Hibernate框架
配置
配置文件:
1 <?xml version="1.0" encoding="UTF-8"?> 2 <!DOCTYPE hibernate-configuration PUBLIC 3 "-//Hibernate/Hibernate Configuration DTD 3.0//EN" 4 "http://www.hibernate.org/dtd/hibernate-configuration-3.0.dtd"> 5 <hibernate-configuration> 6 <session-factory> 7 <property name="hibernate.connection.driver_class">oracle.jdbc.OracleDriver</property> 8 <property name="hibernate.connection.password">test</property> 9 <property name="hibernate.connection.url">jdbc:oracle:thin:@localhost:1521:xe</property> 10 <property name="hibernate.connection.username">test</property> 11 <property name="hibernate.default_schema">TEST</property> 12 <property name="hibernate.dialect">org.hibernate.dialect.Oracle10gDialect</property> 13 14 <property name="hibernate.show_sql">true</property> 15 <property name="hibernate.format_sql">true</property> 16 <!-- 自动建表策略 --> 17 <property name="hibernate.hbm2ddl.auto">update</property> 18 19 <mapping resource="com/hanqi/model/News.hbm.xml"/> 20 </session-factory> 21 </hibernate-configuration>
配置文件详解:
#数据库使用的驱动类 hibernate.connection.driver_class=com.mysql.jdbc.Driver #数据库连接串 hibernate.connection.url=jdbc:mysql://localhost:3306/db #数据库连接的用户名 hibernate.connection.username=user #数据库连接的密码 hibernate.connection.password=password #数据库使用的方言 hibernate.dialect=net.sf.hibernate.dialect.MySQLDialect #是否打印SQL语句 hibernate.show_sql=true javax.persistence.validation.mode=none
Hibernate JDBC 属性
|
属性名 |
用途 |
|
hibernate.connection.driver_class |
JDBC driver class |
|
hibernate.connection.url |
JDBC URL |
|
hibernate.connection.username |
database user |
|
hibernate.connection.password |
数据库用户密码 |
|
hibernate.connection.pool_size |
maximum number of pooled connections |
Hibernate 数据源属性
|
属性名 |
用途 |
|
hibernate.connection.datasource |
数据源 JNDI 名字 |
|
hibernate.jndi.url JNDI |
提供者的 URL(可选) |
|
hibernate.jndi.class JNDI |
InitialContextFactory 类(可选) |
|
hibernate.connection.username |
数据库用户(可选) |
|
hibernate.connection.password |
数据库密码(可选) |
可选的配置属性
有大量属性能用来控制 Hibernate 在运行期的行为。它们都是可选的,并拥有适当的默认值。
|
属性名 |
用途 |
可选值 ()内为默认 |
|
hibernate.dialect |
允许 Hibernate 针对特定的关系数据库生成优化的 SQL 的org.hibernate.dialect.Dialect 的类名。 例如:org.hibernate.dialect.MySQLDialect |
|
|
hibernate.show_sql |
输出所有 SQL 语句到控制台。 |
true|false (false) |
|
hibernate.format_sql |
在 log 和 console 中打印出更漂亮的 SQL。 |
true|false (false) |
|
hibernate.default_catalog |
在生成的 SQL 中,将给定的 catalog 附加于非全限定名的表名上 |
|
|
hibernate.session_factory_name |
org.hibernate.SessionFactory 创建后,将自动使用这个名字绑定到 JNDI 中。 |
|
|
hibernate.max_fetch_depth |
为单向关联(一对一,多对一)的外连接抓取(outer join fetch)树设置最大深度。 |
