java内存模型与线程
进程是程序的一个动态执行过程,是指一个内存中正在运行的应用程序,每个进程都有自己独立的一块内存空间,一个进程中可以启动多个线程,进程本身不执行任何东西,它只是线程的容器。比如在Windows系统中,一个运行的exe就是一个进程。线程是指进程中的一个执行流程,一个进程中可以运行多个线程。比如java.exe进程中可以运行很多线程。线程总是属于某个进程,进程中的多个线程共享进程的内存。“同时”执行是人的感觉,在线程之间实际上轮换执行。
并发处理是人类压榨计算机能力的最有力武器。物理机对并发的处理方案对虚拟机的实现有很大参考意义。
由于计算机存储设备存取数据的速度与计算机处理器的运算速度有几个数量级的差距。计算机系统不得不加入一层高速缓存作为内存与处理器之间的缓冲:将运算需要的数据从内存复制到缓存中,让处理器与缓存进行数据交互以便让运算快速进行,运算结束后将缓存中的数据同步回内存中。
但在多处理器系统中同时暴露了一个新问题:每个处理器都有自己的高速缓存,而他们又共享同一主内存,怎么保持缓存的一致性?为了解决此问题,各个处理器访问缓存时需要遵循一些协议来保证缓存的一致性。
主流程序语言(C/C++)直接使用物理硬件和操作系统的内存模型,因此不同平台上内存模型的差异可能导致程序的并发访问出错(并发指多线程,并行指多操作系统)。java虚拟机规范定义了一种java内存模型来屏蔽各种硬件和操作系统的内存访问差异,以实现让java程序在各种平台都能达到一致的内存访问效果。java内存模型的规则是定义程序中各个变量(方法区的类变量和堆区的实例变量)的访问规则(此处的变量不包括局部变量和方法参数,线程私有的变量不会被共享,自然没有竞争问题。)
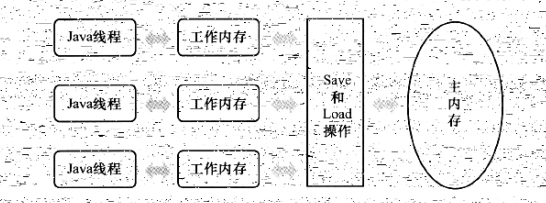
工作内存和主内存间的交互协议体现为对变量的8种操作:
lock(锁定):将主内存中一个变量标识为一条线程独占的状态。
unlock(解锁):将主内存中一个处于锁定状态的变量释放出来,变量释放后才可以被其他线程锁定。
read(读取):将一个变量的值从主内存传输到线程的工作内存。
load(载入):将工作内存中read读取到的变量放入工作内存中的变量副本中。
use(使用):把工作内存中一个变量的值传递给执行引擎,每当虚拟机遇到一个需要使用到变量的值的字节码指令时将会执行这个操作。
assign(赋值):把一个从执行引擎接受到的值赋给工作内存中的一个变量,每当虚拟机遇到一个给变量赋值的字节码指令时执行这个操作。
store(存储):把工作内存的变量传到主内存。
write(写入):它把store操作从工作内存中得到的变量存到主内存中。
虚拟机不允许read——load和store——write出现单独的操作。
虚拟机允许将64位的long和double型变量分为两次32位的操作来进行。只有四种操作:read,load,store,write。
关键字volatile是虚拟机提供的最轻量级的同步机制。但volatile只能保证从主内存加载到操作数栈顶的变量的值是正确的(volatile修饰的变量具有可见性体现在值被改变后可以立即同步回主内存以便被其他未加载此变量的线程正确加载,但不能保证加载到操作数栈后的变量不被其它线程改变。)volatile的另一个作用是禁止指令重排序优化。
除了volatile具备可见性,final和synchronized关键字修饰的变量也具备可见性。final变量一旦完成初始化,其他线程则可看见其值,synchronized的可见性则体现在对一个变量执行unlock前必须保证该变量同步回主内存。
教材上说大致认为基本类型数据的访问是线程安全的,其实不严谨,因为对一个数据的读或写都不是由一个原子性操作完成的,读由load和read完成,写有store和write来完成。但对基本数据类型的常量的读写可以认为是线程安全的。
方法中的对象?????????????????????????????????
