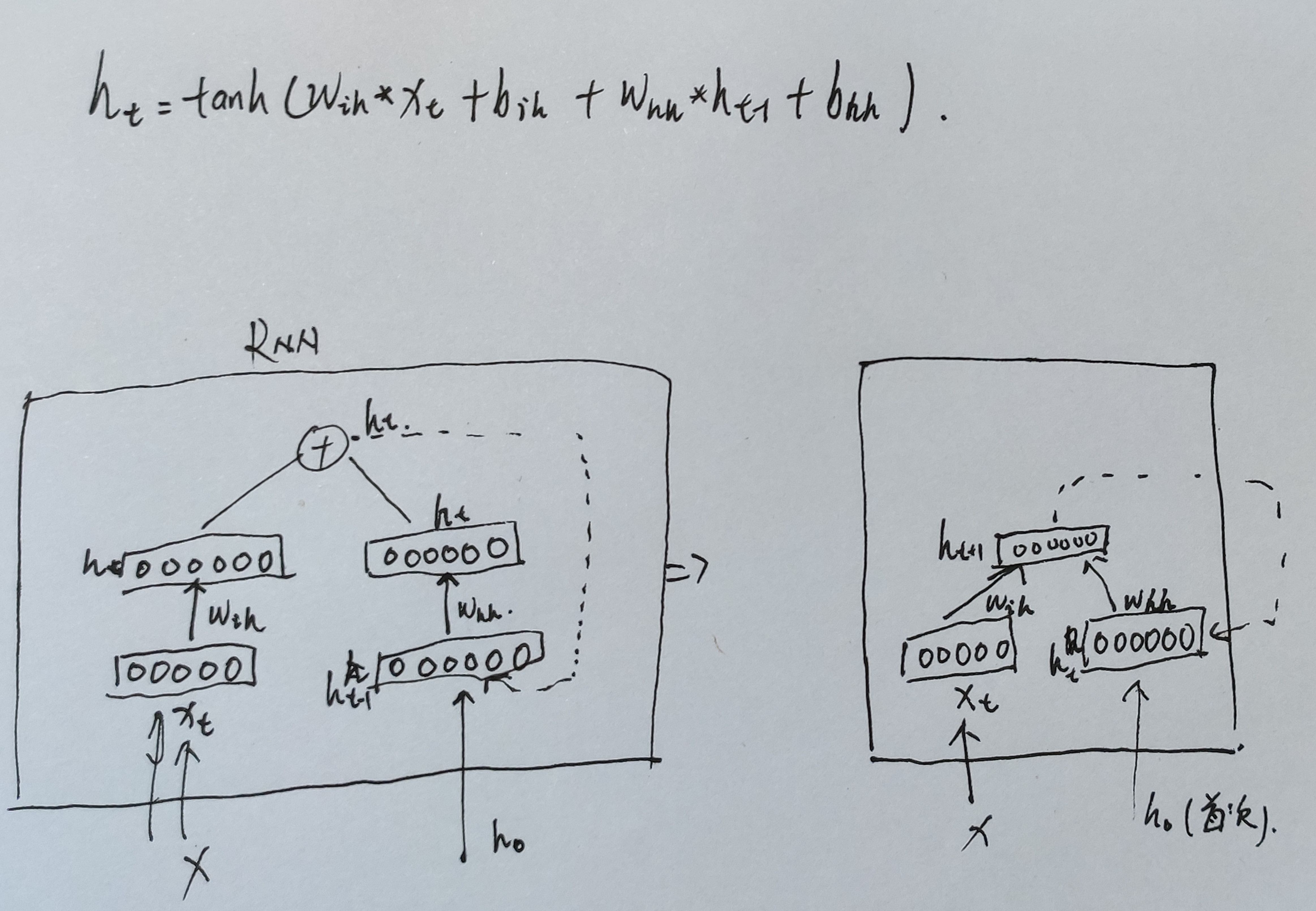
而RNN本质上就是linear layers。
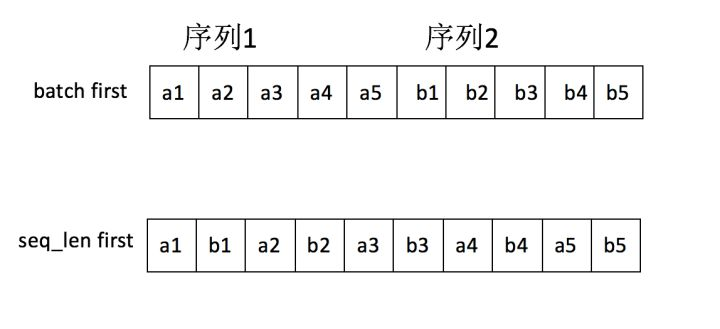
即使RNN的输入数据是batch first,内部也会转为seq_len first。
def forward(self, input, hx=None):
batch_sizes = None # is not packed, batch_sizes = None
max_batch_size = input.size(0) if self.batch_first else input.size(1) # batch_size
if hx is None: # 使用者可以不传输hidden, 自动创建全0的hidden
num_directions = 2 if self.bidirectional else 1
hx = torch.autograd.Variable(input.data.new(self.num_layers *
num_directions,
max_batch_size,
self.hidden_size).zero_())
if self.mode == 'LSTM': # h_0, c_0
hx = (hx, hx)