0到3 |
|
hibernate.default_batch_fetch_size |
为 Hibernate 关联的批量抓取设置默认数量。 |
4、8、16 |
|
hibernate.default_entity_mode |
为由这个 SessionFactory 打开的所有 Session指定默认的实体表现模式。 |
dynamic-map,dom4j,pojo |
|
hibernate.order_updates |
强制 Hibernate 按照被更新数据的主键,为SQL 更新排序。这么做将减少在高并发系统中事务的死锁。 |
true|false
|
|
hibernate.generate_statistics |
如果开启,Hibernate 将收集有助于性能调节的统计数据。 |
true|false
|
|
hibernate.use_identifier_rollback |
如果开启,在对象被删除时生成的标识属性将被重设为默认值。 |
true|false
|
|
hibernate.use_sql_comments |
如果开启,Hibernate 将在 SQL 中生成有助于调试的注释信息,默认值为 false。 |
true|false (false) |
Hibernate JDBC 和连接(connection)属性、Hibernate 缓存属性、Hibernate 事务属性等主要用于提升性能,并且Hibernate有适当的默认值。入门者可以忽略这些设置,等学到一定阶段,你可以参考官方文档进行适当配置。
注意:
hibernate.hbm2ddl.auto
1.设置为update 只是更新数据不会更改表结构,因此如果你的表结构发生了变化,删除对应的表,或者
删除数据库,从新启动tomcat,重新生成表。
2.设置为validate:加载hibernate时,验证创建数据库表结构,这样 spring在加载之初,如果model层和
数据库表结构不同,就会报错,这样有助于技术运维预先发现问题。
例如:ProductInfoEntity这个实体有property1这个属性,而对应的数据库表product没有property1这个
字段,就会在tomcat启动的时候报错:错误可能如下:Missing column: property1 in wjs.product
3.设置为create:每次加载hibernate,如果数据库中存在表,将所有表删除,然后重新生成表
4.设置为create-drop:加载hibernate时创建,退出时删除表结构 理解:如果一开始数据库没有表,启动
tomcat的时候会生成表,当把tomcat关闭之后生成的表又会消除。即:一开始数据库中有几个表,整个
流程执行结束之后,还是几个表。
Hibernate反向工程
根据表建立实体类:
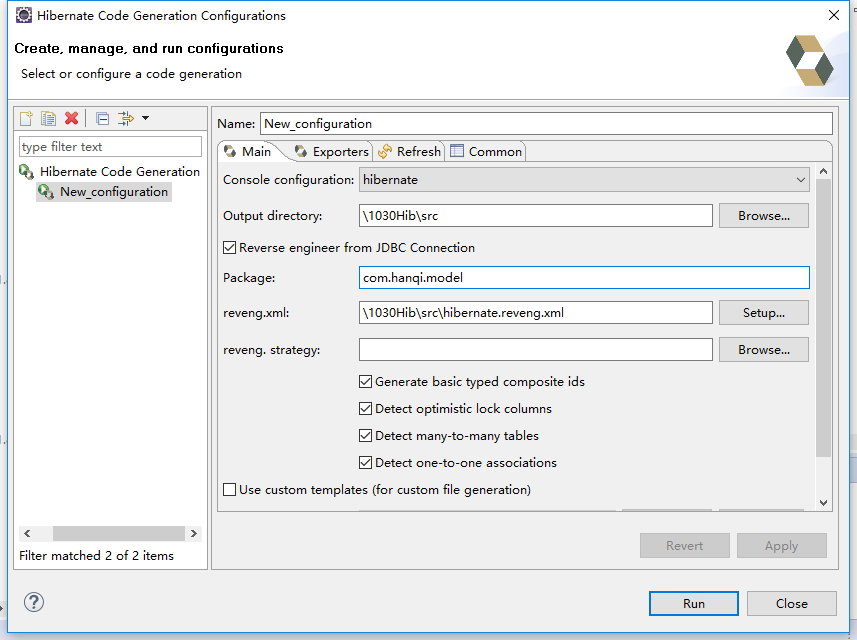
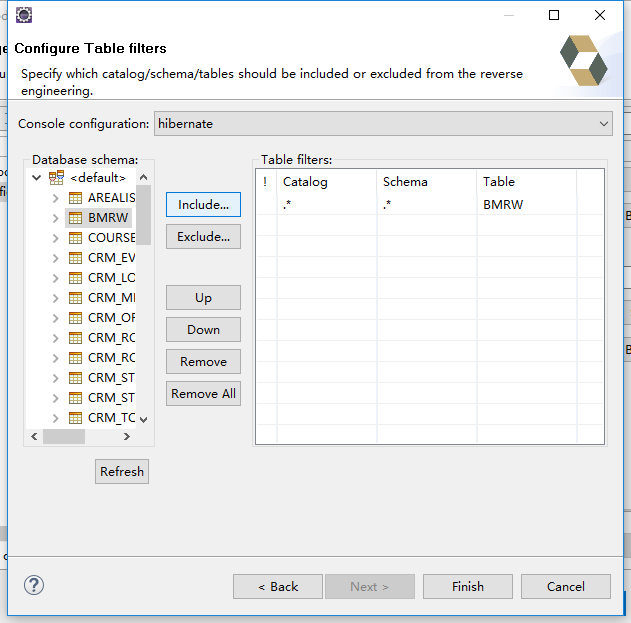
需要注意如果选择的表没有主键,将会多生成一个作为主键的类。
生成的配置文件:
1 <?xml version="1.0"?> 2 <!DOCTYPE hibernate-mapping PUBLIC "-//Hibernate/Hibernate Mapping DTD 3.0//EN" 3 "http://www.hibernate.org/dtd/hibernate-mapping-3.0.dtd"> 4 <!-- Generated 2017-10-30 11:58:41 by Hibernate Tools 4.3.1 --> 5 <hibernate-mapping> 6 <class name="com.hanqi.model.CrmUsers" table="CRM_USERS" optimistic-lock="version"> 7 <id name="id" type="big_decimal"> 8 <column name="ID" precision="22" scale="0" /> 9 <generator class="assigned" /> 10 </id> 11 <property name="username" type="string"> 12 <column name="USERNAME" length="50" /> 13 </property> 14 <property name="password" type="string"> 15 <column name="PASSWORD" length="50" /> 16 </property> 17 <property name="realname" type="string"> 18 <column name="REALNAME" length="50" /> 19 </property> 20 <property name="tel" type="string"> 21 <column name="TEL" length="20" /> 22 </property> 23 <property name="email" type="string"> 24 <column name="EMAIL" length="50" /> 25 </property> 26 <property name="cultural" type="string"> 27 <column name="CULTURAL" length="50" /> 28 </property> 29 <property name="grade" type="string"> 30 <column name="GRADE" length="20" /> 31 </property> 32 <property name="scode" type="big_decimal"> 33 <column