SQL语句的分类
SQL的中文名称为结构化查询语言(Structured Query Language,SQL),它是关系数据库的标准语言。其功能不仅仅是查询,而是集数据查询、数据操纵、数据定义、数据控制功能于一体。
所以,SQL语句可以分为如下四大类:
数据查询语言(Data Query Language,DQL);
数据操纵语言(Data Manipulation Language,DML);
数据定义语言(Data Definition Language,DDL);
数据控制语言(Data Control Language,DCL);
在SQL标准中,DQL包括select动词,用于检索数据;DML包括insert、update和delete动词,用于数据的操纵,改变数据库中的数据,例如增加或删除一些数据等;DDL包括动词create、drop和alter,用于定义模式、表、视图和索引;DCL包括动词grant和revoke,用于授予或回收用户的权限。
在MySQL中,没有DQL,它将select也归为DML,所以DML包括select、insert、update和delete,此外还有call(调用存储过程)、load(导入数据)、replace(替代)等动词;DDL除了create、drop和alter外还有truncate(删除表数据)和rename(重命名表)。
子查询的分类
1、带有IN或NOT IN谓词的子查询
这类查询是最常见的子查询,此时子查询的返回值可以是同列的一个或者多个值。
2、带有比较运算符的子查询
这类子查询是指父查询与子查询之间用比较运算符进行连接,因此子查询的返回值应当为单个值。常用到的比较运算符有<、>、=、>=、<=、!=或<>等
3、带有ANY或ALL谓词的子查询
当子查询的返回值为多个时,父查询与子查询之间用ANY或ALL谓词进行连接,使用ANY或ALL谓词时则必须同时使用比较运算符。语义如下:
>ANY 大于子查询结果中的某个值(即大于最小的值)
>ALL 大于子查询结果中的所有值(即大于最大的值)
<ANY 小于子查询结果中的某个值(即小于最大的值)
<ALL 小于子查询结果中的所有值(即小于最小的值)
=ANY 等于子查询结果中的某个值
=ALL 等于子查询结果中的所有值
!=ANY 不等于子查询结果中的某个值
!=ALL 不等于子查询结果中的任何一个值
4、带有exists或not exists谓词的子查询
带有exists谓词的子查询不返回任何数据,只产生逻辑真值或逻辑假值。带有exists或not exists谓词的子查询都是相关子查询。
含有exists谓词的语句执行时,对外表采用遍历方式逐条查询,每次查询都会比较exists的条件语句(即子查询中的where条件),当exists里的条件语句成立时,则返回外表中的这条记录,反之当条件语句不成立时,则不返回外表中的这条记录。对not exists来说,与exists相反,当子查询中的条件语句不成立时则返回外表中这条记录。
5、基于派生表的子查询
子查询出现在查询语句的from子句中,这时子查询生成的临时派生表成为主查询的查询对象。
注:
1、SQL语言允许多层嵌套查询,即一个子查询中还可以嵌套其他子查询;
2、子查询中不能使用order by子句,因为order by子句只能对最终的结果进行排序;
3、从另一个角度来说,子查询可以分为相关子查询和非相关子查询。如果子查询中的查询条件不依赖与父查询,这类子查询为不相关子查询;如果子查询中的查询条件依赖于父查询,这类子查询为相关子查询。
JOIN的分类
1、内连接(inner join)
·等值连接与非等值连接:
当连接条件中连接运算符为“=”时,称为等值连接,使用其他运算符的称为非等值连接。
·自然连接(natural join):
是一种特殊的等值连接,它要求两个表中进行连接操作的字段必须是同名的,并且在结果中把重复的属性列去掉。
2、外连接(outer join)
当两个表连接时,将悬浮元组也保存在结果集中,而在其他字段上填NULL值,这种连接方式称为外连接。分为左外连接和右外连接:
左外连接(left join),保存left join左边表的悬浮元组;
右外连接(right join),保存right join右边的表的悬浮元组;
Where和having的区别
Where子句与having短语的区别在于作用对象不同。Where子句作用于基本表或视图,having短语作用于组。所以where子句中是不能用聚集函数作为条件表达式的。
在MySQL数据库中,having短语也可以作用于表和视图。如下所示:

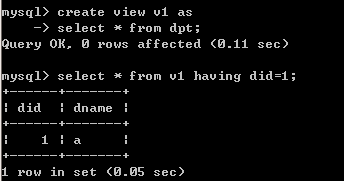
但是在习惯上,还是让having作用于组,即和group by搭配使用。
DISTINCT和GROUP BY的区别
DISTINCT是对查询语句的最终结果集去掉重复的数据行;而GROUP BY是对指定的列进行分组,一般会在查询语句的select后面用到聚合函数。
DISTINCT只能进行去重,GROUP BY更侧重于对数据分组后再聚合,但也可以实现去重。例如我们想知道有哪些学生选了课,通过DISTINCT和GROUP BY都可以实现(表sc上没有索引):
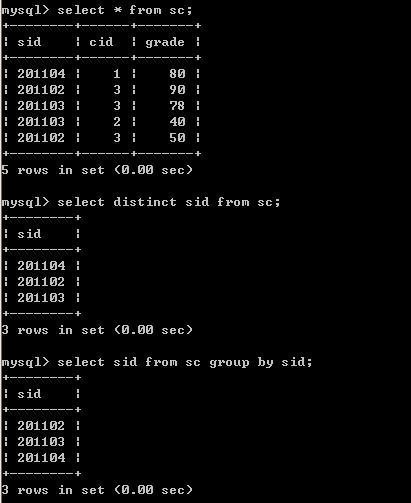
仔细观察后两条SQL输出的结果,发现数据的排序是不一样的。有DISTINCT的SQL在执行时,直接取出sc表的sid列放到内存中,然后去掉重复值;而带有GROUP BY的SQL执行时,对sid进行了排序分组,故输出的结果是有序的。