1 简介
MHA(Master High Availability)目前在MySQL高可用方面是一个相对成熟的解决方案,它由日本DeNA公司youshimaton(现就职于Facebook公司)开发,是一套优秀的作为MySQL高可用性环境下故障切换和主从提升的高可用软件。在MySQL故障切换过程中,MHA能做到在0~30秒之内自动完成数据库的故障切换操作,并且在进行故障切换的过程中,MHA能在最大程度上保证数据的一致性,以达到真正意义上的高可用。
2 环境
|
172.17.0.6 |
node1 |
master |
|
172.17.0.7 |
node2 |
slave1 |
|
172.17.0.8 |
node3 |
slave2 |
|
172.17.0.9 |
manager |
mha-manager |
3 测试目标
本次测试基于mha+主从复制,进行容灾演练,主要包括模拟故障、主从切换、恢复节点测试。
本文档主要记录三种测试的操作。
4 容灾演练
4.1 检查节点状态
masterha_check_repl --conf=/etc/mhamanger/app.conf
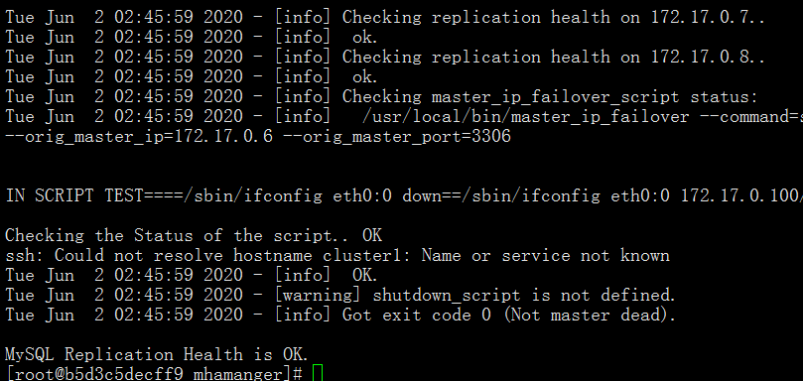
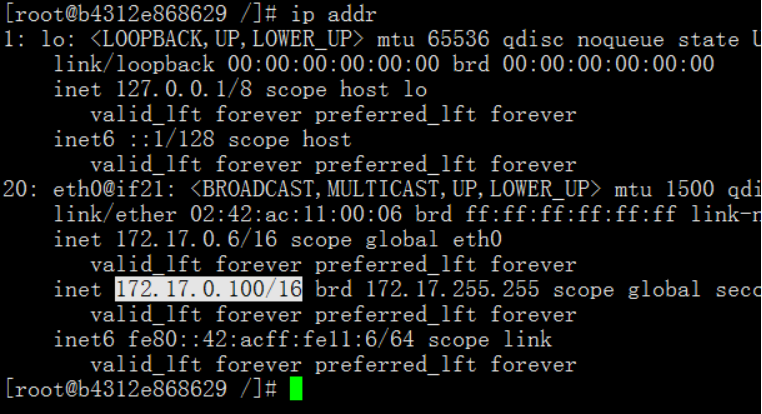
4.2 检查主节点node1的VIP
ip addr
4.3 node1节点宕机
停掉mysql服务后,查看进程

4.4 node2变为主节点
查看mha日志会发现,主节点从172.17.0.6转移到172.17.0.7,即node2变为主节点。

4.5 vip漂移
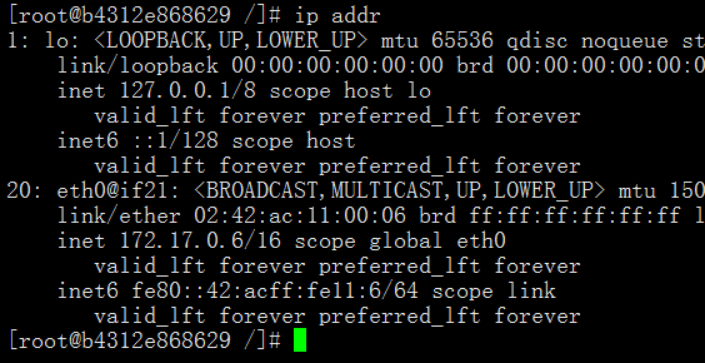
4.5.1 检查node1的ip
查看ip会发现vip没有了
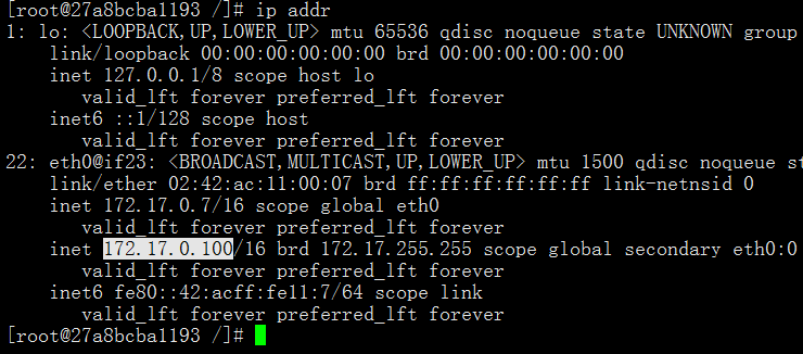
4.5.2 检查node2的ip
在172.17.0.7机器上查看ip,发现原来主节点的vip已经漂移到新主节点。
4.6 查看mha状态
故障转移完成后, manager将会自动停止,因为配置中含有故障节点,是无法启动的,需要修复好故障节点,或者将故障节点从配置文件删除,服务才可以启动。此时使用 masterha_check_status 命令检测将会遇到错误提示, 如下所示