name="SCODE" precision="22" scale="0" /> 34 </property> 35 <property name="birthdate" type="string"> 36 <column name="BIRTHDATE" length="20" /> 37 </property> 38 <property name="address" type="string"> 39 <column name="ADDRESS" length="100" /> 40 </property> 41 <property name="job" type="string"> 42 <column name="JOB" length="50" /> 43 </property> 44 <property name="createtime" type="date"> 45 <column name="CREATETIME" length="7" /> 46 </property> 47 </class> 48 </hibernate-mapping>
可以在 mapping 中设置包名:
1 <hibernate-mapping package="">
这样可以省略下面 calss标签中的name属性,会自动寻找。
id标签,主键。
hibernate会根据表中字段的类型自动匹配 model 类中成员变量的类型。
如果:
表中使用了number类型而没有定义长度的话,生成实体类的时候对应的类型会是BigDecimal
表中 number 类型长度与实体类类型对应:
number(1) boolean Boolean
number(2) 2至4之间 byte Byte
number(8) 4至8之间 integer Integer
numbernumber(10)8以上 long Long
1 <generator class="assigned" />
1、assigned
主键由外部程序负责生成,在 save() 之前必须指定一个。Hibernate不负责维护主键生成。与Hibernate和底层数据库都无关,可以跨数据库。在存储对象前,必须要使用主键的setter方法给主键赋值,至于这个值怎么生成,完全由自己决定,这种方法应该尽量避免。
<id name="id" column="id">
<generator class="assigned" />
</id>
“ud”是自定义的策略名,人为起的名字,后面均用“ud”表示。
特点:可以跨数据库,人为控制主键生成,应尽量避免。
2、increment
由Hibernate从数据库中取出主键的最大值(每个session只取1次),以该值为基础,每次增量为1,在内存中生成主键,不依赖于底层的数据库,因此可以跨数据库。
<id name="id" column="id">
<generator class="increment" />
</id>
Hibernate调用org.hibernate.id.IncrementGenerator类里面的generate()方法,使用select max(idColumnName) from tableName语句获取主键最大值。该方法被声明成了synchronized,所以在一个独立的Java虚拟机内部是没有问题的,然而,在多个JVM同时并发访问数据库select max时就可能取出相同的值,再insert就会发生Dumplicate entry的错误。所以只能有一个Hibernate应用进程访问数据库,否则就可能产生主键冲突,所以不适合多进程并发更新数据库,适合单一进程访问数据库,不能用于群集环境。
官方文档:只有在没有其他进程往同一张表中插入数据时才能使用,在集群下不要使用。
特点:跨数据库,不适合多进程并发更新数据库,适合单一进程访问数据库,不能用于群集环境。
3、hilo
hilo(高低位方式high low)是hibernate中最常用的一种生成方式,需要一张额外的表保存hi的值。保存hi值的表至少有一条记录(只与第一条记录有关),否则会出现错误。可以跨数据库。
<id name="id" column="id">
<generator class="hilo">
<param name="table">hibernate_hilo</param>
<param name="column">next_hi</param>
<param name="max_lo">100</param>
</generator>
</id>
<param name="table">hibernate_hilo</param> 指定保存hi值的表名
<param name="column">next_hi</param> 指定保存hi值的列名
<param name="max_lo">100</param> 指定低位的最大值
也可以省略table和column配置,其默认的表为hibernate_unique_key,列为next_hi
<id name="id" column="id">
<generator class="hilo">
<param name="max_lo">100</param>
</generator>
</id>
hilo生成器生成主键的过程(以hibernate_unique_key表,next_hi列为例):
1. 获得hi值:读取并记录数据库的hibernate_unique_key表中next_hi字段的值,数据库中此字段值加1保存。
2. 获得lo值:从0到max_lo循环取值,差值为1,当值为max_lo值时,重新获取hi值,然后lo值继续从0到max_lo循环。
3. 根据公式 hi * (max_lo + 1) + lo计算生成主键值。
注意:当hi值是0的时候,那么第一个值不是0*(max_lo+1)+0=0,而是lo跳过0从1开始,直接是1、2、3……
那max_lo配置多大合适呢?
