什么是查询呢?
查询是对已有表中的数据按照某种条件进行筛选,将满足条件的数据筛选出来形成一个新的记录集进行显示,也称为查询结果记录集,
这个记录集的结构与表的结构类似,由行和列组成,但它并不是真正存放在数据库中的表, 而是一种存放在计算机内存中的虚拟表。
若省略查询条件,则返回数据源中的所有记录行。
查询是查找和筛选功能的扩充,它不但能实现数据检索,而且可以在查询过程中进行计算、合并不同数据源的数据,甚至可以添加、更改或删除基本表中的数据。
查询的数据源
查询的数据源(也称为“记录源”,RecordSource)是存放在数据库中的基本表或已经创建好的视图,可以有一个或多个数据源。
若是多个数据源,则需指定这些数据源之间的关联关系,以保证查询结果的正确性
查询的结果
查询的结果只有在运行查询时才会产生,因此也称为动态结果记录集,这个结果集的显示可以通过前面我们所学过的视图来实现。
数据查询是数据库的核心操作。SELECT语句是SQL语言中功能最强大的语句。

语句格式
SELECT [ALL|DISTINCT] <目标列表达式> [,<目标列表达式>] ....
FROM <表名或视图名>[,< 表名或视图名> ] .... (SELECT语句)[AS]<别名>
[WHERE<条件表达式>]
[GROUP BY<列名1>[ HAVING<条件表达式> ] ]
[ ORDER BY <列名2> [ ASC|DESC ] ] ;
SELECT子句:指定要显示的属性列
FROM子句:指定查询对象(基本表或视图)
WHERE子句:指定查询条件
GROUP BY子句:对查询结果按指定列的值分组,该属性列值相等的元组为一个组。通常会在每组中作用聚集函数。
HAVING短语:只有满足指定条件的组才予以输出
ORDER BY子句: 对查询结果表按指定列值的升序
单表查询
查询仅涉及一个表,是一种最简单的查询操作
1.选择表中的若干列(列查询)
2.选择表中的若干元组(行查询)
3.对查询结果排序
4.使用聚集函数
单表查询语句基本格式:
[USE 数据库名称]
select 目标列表达式 [......n]
from 表名
where 条件(表达式)
[ORDER BY排序条件]
列查询
1.查询指定列
例:查询全体学生的学号和姓名
select sno,sname from student
2.查询全部列
例:查询全体学生的详细记录
select sno,sname,sgender,sage,sdept from student select * from student
3.查询经过计算的值
SELECT子句的<目标列表达式>为表达式(算术表达式、字符串常量、函数、列别名)
例:查询全体学生的姓名、出生年份和所在系,要求用小写字母表示所有系名,并使用列别名改变查询结果的列标题
select sname as 'name',year(getdate())-year(cssj) as '年龄','Year of Birth:' as 'Birth:',year(getdate())-sage as 'BirthDay',lower(sdept) 'department' from student
选择表中的若干元组
1.取消取值重复的行
在SELECT子句中使用DISTINCT短语
select /*(默认 ALL)*/ sno from sc select distinct sno,cgrade from sc
注意DISTINCT短语的作用范围是所有目标列
2.查询满足条件的元组
| 查询条件 | 谓词 |
| 比较 | =、>、<、>=、<=、!=、<>、!>、!<、NOT+其他比较运算符 |
| 确定范围 | BETWEEN...AND...、NOT BETWEEN...AND... |
| 确定集合 | IN、NOT IN |
| 字符匹配 | LIKE、NOT LIKE |
| 空值 | IS NULL、NOT IS NULL |
| 多重条件 | AND、OR |
(1)比较大小
(2)确定范围
(3)确定集合
例:查询系别为IS、MA、CS的学生信息
select * from student where sdept IN('IS','MA','CS')
(4)字符串匹配
[NOT] LIKE ‘< 匹配串>’ [ESCAPE ‘<换码字符>’]
<匹配串>:指定匹配模板
匹配模板:固定字符串或含通配符的字符串
当匹配模板为固定字符串时,
可以用 = 运算符取代 LIKE 谓词,用 != 或 <> 运算符取代 NOT LIKE 谓词
通配符
% (百分号)代表任意长度(长度可以为0)的字符串
例: a%b 表示以a开头,以b结尾的任意长度的字符串。如acb,addgb,ab等都满足该匹配串。