线程的5种状态:创建(新建后尚未启动)
就绪(执行了start()启动方法的线程即为就绪状态)
运行(启动后正在运行的状态)
阻塞状态(同步阻塞:同步阻塞状态的线程在等待一个排他锁,或者说线程在等待进入同步区域的时候,线程将进入这种状态。)
无限期等待阻塞(等待其他线程显示唤醒),例如没有设置timeout参数的Object.wait()方法,没有设置timeout参数的Thread.join()方法,LockSupport.park()方法。
限期等待阻塞(一定时间后由系统自动唤醒,同上面是一种状态)Thread.sleep()方法,设置了timeout的Object.wait()方法,设置了timeout的Thread.join()方法,LockSupport.parkUntil()方法。
死亡:线程执行结束。
线程安全与锁(各种锁)优化
线程安全按照"安全程度"可分为:不可变,绝对线程安全,相对线程安全,线程兼容和线程对立。
不可变:不可变的对象一定是线程安全的,无论是对象的方法实现还是方法的调用者,都不需要采取任何的线程安全保障措施。如果共享数据是一个基本类型,在定义时使用final修饰就可以保证它是不可变的。如果共享数据是一个对象,那就需要保证对象的行为不会对对象的状态产生任何影响。例如String类型的对象,我们调用它的任何方法都不会影响它原来的值,只会返回一个新构造的字符串对象。
final型变量和String对象由于不可变,不用考虑线程安全问题。枚举类型也如此。
绝对线程安全:Vector是一个线程安全的容器,因为它的add(),get(),和size()这类方法都是被synchronized修饰的,但即使它所有的方法被修饰成同步,也不意味着调用它的时候不再需要同步手段。
Thread.sleep(time):此方法作用是停止当前执行的线程一段时间,以便让CPU调用其他可执行的线程。时间到后该线程参与CPU资源竞争,但不一定能竞争到CPU立即执行。跟对象锁没有关系,谈不上释放不释放。
Object.wait():让当前拥有自己对象锁的线程释放掉自己的对象锁,并让该线程等待自己的对象锁,以便其他线程可以访问自己的对象锁。
Object.notify():通知等待自己对象锁的线程来准备占有自己的对象锁,当同步块执行完才是真正释放锁。
线程安全的实现方法:???????????????????????????
互斥同步:
非阻塞同步:
类锁????????????????????????????????????、
由上述同步静态方法引申出一个概念,那就是类锁。其实系统中并不存在什么类锁。当一个同步静态方法被调用时,系统获取的其实就是代表该类的类对象的对象锁
在程序中获取类锁
可以尝试用以下方式获取类锁
synchronized (xxx.class) {...}
synchronized (Class.forName("xxx")) {...}
同时获取2类锁
同时获取类锁和对象锁是允许的,并不会产生任何问题,但使用类锁时一定要注意,一旦产生类锁的嵌套获取的话,就会产生死锁,因为每个class在内存中都只能生成一个Class实例对象。
多线程设计
一个项目中有很多对象,只要保证入口的方法是线程安全的即可。
线程池
高并发
多线程能解决程序同时操作jvm内存的问题,这样在数据库中也不会有同步问题,但高并发的情况下依靠多线程必然大大降低系统性能,因为每次访问都需要对应一个线程。
构建高性能web站点
第一章:
1.1等待的真相:当用户在浏览器输入请求的地址后,等待浏览器将一副完整的画面呈现出来,这一段时间到底发生了什么?其实这段时间并不简单,它包括:
1.数据在网络上传输的时间
2.服务器处理请求并生成回应数据的时间
3.浏览器本地计算和渲染的时间