这要根据具体情况而定,如果系统一般不重启,而且需要用此表建立大量的主键,可以吧max_lo配置大一点,这样可以减少读取数据表的次数,提高效率;反之,如果服务器经常重启,可以吧max_lo配置小一点,可以避免每次重启主键之间的间隔太大,造成主键值主键不连贯。
特点:跨数据库,hilo算法生成的标志只能在一个数据库中保证唯一。
4、seqhilo
与hilo类似,通过hi/lo算法实现的主键生成机制,只是将hilo中的数据表换成了序列sequence,需要数据库中先创建sequence,适用于支持sequence的数据库,如Oracle。
<id name="id" column="id">
<generator class="seqhilo">
<param name="sequence">hibernate_seq</param>
<param name="max_lo">100</param>
</generator>
</id>
特点:与hilo类似,只能在支持序列的数据库中使用。
5、sequence
采用数据库提供的sequence机制生成主键,需要数据库支持sequence。如oralce、DB、SAP DB、PostgerSQL、McKoi中的sequence。MySQL这种不支持sequence的数据库则不行(可以使用identity)。
<generator class="sequence">
<param name="sequence">hibernate_id</param>
</generator>
<param name="sequence">hibernate_id</param> 指定sequence的名称
Hibernate生成主键时,查找sequence并赋给主键值,主键值由数据库生成,Hibernate不负责维护,使用时必须先创建一个sequence,如果不指定sequence名称,则使用Hibernate默认的sequence,名称为hibernate_sequence,前提要在数据库中创建该sequence。
特点:只能在支持序列的数据库中使用,如Oracle。
6、identity
identity由底层数据库生成标识符。identity是由数据库自己生成的,但这个主键必须设置为自增长,使用identity的前提条件是底层数据库支持自动增长字段类型,如DB2、SQL Server、MySQL、Sybase和HypersonicSQL等,Oracle这类没有自增字段的则不支持。
<id name="id" column="id">
<generator class="identity" />
</id>
例:如果使用MySQL数据库,则主键字段必须设置成auto_increment。
id int(11) primary key auto_increment
特点:只能用在支持自动增长的字段数据库中使用,如MySQL。
7、native
native由hibernate根据使用的数据库自行判断采用identity、hilo、sequence其中一种作为主键生成方式,灵活性很强。如果能支持identity则使用identity,如果支持sequence则使用sequence。
<id name="id" column="id">
<generator class="native" />
</id>
例如MySQL使用identity,Oracle使用sequence
注意:如果Hibernate自动选择sequence或者hilo,则所有的表的主键都会从Hibernate默认的sequence或hilo表中取。并且,有的数据库对于默认情况主键生成测试的支持,效率并不是很高。
使用sequence或hilo时,可以加入参数,指定sequence名称或hi值表名称等,如
<param name="sequence">hibernate_id</param>
特点:根据数据库自动选择,项目中如果用到多个数据库时,可以使用这种方式,使用时需要设置表的自增字段或建立序列,建立表等。
8、uuid
UUID:Universally Unique Identifier,是指在一台机器上生成的数字,它保证对在同一时空中的所有机器都是唯一的。按照开放软件基金会(OSF)制定的标准计算,用到了以太网卡地址、纳秒级时间、芯片ID码和许多可能的数字,标准的UUID格式为:
xxxxxxxx-xxxx-xxxx-xxxxxx-xxxxxxxxxx (8-4-4-4-12)
其中每个 x 是 0-9 或 a-f 范围内的一个十六进制的数字。
<id name="id" column="id">
<generator class="uuid" />
</id>
Hibernate在保存对象时,生成一个UUID字符串作为主键,保证了唯一性,但其并无任何业务逻辑意义,只能作为主键,唯一缺点长度较大,32位(Hibernate将UUID中间的“-”删除了)的字符串,占用存储空间大,但是有两个很重要的优点,Hibernate在维护主键时,不用去数据库查询,从而提高效率,而且它是跨数据库的,以后切换数据库极其方便。
特点:uuid长度大,占用空间大,跨数据库,不用访问数据库就生成主键值,所以效率高且能保证唯一性,移植非常方便,推荐使用。
9、guid
GUID:Globally Unique Identifier全球唯一标识符,也称作 UUID,是一个128位长的数字,用16进制表示。算法的核心思想是结合机器的网卡、当地时间、一个随即数来生成GUID。从理论上讲,如果一台机器每秒产生10000000个GUID,则可以保证(概率意义上)3240年不重复。
<id name="id" column="id">
<generator class="guid" />
</id>
Hibernate在维护主键时,先查询数据库,获得一个uuid字符串,该字符串就是主键值,该值唯一,缺点长度较大,支持数据库有限,优点同uuid,跨数据库,但是仍然需要访问数据库。
注意:长度因数据库不同而不同
MySQL中使用select uuid()语句获得的为36位(包含标准格式的“-”)
Oracle中,使用select rawtohex(sys_guid()) from dual语句获得的为32位(不包含“-”)
特点:需要数据库支持查询uuid,生成时需要查询数据库,效率没有uuid高,推荐使用uuid。
10、foreign
使用另外一个相关联的对象的主键作为该对象主键。主要用于一对一关系中。
<id name="id" column="id">
<generator class="foreign">
<param name="property">user</param>
</generator>
</id>
<one-to-one name="user" class="domain.User" constrained="true" />
该例使用domain.User的主键作为本类映射的主键。
特点:很少使用,大多用在一对一关系中。
11、select
使用触发器生成主键,主要用于早期的数据库主键生成机制,能用到的地方非常少。
12、其他注释方式配置
注释方式与配置文件底层实现方式相同,只是配置的方式换成了注释方式
自动增长,适用于支持自增字段的数据库
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
根据底层数据库自动选择方式,需要底层数据库的设置
如MySQL,会使用自增字段,需要将主键设置成auto_increment。
@Id
@GeneratedValue(strategy = GenerationType.AUTO)
使用表存储生成的主键,可以跨数据库。
每次需要主键值时,查询名为"hibernate_table"的表,查找主键列"gen_pk"值为"2"记录,得到这条记录的"gen_val"值,根据这个值,和allocationSize的值生成主键值。
@Id
@GeneratedValue(strategy = GenerationType.TABLE, generator = "ud")
@TableGenerator(name = "ud",
table = "hibernate_table",
pkColumnName = "gen_pk",
pkColumnValue = "2",
valueColumnName = "gen_val",
initialValue = 2,
allocationSize = 5)
使用序列存储主键值
@Id
@GeneratedValue(strategy = GenerationType.SEQUENCE, generator = "ud")
@SequenceGenerator(name = "ud",
sequenceName = "hibernate_seq",
allocationSize = 1,
initialValue = 2)
13、小结
1、为了保证对象标识符的唯一性与不可变性,应该让Hibernate来为主键赋值,而不是程序。
2、正常使用Hibernate维护主键,最好将主键的setter方法设置成private,从而避免人为或程序修改主键,而使用assigned方式,就不能用private,否则无法给主键赋值。
2、Hibernate中唯一一种最简单通用的主键生成器就是uuid。虽然是个32位难读的长字符串,但是它没有跨数据库的问题,将来切换数据库极其简单方便,推荐使用!