_( 下横线)代表任意单个字符
例: a_b表示以a开头,以b结尾的长度为3的任意字符串。如acb,afb等都满足该匹配串。
ESCAPE短语:
当用户要查询的字符串本身就含有 % 或 _ 时,要使用ESCAPE '<换码字符>' 短语对通配符进行转义。
匹配模板为固定字符串
例:查询学号为95001的学生的详细情况
select * from student where sno like '95001'/*等价于where sno = '95001'*/
匹配模板为含通配符的字符串
例:查询名字中第2个字为‘阳’字的学生的详细信息
select * from student where sname like '_阳%'
使用换码字符将通配符转义为普通字符
例:查询以“DB_”开头,且倒数第三个字符为'i'的课程的详细情况
select * from course where cname like 'DB\_%i__' escape ''
(5)涉及空表的查询
使用谓词IS NULL或IS NOT NULL ( “IS NULL”不能用“= NULL”代替 )
(6)多重条件查询
用逻辑运算符AND和OR来联结多个查询条件 ( AND的优先级高于OR,但可以用括号改变优先级 )
连接查询
连接查询是同时涉及多个表的查询
连接查询概念:
同时涉及多个表的查询称为连接查询
用来连接两个表的条件称为连接条件或连接谓词
连接谓词中的列名称为连接字段
注意:连接条件中的各字段类型必须是可比的,但字段名不必是相同的
连接查询的执行过程
首先在表1中找到第一个元组,然后从头开始扫描表2,逐一查找满足连接条件的元组,找到后就将表1中的第一个元组与该元组拼接起来,形成结果表中一个元组。
表2全部查找完后,再找表1中第二个元组,然后再从头开始扫描表2,逐一查找满足连接条件的元组,找到后就将表1中的第二个元组与该元组拼接起来,形成结果表中一个元组。
重复上述操作,直到表1中的全部元组都处理完毕。
连接操作说明
SQL的连接操作是通过关联表间的行的匹配而产生的结果。
参与连接的表可以有多个,但连接操作在两个表之间进行,即两两连接。
连接查询的主要内容
SQL中连接查询的主要类型
1.广义笛卡尔积
不带连接谓词的连接,很少使用
2.等值连接查询
连接运算符为 ‘=’的连接操作注意事项:
[<表名1>.]<列名1> = [<表名2>.]<列名2>
任何子句中引用表1和表2中同名属性时,都必须加表名前缀。引用唯一属性名时可以加也可以省略表名前缀。
3.非等值连接查询
连接运算符不是‘=’的连接操作
SQL连接的类型
1.利用别名查询
2.内连接查询
3.外连接查询
4.自身连接查询
使用表别名进行查询
USE stu select s.sno,s.sname,s.sdept from student as s
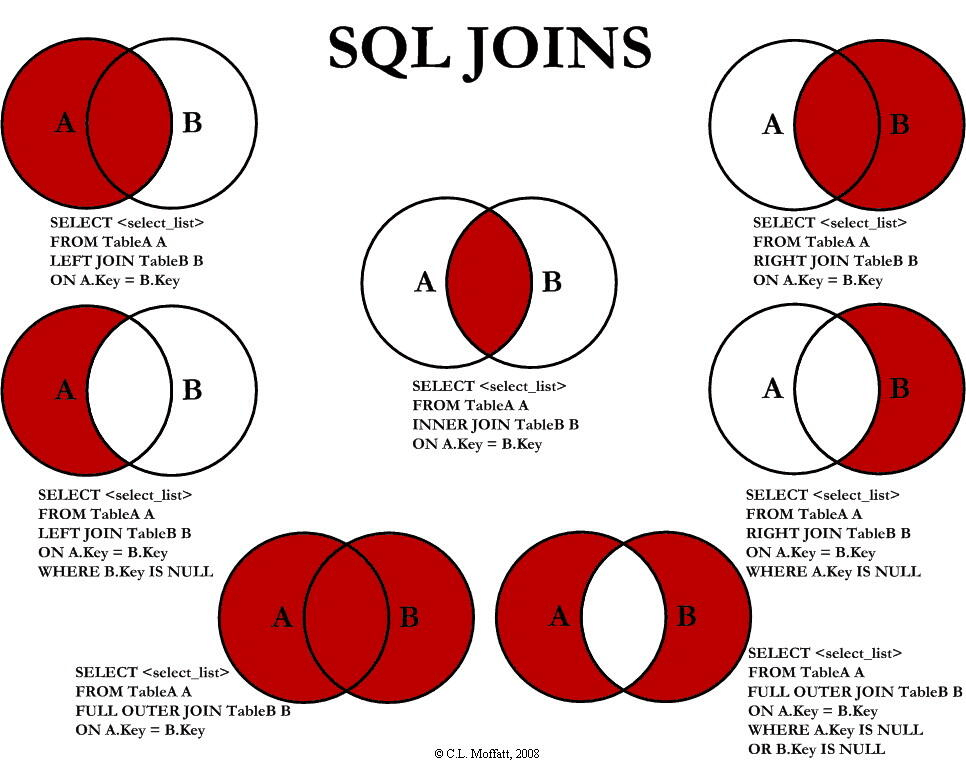
内连接查询(INNER JOIN)
内连接时,如果两个表的相关字段满足连接条件,就从这两个表中提取数据并组合成新的记录。只有满足条件的记录才能出现在结果集中。
根据比较方式,内连接分为三种:
1.等值连接
使用=运算符比较被连接列的列值。
2.非等值连接
使用>、>=、<、<=、!>、!<和<>号进行比较运算的连接。
3.自然连接
等值连接的特殊情形,是去掉重复列的等值连接。
内连接查询中的各个表地位平等,无主从关系。
以下两种写法等同
USE stu select s.sno,sname,sdept,cno,cgrade from student as s inner join sc on s.sno=sc.sno USE stu select s.sno,sname,sdept,cno,cgrade from student as s,sc where s.sno=sc.sno
再加一个条件:cno要等于‘1’
USE stu select s.sno,sname,sdept,cno,cgrade from student as s inner join sc on s.sno=sc.sno where sc.cno='1' USE stu select s.sno,sname,sdept,cno,cgrade from student as s,sc where s.sno=sc.sno and sc.cno='1'
外连接查询
外连接是只限制一张表中的数据必须满足连接条件,而另一张表中的数据可以不满足连接条件的连接方式。
包括以下三种类型:
1.左外连接(LEFT OUTER J0IN )
2.右外连接( RIGHT OUTER J0IN)
3.全外连接( FULL OUTER J0IN )
外连接查询中的各个表地位不平等,有主从分别。
