一、目标
*开发工具:CodeBlocks
*开发语言:C++
*源代码管理Github链接:https://github.com/Snoopyjinjin/cipin
二、要求
实现一个控制台程序,给定一段英文字符串,统计其中各个英文单词(4字符以上含4字符)的出现频率。
附加要求:读入一段文本文件,统计该文本文件中单词的频率。
三、思路分析
一个单词的结束是以非字母的形式结尾,所以应把单词分开。创建数组用来存储单词字符,并从磁盘中导入含有英文单词的文本文档。在这里,我本来打算是直接从键盘上输入一长串字符的,如老师示例给的单词数较少,直接键入也行,但如果单词数较多,直接键入容易出错,也比较浪费时间,所以宜把它存入文本文档再进行读取。后来我在附加条件中也看到了该要求。
原本预计完成这次作业需要一下午的时间,但天不遂人愿,我用了一下午加一晚上的时间才完成。哎,果然能力捉急呀/(ㄒoㄒ)/~~
四、源码
#include <iostream> #include <cstring> #include <fstream> using namespace std; typedef struct word { int count; char word[WORD_LEN]; } struct Stack { Word wd[1000]; int count; void push(char* word) { for(int i=0;i<count;i++) { if(strcmp(wd[i].word,word)==0) return; } wd[count].word=word; wd[count].ref=1; count++; } void main() { Stack st; st.count=0; fstream ("G:\英文.txt","r"); char* buf=(char*)malloc(10000); int len=fread(buf,1,10000,fa); char* word=buf; //全部转为小写 for(int i=0;i<len;i++) { if(buf[i]>='A' && buf[i]<='Z') buf[i]+='a'-'A'; } for(i=0;i<len;i++) { if(buf[i]<'a' || buf[i]>'z') { buf[i]='�'; st.push(word); while(buf[i]<'a' || buf[i]>'z') i++; word=&buf[i]; } } in.close(); }
五、调试与检验
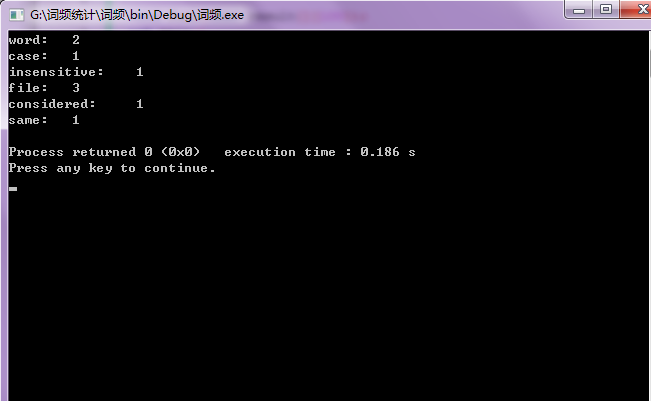
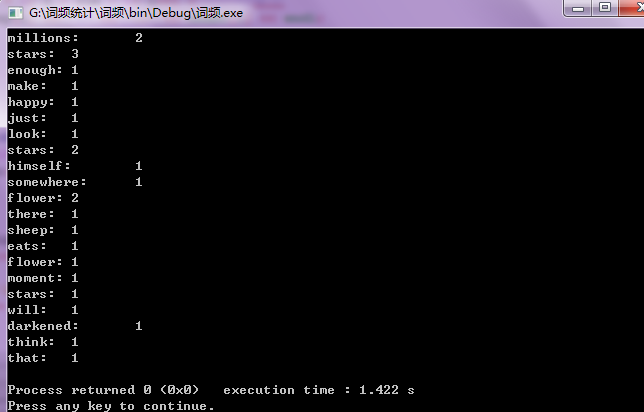
上图是老师给的示例的运行情况,下面是导入一段较长文本的运行结果,果然,直接导入文件远比键盘键入来的快捷的多,毕竟单词多嘛。
检验:看程序运行的对不对,就看它统计的字数对不对啦。若是单词数少的话,还可以通过数数解决,若多的话就不行了。我把文本导入word,用工具栏里的查找功能进行检验,看每个单词统计的对否;还有一种就是在工具栏的宏里边设置参数调试,不过这个有点复杂,我后来就没做。当然了,后一种高大上的方法是我百度查来的。
六、作业总结
通过这个词频统计的小程序,我掌握了基本的分割单词的能力,再一次巩固了C++。另外,在设计时,我也明白了“化繁为简”的重要性,比如:用文本文件导入单词就远比直接键入来的简易的多。所以在以后的编程时,遇到复杂的地方,我也许可以试着换一个角度试试。最后,对于我们常用的一些工具软件,应多多熟悉它的性能,不然等到用时就手忙脚乱了。