3、自动增长字段类型与序列
|
数据库 |
自动增长字段 |
序列 |
|
MySQL |
是 |
|
|
Oracle |
是 |
|
|
DB2 |
是 |
是 |
|
MS SQL Server |
是 |
|
|
Sybase |
是 |
|
|
HypersonicSQL |
是 |
|
|
PostgreSQL |
是 |
|
|
SAP DB |
是 |
|
|
HSQLDB |
是 |
|
|
Infomix |
是 |
4、关于hilo机制注意:
hilo算法生成的标志只能在一个数据库中保证唯一。
当用户为Hibernate自行提供连接,或者Hibernate通过JTA,从应用服务器的数据源获取数据库连接时,无法使用hilo,因为这不能保证hilo单独在新的数据库连接的事务中访问hi值表,这种情况,如果数据库支持序列,可以使用seqhilo。
5、使用identity、native、GenerationType.AUTO等方式生成主键时,只要用到自增字段,数据库表的字段必须设置成自动增加的,否则出错。
6、还有一些方法未列出来,例如uuid.hex,sequence-identity等,这些方法不是很常用,且已被其他方法代替,如uuid.hex,官方文档里建议不使用,而直接使用uuid方法。
7、Hibernate的各版本主键生成策略配置有略微差别,但实现基本相同。如,有的版本默认sequence不指定序列名,则使用名为hibernate_sequence的序列,有的版本则必须指定序列名。
8、还可以自定义主键生成策略,这里暂时不讨论,只讨论官方自带生成策略。
Hibernate使用
测试:
1 package com.hanqi.test; 2 3 import java.io.Serializable; 4 import java.math.BigDecimal; 5 import java.util.Date; 6 7 import org.hibernate.Session; 8 import org.hibernate.SessionFactory; 9 import org.hibernate.Transaction; 10 import org.hibernate.boot.registry.StandardServiceRegistryBuilder; 11 import org.hibernate.cfg.Configuration; 12 import org.hibernate.service.ServiceRegistry; 13 import org.junit.After; 14 import org.junit.Before; 15 import org.junit.Test; 16 17 import com.hanqi.model.CrmUsers; 18 19 public class JUtest { 20 21 private SessionFactory sessionFactory; 22 private Session session; 23 private Transaction transaction; 24 25 @Before 26 public void setUp() throws Exception { 27 System.out.println("开始初始化……"); 28 Configuration configuration=new Configuration().configure("hibernate.cfg.xml");//该属性可以不传值,会自动寻找默认目录下的hibernate.cfg.xml,如果该文件在其他目录中,需要在此指定路径 29 30 ServiceRegistry serviceRegistry=new StandardServiceRegistryBuilder().applySettings(configuration.getProperties()).build(); 31 32 sessionFactory=configuration.buildSessionFactory(serviceRegistry); 33 session=sessionFactory.openSession(); 34 transaction=session.beginTransaction(); 35 System.out.println("初始化完毕"); 36 } 37 38 @After 39 public void tearDown() throws Exception { 40 System.out.println("释放资源"); 41 transaction.commit(); //提交 42 session.close(); 43 sessionFactory.close(); 44 System.out.println("关闭"); 45 //以上顺序不能改变 46 } 47 48 @Test 49 public void test() { 50 //使用session.save方法向表中添加数据 51 CrmUsers cu=new CrmUsers(); 52 cu.setId(new BigDecimal(3)); 53 cu.setCreatetime(new Date()); 54 Serializable i= session.save(cu); 55 System.out.println("------------"+i); 56 57 } 58 }
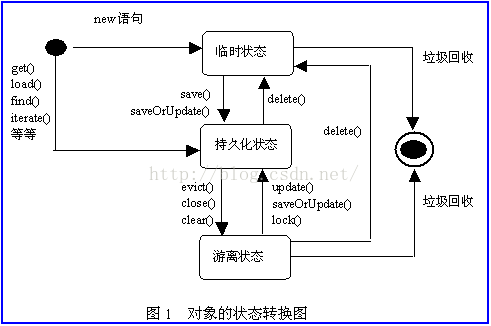
实体类三种状态演变:
session.get() 方法查询:
1 @Test 2 public void test() { 3 //查询 4 CrmUsers cu=(CrmUsers) session.get(CrmUsers.class ,new BigDecimal(3)); 5 System.out.println(cu); 6 }


先查询在修改,持久化操作:
1 @Test 2 public void test() { 3 //查询 4 CrmUsers cu=(CrmUsers) session.get(CrmUsers.class ,new BigDecimal(3)); 5 System.out.println(cu); 6 cu.setRealname("闻道于事"); 7 }

删除,需要先实例化一个实体类,然后再实现时候hibernate会先查出来在删除:
1 @Test 2 public void test() { 3 CrmUsers cu=new CrmUsers(); 4 cu.setId(new BigDecimal(3)); 5 session.delete(cu); 6 }


hibernate正向工程
创建实体类:
考虑到主键自动生成,所以多加一个没有id的实参构造方法