(1)左连接
是以“连接关键字”左边表为主表。输出结果以主表元组为基础,从表无对应信息则显示空值。
是限制连接关键字右端的表中的数据必须满足连接条件,而不管左端表中的数据是否满足条件,均输出左端表中的内容。
例:
USE stu select s.sno,sname,sdept,cno,cgrade from student as s left outer join sc on s.sno=sc.sno
说明:该例子表明,不过学生有没有选课,都会输出到结果中
(2)右连接
以“连接关键字”右边表为主表。输出结果以“主表”元组为基础,“从表” 无对应信息则显示空值。
与左外连接类似,是右端表中的所有记录都输出,限制左端表的数据必须满足连接条件。
例:
USE stu select s.sno,sname,sdept,cno,cgrade from student as s right outer join sc on s.sno=sc.sno
说明:只有选课的学生,才会在结果中输出
(3)完全连接
不分主、从表。输出结果以“表”所有元组为基础,无对应信息则显示空值。
全外连接查询的特点是左、右两端表中的记录都输出,如果没能找到匹配的元组,就使用NULL来代替。
例:
USE stu select s.sno,sname,sdept,cno,cgrade from student as s full outer join sc on s.sno=sc.sno
说明:全外连接查询中所有表中的记录信息都保留在结果集中。
(4)自身连接
一个表与其自己进行连接,称为表的自身连接
需要给表起别名以示区别
由于所有属性名都是同名属性,因此必须使用别名前缀
例:查询每一门课的间接先修课(即先修课的先修课)
select first.cno,second.cpno from course as first,course as second where first.cpno=second.cno
数据汇总查询
主要内容:
- 聚合函数
- order by子句
- group by子句
- having 子句
- compute子句
- compute by 子句
聚合函数
主要聚合函数:
计数:COUNT(*)或COUNT ( [DISTINCT|ALL] <列名> )
计算总和:SUM ( [DISTINCT|ALL] <列名> )
计算平均值:AVG ( [DISTINCT|ALL] <列名> )
求最大值:MAX ( [DISTINCTHALL] <列名> )
求最小值:MIN ( [DISTINCT|ALL] <列名> )
DISTINCT短语:在计算时要取消指定列中的重复值
ALL短语:不取消重复值(ALL为缺省值)
注意:使用聚合函数时,select子句涉及显示的列名必须包含在聚合函数中
查询学生总人数(包括空值)
USE stu select count(*) from student
查询选修了课程的学生人数(用DISTINCT来避免重复计算学生人数,不包括空值)
USE stu select count(distinct sno) from sc
查询信息工程系(IS)参加“数据库”课程考试的人数、最高成绩、最低成绩、平均成绩
USE stu select count(distinct sc.sno)as '考试人数',max(cgrade) as '最高分',min(cgrade) as '最低分',avg(cgrade) as '平均分' from student inner join sc on student.sno=sc.sno inner join course on course.cno=sc.cno where cname='数据库' and sdept='IS'
SQL查询结果的排序与分组
SELECT语句除了可以检索数据以外,还可以在检索数据的过程中进行计算,甚至可以对检索的结果记录集进行排序、分组计算等操作,以达到更加复杂计算的目的。
排序的关键字:ORDER BY
分组的关键字:GROUP BY
对查询结果排序
(1)排序是指按照某个标准重新排列数据的顺序,以满足用户查看数据的顺序需求。
(2)排序所使用的标准也叫排序“关键字”或“关键码”。参与排序的关键字可以是一列,也可以是多列。且多列参与排序时,列之间不必相邻。
(3)按关键字值由小到大的顺序排列称为“升序 ( ASC)”,按关键字值由大到小的顺序排列称为“降序(DESC)”。对值相等且无法分出先后的数据按输入顺序排列。
(4)排序主要针对查询的结果集实施,对数据表一般采用索引。
使用ORDER BY子句(可以按一个或多个属性列排序,升序:ASC,降序:DESC,缺省值为ASC)