flat_weight = None # if cpu
func = self._backend.RNN( # self._backend = thnn_backend # backend = THNNFunctionBackend(), FunctionBackend
self.mode,
self.input_size,
self.hidden_size,
num_layers=self.num_layers,
batch_first=self.batch_first,
dropout=self.dropout,
train=self.training,
bidirectional=self.bidirectional,
batch_sizes=batch_sizes,
dropout_state=self.dropout_state,
flat_weight=flat_weight
)
output, hidden = func(input, self.all_weights, hx)
return output, hidden
可以看到,在训练RNN时,可以不传入 ,此时PyTorch会自动创建全0的
。
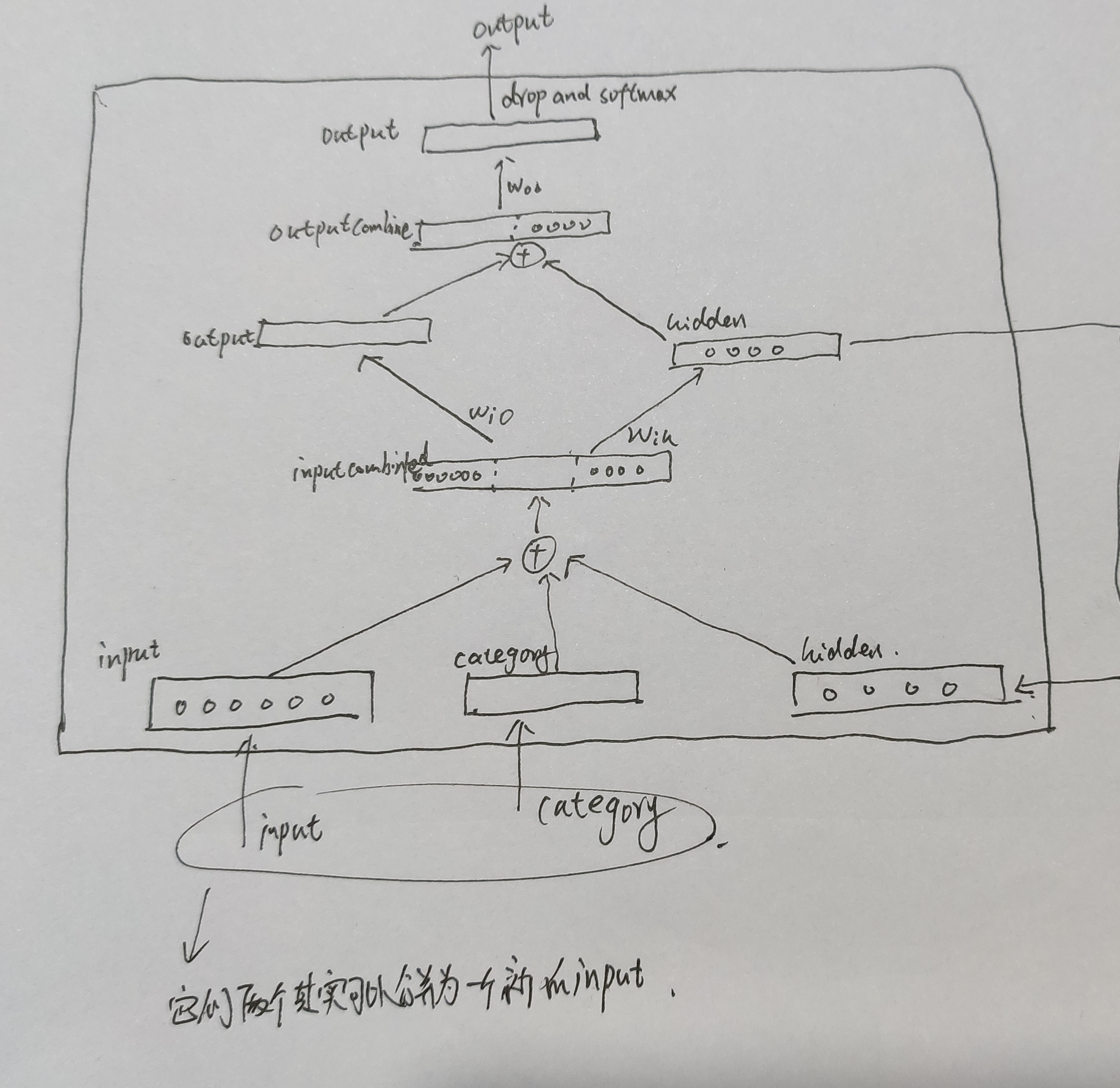
也可以对RNN的output添加一层全连接层实现与hidden的不同