1 package com.hanqi.model; 2 3 import java.util.Date; 4 5 public class News { 6 private int id; 7 private String title; 8 private String content; 9 private String author; 10 private Date redate; 11 12 public News() { 13 super(); 14 } 15 16 public News(String title, String content, String author, Date redate) { 17 super(); 18 this.title = title; 19 this.content = content; 20 this.author = author; 21 this.redate = redate; 22 } 23 24 public News(int id, String title, String content, String author, Date redate) { 25 super(); 26 this.id = id; 27 this.title = title; 28 this.content = content; 29 this.author = author; 30 this.redate = redate; 31 } 32 33 public int getId() { 34 return id; 35 } 36 37 public void setId(int id) { 38 this.id = id; 39 } 40 41 public String getTitle() { 42 return title; 43 } 44 45 public void setTitle(String title) { 46 this.title = title; 47 } 48 49 public String getContent() { 50 return content; 51 } 52 53 public void setContent(String content) { 54 this.content = content; 55 } 56 57 public String getAuthor() { 58 return author; 59 } 60 61 public void setAuthor(String author) { 62 this.author = author; 63 } 64 65 public Date getRedate() { 66 return redate; 67 } 68 69 public void setRedate(Date redate) { 70 this.redate = redate; 71 } 72 73 @Override 74 public String toString() { 75 return "News [id=" + id + ", title=" + title + ", content=" + content + ", author=" + author + ", redate=" 76 + redate + "]"; 77 } 78 79 }
创建映射文件:

建立hibernate总配置文件:
如果还没有建立连接,需要再次创建连接:

生成配置文件:
1 <?xml version="1.0" encoding="UTF-8"?> 2 <!DOCTYPE hibernate-configuration PUBLIC 3 "-//Hibernate/Hibernate Configuration DTD 3.0//EN" 4 "http://hibernate.sourceforge.net/hibernate-configuration-3.0.dtd"> 5 <hibernate-configuration> 6 <session-factory> 7 <property name="hibernate.connection.driver_class">oracle.jdbc.OracleDriver</property> 8 <property name="hibernate.connection.password">test</property> 9 <property name="hibernate.connection.url">jdbc:oracle:thin:@localhost:1521:xe</property> 10 <property name="hibernate.connection.username">test</property> 11 <property name="hibernate.default_schema">TEST</property> 12 <property name="hibernate.dialect">org.hibernate.dialect.Oracle10gDialect</property> 13 14 <!-- 在控制台打印SQL语句 --> 15 <property name="hibernate.show_sql">true</property> 16 <property name="hibernate.format_sql">true</property> 17 <!-- 自动建表策略 --> 18 <property name="hibernate.hbm2ddl.auto">update</property> 19 20 <mapping resource="com/hanqi/model/News.hbm.xml"/> 21 </session-factory> 22 </hibernate-configuration>
然后新加一个测试,test中不需要内容直接运行,hibernate就会在数据库中创建表:
1 package com.hanqi.util; 2 3 import static org.junit.Assert.*; 4 5 import org.hibernate.Session; 6 import org.hibernate.SessionFactory; 7 import org.hibernate.Transaction; 8 import org.hibernate.boot.registry.StandardServiceRegistryBuilder; 9 import org.hibernate.cfg.Configuration; 10 import org.hibernate.service.ServiceRegistry; 11 import org.junit.After; 12 import org.junit.Before; 13 import org.junit.Test; 14 15 public class JUTest { 16 17 private SessionFactory sessionFactory; 18 private Session session; 19 private Transaction transaction; 20 21 22 @Before 23 public void setUp() throws Exception { 24 System.out.println("开始初始化……"); 25 Configuration configuration=new Configuration().configure("hibernate.cfg.xml"); 26 27 ServiceRegistry serviceRegistry=new StandardServiceRegistryBuilder().applySettings(configuration.getProperties()).build(); 28 29 sessionFactory=configuration.buildSessionFactory(serviceRegistry); 30 session=sessionFactory.openSession(); 31 transaction=session.beginTransaction(); 32 System.out.println("初始化完毕"); 33 } 34 35 @After 36 public void tearDown() throws Exception { 37 System.out.println("释放资源"); 38 transaction.commit(); //提交 39 session.close(); 40 sessionFactory.close(); 41 } 42 43 @Test 44 public void test() { 45 46 } 47 48 }
