转自:https://www.cnblogs.com/suanec/p/12530947.html
F1-Score相关概念
- F1分数(F1 Score),是统计学中用来衡量二分类(或多任务二分类)模型精确度的一种指标。它同时兼顾了分类模型的准确率和召回率。
- F1分数可以看作是模型准确率和召回率的一种加权平均,它的最大值是1,最小值是0,值越大意味着模型越好。
- 假如有100个样本,其中1个正样本,99个负样本,如果模型的预测只输出0,那么正确率是99%,这时候用正确率来衡量模型的好坏显然是不对的。
| label-1 | label-0 | |
|---|---|---|
| pre-1 | True Positive(TP)真阳性 | False Positive(FP)假阳性 |
| pre-0 | False Negative(FN)假阴性 | True Negative(TN)真阴性 |
F-Beta
- 查准率(precision),指的是预测值为1且真实值也为1的样本在预测值为1的所有样本中所占的比例。以西瓜问题为例,算法挑出来的西瓜中有多少比例是好西瓜。
precision = frac{TP}{TP+FP}
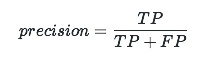
- 召回率(recall),也叫查全率,指的是预测值为1且真实值也为1的样本在真实值为1的所有样本中所占的比例。所有的好西瓜中有多少比例被算法挑了出来。
recall = frac{TP}{TP+FN}

- F1分数(F1-Score),又称为平衡F分数(BalancedScore),它被定义为精确率和召回率的调和平均数。
F_1 = 2 cdot frac{precisiont cdot recall}{precision + recall}

- 更一般的,我们定义Fβ分数为:
F_eta = (1 + eta^2) cdot frac{precisiont cdot recall}{(eta^2 cdot precision) + recall}
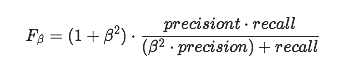
- 除了F1分数之外,F0.5分数和F2分数,在统计学中也得到了大量应用,其中,F2分数中,召回率的权重高于精确率,而F0.5分数中,精确率的权重高于召回率。
Macro-F1和Micro-F1
- Macro-F1和Micro-F1是相对于多标签分类而言的。
- Micro-F1,计算出所有类别总的Precision和Recall,然后计算F1。
- Macro-F1,计算出每一个类的Precison和Recall后计算F1,最后将F1平均。