数据在网络上传输的时间包括两部分:浏览器端主机发出请求后数据经过网络到达服务器的时间,服务器端主机的回应数据经过网络到达浏览器端主机的时间。这两段时间其实都可以看做某个值大小的数据经过某一主机通过网络到达另一主机所消耗的时间,我们称作响应时间。响应时间的决定因素主要包括数据量和网络带宽。数据量容易计算,带宽稍后介绍。
服务器处理请求数据并准备返回生成数据的时间当然消耗在服务器端,我们用一个叫“吞吐率”的指标来衡量这段时间,吞吐率不是指单位时间内处理的数据量,而是每秒处理的请求数。影响服务器吞吐率的因素有很多,比如服务器的并发策略,I/O模型,I/O性能,CPU核数,当然也包括应用程序的逻辑复杂度,后续介绍。
浏览器消耗时间暂不说。
1.2瓶颈在哪里?系统性能的瓶颈会随着系统的不断运行发生变化或迁移。
1.5加快服务器脚本计算速度
大多数涉及性能问题的站点都会使用各种各样的服务器端脚本语言。
第二章:数据的网络传输
第三章:服务器并发处理能力
web服务器的并发处理能力也称吞吐率,单位是reqs/s。常见的web服务器软件会提供当前服务器运行状态和当前吞吐率的查看方法。
吞吐率描述了服务器在实际运行期间的单位时间处理额请求数,然而我们更关心的是服务器并发处理能力的上限,即最大吞吐率。现在普遍使用“压力测试”方法模拟足够多的并发用户数,分别持续发送一定的http请求,并统计测试持续的总时间,计算出这种压力下的平均值即为最大吞吐率。
100个用户同时向服务器连续请求十次和一个用户连续向服务器请求1000次在微观看来效果是不一样的,对于后者,任何时刻网卡接收缓冲区中只有来自该用户的一个请求,对于前者,服务器网卡接收缓冲区最多有100个请求,很显然前者的情况下服务器压力更大。
最大并发用户数指服务器和用户达到最大利益时的并发用户数。
web服务器一般会限制同时服务的最多用户数,比如apache的MaxClients,当实际并发用户数大于此数值,多出的用户请求则在服务器内核的数据接收缓冲区中等待处理,这些请求在用户看来处于阻塞状态。服务器会维护一个文件描述符来代表当前某个用户的连接。文件描述符总数也叫并发连接数,简单来讲一个连接就是一个会话。所以并发连接数小于等于实际并发用户数,小于还是等于取决于各个服务器的MaxClients。
web服务器的本质工作就是:争取以最快的速度将内核缓冲区的用户请求数据一个不剩拿回来,并将响应数据放入内核维护的另一块用于发送数据的缓冲区,接下来尽快处理下一波请求,并尽量让用户请求在内核缓冲区中不要等太久。
apache的mod_status可以了解到此刻处理的请求数,即此刻的实际并发用户数。
压力测试的重要指标:用户平均请求等待时间,服务器平均处理请求时间。
apache附带的ab非常容易使用,ab进行一切测试的基础是http。查看ab版本:进入apache下bin目录在地址栏输cd进入命令台窗口,输入ab -v则可查看版本号。
ab压力测试:
在bin目录下进入命令台窗口后输入ab -n -c url即可,例:
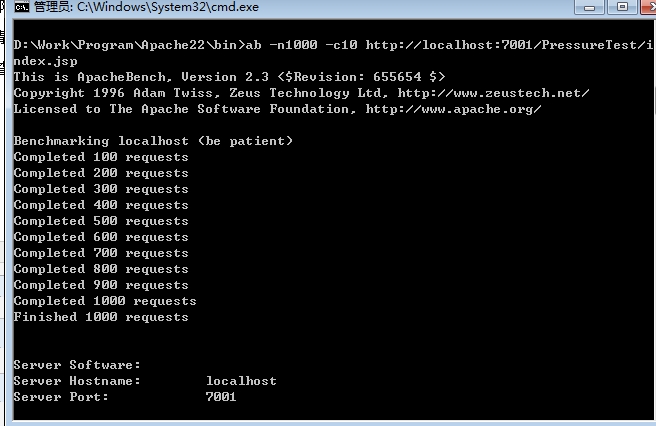
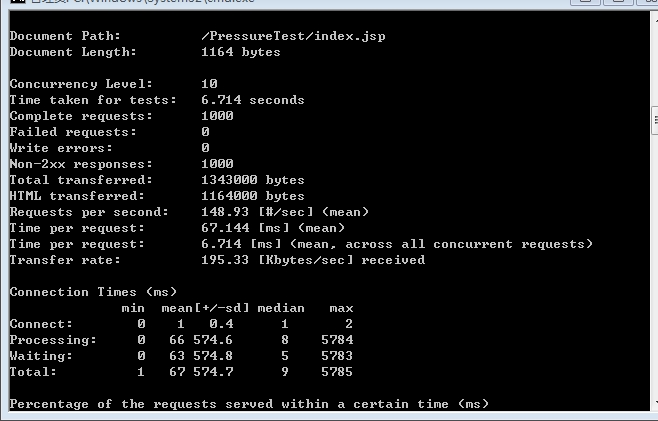

这里可以看到测试的吞吐率为148.93,有些资料上总请求数为1000,并发用户数为10的情况下吞吐率可达5960.15。
ab -t参数可以设置测试时超时的时间为多少。
Total transferred:响应数据的总长度(头信息和正文的总和)
HTML transferred:响应数据中正文的长度(Total transferred去除掉正文后的长度)
Time per request:用户平均请求等待时间 ——总测试时间/(完成的总请求数/并发级别)
Time per request:服务器平均请求处理时间(across all concurrent requests)——总测试时间/完成的总请求数
最后一部分内容表示请求时间的分布(毫秒为单位):50%的请求不超过9毫秒,98%的请求不超过21毫秒,1%请求用时最长不超过5785毫秒。