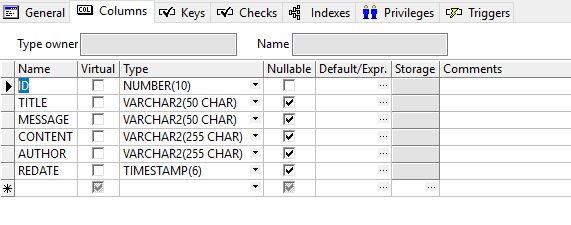
在控制台看到这个就表示数据库更新成功:

HQL语句:
HQL是Hibernate Query Language的缩写,提供更加丰富灵活、更为强大的查询能力;HQL更接近SQL语句查询语法。
需要注意的是在HQL语句中,form后面跟的不是表名,而是实体类
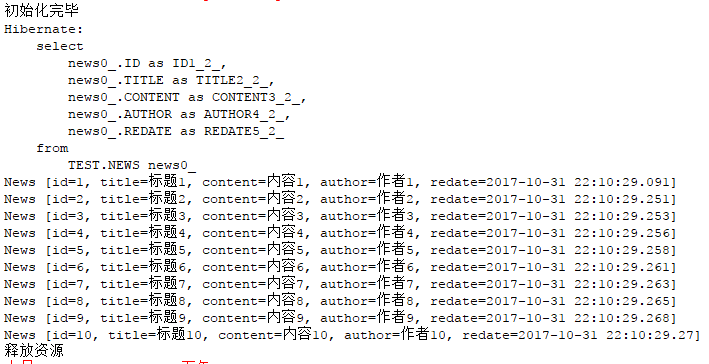
1 //批量添加数据 2 // for(int i=1;i<11;i++) { 3 // News news = new News("标题"+i, "内容"+i, "作者"+i, new Date()); 4 // session.save(news); 5 // } 6 7 //全表查询 8 String hql = "from News"; 9 10 Query query = session.createQuery(hql); 11 12 List<News> list = query.list(); 13 for(News n : list) { 14 System.out.println(n); 15 }
条件查询:
参数名称绑定
参数位置绑定
setParameter()方法
setParameterList(集合或者数组)方法
setProperties()方法
参数名称绑定和参数位置绑定:
1 //条件查询 2 //参数位置绑定 setParameter()方法 3 String hql = "from News as n where n.id =?"; 4 5 Query query = session.createQuery(hql) 6 .setParameter(0, 10); 7 8 List<News> list = query.list(); 9 for(News n : list) { 10 System.out.println(n); 11 } 12 //参数名称绑定 setParameterList(集合或者数组)方法 13 // String hql = "from News as n where n.id in :ids"; 14 // 15 // Query query = session.createQuery(hql) 16 // .setParameterList("ids", new Object[]{23, 28}); 17 // 18 // List<News> list = query.list(); 19 // for(News n : list) { 20 // System.out.println(n); 21 // }
hibernate框架一对一和一对多
首先用反向工程把两个具有主外键关系的表生成实体类:
生成的配置文件:
1 <?xml version="1.0"?> 2 <!DOCTYPE hibernate-mapping PUBLIC "-//Hibernate/Hibernate Mapping DTD 3.0//EN" 3 "http://www.hibernate.org/dtd/hibernate-mapping-3.0.dtd"> 4 <!-- Generated 2017-10-31 14:20:12 by Hibernate Tools 4.3.1.Final --> 5 <hibernate-mapping> 6 <class name="com.hanqi.model.Emp" table="EMP" optimistic-lock="version" lazy="false"> 7 <id name="empno" type="int"> 8 <column name="EMPNO" precision="8" scale="0" /> 9 <generator class="sequence"> 10 <param name="sequence">sq_emp</param> 11 </generator> 12 </id> 13 <many-to-one name="dept" class="com.hanqi.model.Dept" fetch="select"> 14 <column name="DEPTNO" precision="8" scale="0" /> 15 </many-to-one> 16 <property name="ename" type="string"> 17 <column name="ENAME" length="320" /> 18 </property> 19 <property name="birthday" type="date"> 20 <column name="BIRTHDAY" length="7" /> 21 </property> 22 <property name="sals" type="java.lang.Integer"> 23 <column name="SALS" precision="7" scale="0" /> 24 </property> 25 <property name="sex" type="java.lang.Byte"> 26 <column name="SEX" precision="2" scale="0" /> 27 </property> 28 <property name="hiredate" type="date"> 29 <column name="HIREDATE" length="7" /> 30 </property> 31 <property name="level" type="string"> 32 <formula>(select (CASE WHEN e.sals <![CDATA[<]]> 5000 33 THEN '普通' ELSE '高级' END) 34 from emp e where e.empno=empno)</formula> 35 </property> 36 </class> 37 </hibernate-mapping>
1 <?xml version="1.0"?> 2 <!DOCTYPE hibernate-mapping PUBLIC "-//Hibernate/Hibernate Mapping DTD 3.0//EN" 3 "http://www.hibernate.org/dtd/hibernate-mapping-3.0.dtd"> 4 <!-- Generated 2017-10-31 14:20:12 by Hibernate Tools 4.3.1.Final --> 5 <hibernate-mapping> 6 <class name="com.hanqi.model.Dept" table="DEPT" optimistic-lock="version"> 7 <id name="deptno" type="int"> 8 <column name="DEPTNO" precision="8" scale="0" /> 9 <generator class="sequence"> 10 <param name="sequence">sq_dept</param> 11 </generator> 12 </id> 13 <property name="dname" type="string"> 14 <column name="DNAME" length="320" /> 15 </property> 16 <property name="loc" type="string"> 17 <column name="LOC" length="320" /> 18 </property> 19 <set name="emps" table="EMP" inverse="true" lazy="false" fetch="select"> 20 <key> 21 <column name="DEPTNO" precision="8" scale="0" /> 22 </key> 23 <one-to-many class="com.hanqi.model.Emp" /> 24 </set> 25 </class> 26 </hibernate-mapping>
