随着bert在NLP各种任务上取得骄人的战绩,预训练模型在这不到一年的时间内得到了很大的发展,本系列的文章主要是简单回顾下在bert之后有哪些比较有名的预训练模型,这一期先介绍几个国内开源的预训练模型。
一,ERNIE(清华大学&华为诺亚)
论文:ERNIE: Enhanced Language Representation with Informative Entities
GitHub:https://github.com/thunlp/ERNIE
清华大学和华为诺亚方舟实验室联合提出的引入知识图谱来增强预训练模型的语义表达能力,其实预训练时就是在原来bert的基础上增加了一个实体对齐的任务。我们来看看这个新的任务是怎么做的,首先来看看整个预训练模型的架构
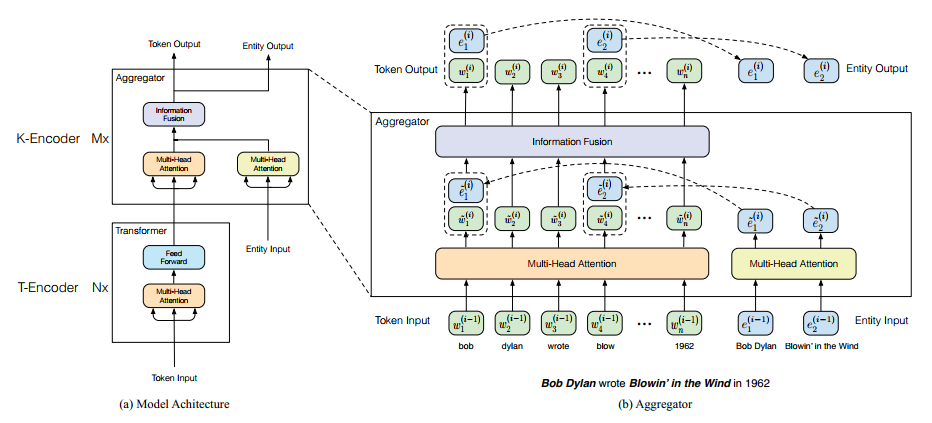
这里有两个encoder,T-encoder和K-encoder,其实这里的K-encoder只有在预训练的时候有作用,在之后的fine-tuning阶段只要使用T-encoder就可以了,所以这里的重要就是引入了实体对齐这个任务而已。
如上图中右边所示,给定一条序列由$w_1, w_2, ...w_n$组成,与及这条序列对齐的实体$e_1, e_2, ...e_m$,这些实体来自于知识图谱。因为一个实体会涉及到多个词,以上面图中为例$e_1 = Bob Dylan$,而在序列中与之对应的实体由两个token组成,即$w_1=bob, w_2=dylan$。因此对齐时我们将知识图谱中的实体和序列中实体的首个词对应,即在位置上将$e_1$对应到$w_1$上。
T-encoder的作用是对序列进行编码,结构和bert-base类似,但是层数是6层。K-encoder是对知识图谱实体和序列做聚合,知识图谱中的实体通过TransE做嵌入,具体表达式如下:
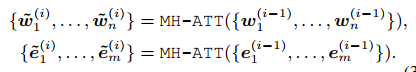
先对序列和实体编码,然后做聚合,聚合完之后更新$w$ 和$e$的状态
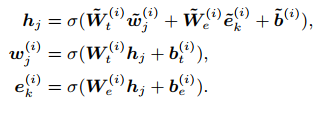
对于非实体的token的处理,直接对序列中的token更新即可:
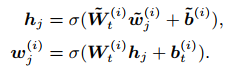
了解了怎么将知识图谱中的实体引入到任务中,再来看看具体的任务是怎么构建的,本文提出了随机mask tokens-entity中的entity,然后去预测该位置对应的entity,本质上和MLM(mask language model)任务一致,都属于去噪自编码。具体mask的细节:
1)5%的tokens-entity对采用随机用其他的entity来替换,这主要是引入噪声,因为在实际的任务中也存在这种情况。
2)15%的tokens-entity对采用随机maskentity,然后来预测这个entity。
3)80%保持正常。
这篇论文主要的工作就是增加了这个任务,另外也提出了在实体类型和关系抽取两个任务上新的预训练方式,具体如下图:
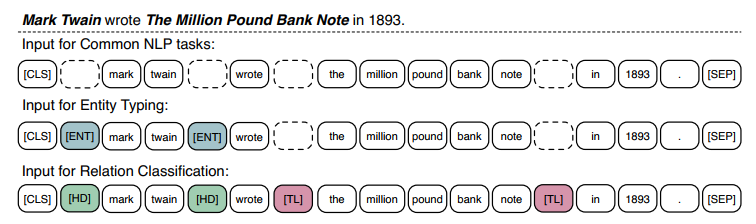
就是引入了一些特殊的token来表明另外一些特殊token的身份。因为引入了实体对齐任务,因此该模型在一些和知识图谱相关的下游任务上要优于bert。