4.7 恢复宕机节点
原有 master 节点故障后,需要重新准备好一个新的 MySQL 节点。基于来自于master 节点的备份恢复数据后,将其配置为新的 master 的从节点即可。注意,新加入的节点如果为新增节点,其 IP 地址要配置为原来 master 节点的 IP,否则,还需要修改 mha.cnf 中相应的 ip 地址。随后再次启动 manager ,并再次检测其状态。
本次测试,以刚才关闭的那台主机为新的机器,来进行恢复。
4.7.1 启动node1节点
启动mysql进程

4.7.2 配置主从
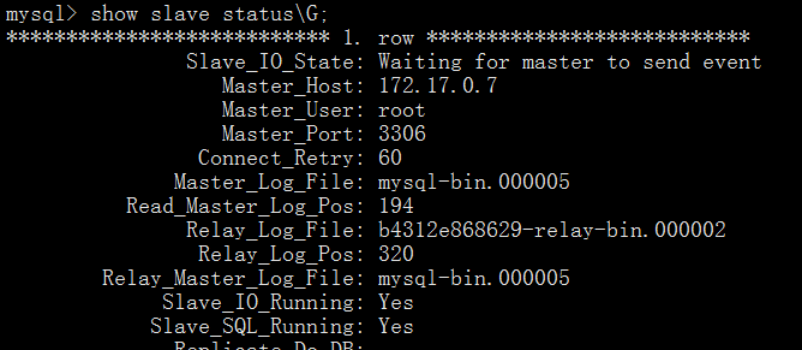
1)从节点配置
mysql> change master to master_host='172.17.0.7', master_user='root', master_password='Aa!123456',master_auto_position=1;
mysql> start slave;
mysql> show slave statusG;
4.8 检查节点状态
masterha_check_repl -conf=/etc/mhamanger/app.conf

4.9 启动mha服务
nohup masterha_manager --conf=/etc/mhamanger/app.conf >/etc/mhamanger/mha.log 2>&1 &
masterha_check_status --conf=/etc/mhamanger/app.conf ##查看状态

至此,node2节点为主节点,node1节点恢复变为从节点。
5 总结
本次测试,模拟主节点宕机后,mha自动将某一个从节点提升为主节点,并且原来的主节点的vip也漂移到新主节点上。再将宕机的节点恢复为从节点,数据无丢失。
6问题
6.1 故障转移
6.1.1 问题背景
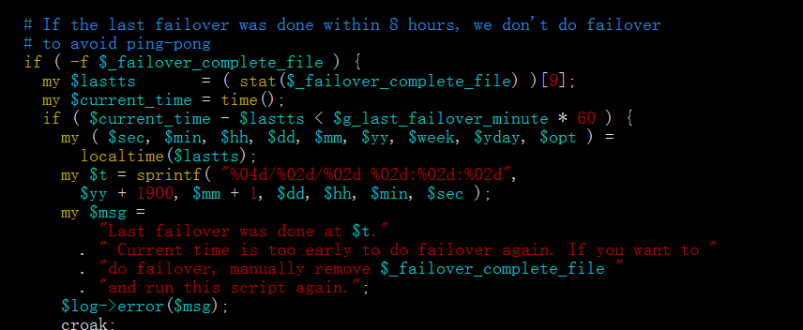
第二次模拟主节点宕机后,查看mha日志,提示并未自动进行故障转移

6.1.2 原因
mha自动故障转移脚本默认设置---如果上次故障转移是在8小时内完成的,则不执行故障转移

6.1.3 解决办法
需要删除报错文件app.failover.complete后,手动切换
masterha_master_switch --master_state=dead --conf=/etc/mhamanger/app.conf --dead_master_host=172.17.0.6 --dead_master_port=3306 --intervactive=1 --new_master_host=172.17.0.7