可以看到两个配置文件中:
1 optimistic-lock="version" : 乐观锁
1 <many-to-one name="Dept" class="com.hanqi.model.Dept" fetch="select"> 2 <column name="DEPTNO" precision="22" scale="0" /> 3 </many-to-one> 多对一
1 <set name="Emp" table="Emp" inverse="true" lazy="true" fetch="select"> 2 <key> 3 <column name="DEPTNO" precision="22" scale="0" /> 4 </key> 5 <one-to-many class="com.hanqi.model.Emp" /> 6 </set> 一对多
通过session.get方法和session.load方法进行查询:
1 @Test 2 public void test() { 3 //通过get方法查询: 4 Dept pd=(Dept)session.get(Dept.class,1); 5 System.out.println("get:"+pd); 6 7 //通过load方法查询: 8 Dept pd1=(Dept)session.load(Dept.class,1); 9 System.out.println("get:"+pd1); 10 }
两种方法的却别在于:
get:
使用get方法查询一条没有的记录会返回null
load:
使用load方法差一条没有的记录会报错
load方法支持延迟加载
进行查询,使用 formula 标签。
比如查询员工工资等级
在实体类中加一个成员变量 level,添加get/set方法
在配置文件中加:
1 <property name="level" type="string"> 2 <formula>(select (CASE WHEN e.sals <![CDATA[<]]> 5000 3 THEN '普通' ELSE '高级' END) 4 from emp e where e.empno=empno)</formula> 5 </property>
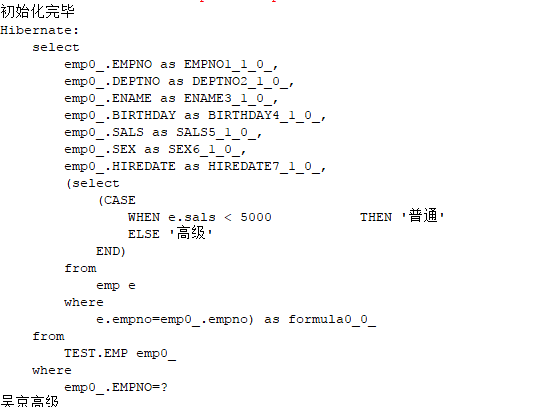
然后就可以进行查询了:
1 @Test 2 public void test() { 3 //通过load方法查询: 4 Emp e=(Emp)session.load(Emp.class,6); 5 System.out.println(e.getEname()+e.getLevel()); 6 }
一对多查询:
1 @Test 2 public void test() { 3 //通过部门主键查部门的员工 4 String hql = "from Emp as e where e.dept.deptno=1"; 5 List<?> list = session.createQuery(hql).list(); 6 for(Object e : list) { 7 System.out.println(e); 8 } 9 }


1 @Test 2 public void test() { 3 //模糊查询 4 String hql = "select new map(e.ename as en, e.sals as es) from Emp as e " 5 + "where e.dept.dname like '%发%'"; 6 List<?> list = session.createQuery(hql).list(); 7 for(Object e : list) { 8 System.out.println(e); 9 } 10 }

一对多的几种写法:
使用构造方法,需要需要有对应的构造犯法,输出输出所有属性
1 //使用指定的构造方法 2 String hql3 = "select new Emp(e.ename as en, e.sals as es) from Emp as e " 3 + "where e.dept.dname like '%发%'"; 4 List<Emp> list3 = session.createQuery(hql3).list(); 5 for(Object e1 : list3) { 6 System.out.println(e1); 7 }

使用map方式:
1 //使用map方式 2 String hql1 = "select new map(e.ename as en, e.sals as es) from Emp as e " 3 + "where e.dept.dname like '%发%'"; 4 List<?> list1 = session.createQuery(hql1).list(); 5 for(Object e : list1) { 6 System.out.println(e); 7 }

使用list方式:
1 // //使用集合方式 2 String hql2 = "select new list(e.ename as en, e.sals as es) from Emp as e " 3 + "where e.dept.dname like '%发%'"; 4 List<?> list2 = session.createQuery(hql2).list(); 5 for(Object e : list2) { 6 System.out.println(e); 7 }

悲观锁和乐观锁:
悲观锁(Pessimistic Lock), 顾名思义,就是很悲观,每次去拿数据的时候都认为别人会修改,所以每次在拿数据的时候都会上锁,这样别人想拿这个数据就会block直到它拿到锁。传统的关系型数据库里边就用到了很多这种锁机制,比如行锁,表锁等,读锁,写锁等,都是在做操作之前先上锁。
乐观锁(Optimistic Lock), 顾名思义,就是很乐观,每次去拿数据的时候都认为别人不会修改,所以不会上锁,但是在更新的时候会判断一下在此期间别人有没有去更新这个数据,可以使用版本号等机制。乐观锁适用于多读的应用类型,这样可以提高吞吐量,像数据库如果提供类似于write_condition机制的其实都是提供的乐观锁。
两种锁各有优缺点,不可认为一种好于另一种,像乐观锁适用于写比较少的情况下,即冲突真的很少发生的时候,这样可以省去了锁的开销,加大了系统的整个吞吐量。但如果经常产生冲突,上层应用会不断的进行retry,这样反倒是降低了性能,所以这种情况下用悲观锁就比较合适。