二,ERNIE(百度)
论文:ERNIE: Enhanced Representation through Knowledge Integration
GitHub:https://github.com/PaddlePaddle/ERNIE
百度提出的这个模型名称和上面一致,而且也号称引入了知识信息,但是做法完全不一样,这里主要的改变是针对bert中的MLM任务做了一些改进。具体的如下图所示
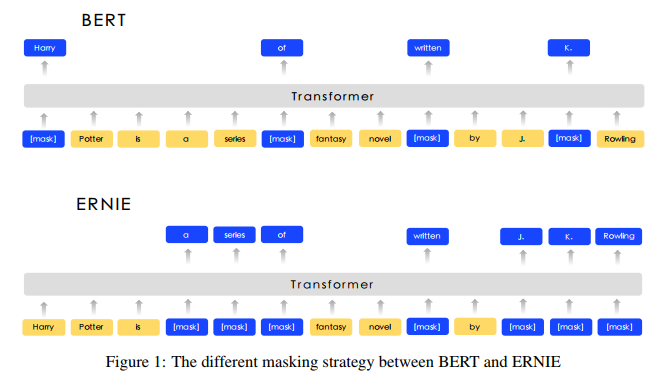

在bert中只是mask了单个token,但是在语言中,很多时候都是以短语或者实体存在的,如果不考虑短语或者实体中词之间的相关性,而将所有的词独立开来,不能很好的表达句法,语义等信息,因此本文引入了三种mask的方式,分别对token,entity,phrase进行mask。除此之外,本论文中还引入了对话语料,丰富语料的来源,并针对对话语料,给出了一个和NSP相似的任务。具体如下图:
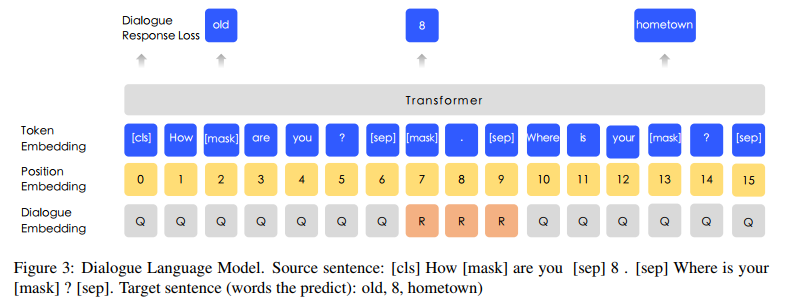
这里构建了一个DLM的任务,其实做法和NSP类似,随机生成一些假的多轮QR对,然后让模型去预测当前的多轮对话是真实的还是假的。
作者测试了在很多任务上较bert都有1-2%的提升,并且作者做了实验表明DLM任务在NLI任务上有提升。
三,ERNIE 2.0(百度)
论文:ERNIE 2.0: A CONTINUAL PRE-TRAINING FRAMEWORK FORLANGUAGE UNDERSTANDING
GitHub:https://github.com/PaddlePaddle/ERNIE
这是百度在之前的模型上做了新的改进,这篇论文主要是走多任务的思想,引入了多大7个任务来预训练模型,并且采用的是逐次增加任务的方式来预训练,具体的任务如下面图中所示:
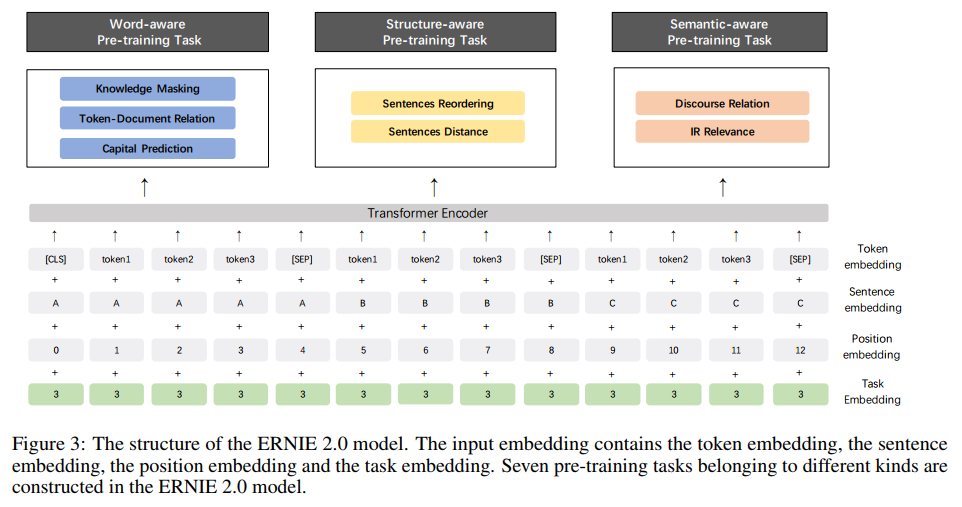
因为在这里不同的任务输入不同,因此作者引入了Task Embedding,来区别不同的任务,训练的方法是先训练任务1,保存模型,然后加载刚保存的模型,再同时训练任务1和任务2,依次类推,到最后同时训练7个任务。个人猜测这样的做法可能是因为直接同时训练7个模型的效果并不好,但现在这种训练方式,一开始在任务1上已经预训练过,相当于已经有了一个很好的初始化参数,然后再去训练任务1和任务2能保证模型更好的收敛。
在效果上较ERNIE1.0版本基本上全面提升,并且在阅读理解的任务上有很大的提升。
四,BERT-wwm
论文:Pre-Training with Whole Word Maskingfor Chinese BERT
GitHub:https://github.com/ymcui/Chinese-BERT-wwm
BERT-wwm是哈工大开源出来的,在原始bert-base的基础上引入whole word mask,其实就是分词后的词进行mask,如下图所示:

因为是在bert-base的基础上训练的,因此无缝对接现在的bert的使用方法,直接替换预训练模型即可,都不需要更改任何文件。而且在很多中文任务上较bert都有一些提升,因此推荐使用。