当排序列含空值时:ASC时排序列为空值的元组最后显示,DESC时排序列为空值的元组最先显示
例:查询全体学生情况,查询结果按所在系的系名升序排列,同一系中的学生按年龄降序排列。
USE stu select * from student order by sdept ASC,sage DESC
分组统计查询
作用:按照某一(几)列的属性值分别进行查询或统计。
注意:select子句涉及显示的列名必须包含在聚合函数或group by子句中。
(1)单列分组
例:根据课程分组,统计cgrade的总分与平均分
USE stu select cname as '课程名',sum(cgrade) as '总分',avg(cgrade) as '平均分' from course inner join sc on course.cno=sc.cno group by cname
(2)多列分组
首先按照第一列分组,然后按照第二列分组.......
USE stu select cname as '课程名',sdept as '系别',sum(cgrade) as '总分',avg(cgrade) as '平均分' from student inner join sc on student.sno=sc.sno inner join course on course.cno=sc.cno group by sdept,cname --注意是先按后面的排,先按cname排,再按sdept排
(3)ALL关键字
不符合where子句条件要求的记录对应字段返回空值
GROUP BY ALL 列名
(4)分组统计过滤查询(having子句)
作用:按照having子句后标明的条件显示查询的结果。
与where子句的区别: having 规定的为显示的条件,where 规定的是查询的条件。
例: 根据课程分组,统计课程名称为“非数学”的cgrade字段的总分与平均分,显示平均成绩大于90分的查询信息。
USE stu select cname as '课程名',sum(cgrade) as '总分',avg(cgrade) as '平均分' from student inner join sc on student.sno=sc.sno inner join course on course.cno=sc.cno where cname != '数学' group by cname having avg(cgrade)>=90
例: 在成绩表中查询有两门以上课程在90分以上的学生的学号及课程数,新列名为“课程数”
USE stu select sno,count(*) as '课程数' from sc where cgrade>=90 group by sno having count(*)>=2
小结:
group by语句:分组
order by语句:排序
having语句:是一个过滤声明,是在查询返回结果集以后对查询结果进行的过滤操作,在having中可以使用聚合函数。
where语句:是一个约束声明,使用where约束来自数据库的数据,where是在结果返回之前起作用的,where中不能使用聚合函数。
明细汇总查询
compute子句、但SqlServer2012不支持Compute语句(建议使用CUBE 和 ROLLUP)
GROUP BY子句有个缺点,就是返回的结果集中只有合计数据,而没有原始的详细记录。
如果想在SQL SERVER 中完成这项工作,可以使用COMPUTE BY子句。
COMPUTE生成合计作为附加的汇总列出现在结果集的最后。当与BY一起使用时,COMPUTE 子句在结果集内生成控制中断和分类汇总。
作用:明细与查询、统计结果同时显示
例:查询数据库参加考试的人员信息并按系别分组分别统计最高成绩、最低成绩、平均成绩。
USE stu select sc.sno,sc.cgrade,course.*,sdept from student inner join sc on student.sno=sc.sno inner join course on course.cno=sc.cno where cname='数据库' order by sdept compute max(cgrade),min(cgrade),avg(cgrade) by sdept
子查询
嵌套查询
所谓嵌套查询,是指一个查询语句中完整地包含另一个查询语句。外层查询称为“父查询”,内层查询称为“子查询”。子查询还可以包含子查询,SQL支持由一系列的简单查询构成的多层嵌套查询。
在SQL中,嵌套查询表现为一个查询语句完全被包含在另-个查询语句的WHERE或HAVING的条件短语中。
从语法上讲,子查询就是一个用括号括起来的特殊“条件”,它完成的是关系运算,因此,子查询可以出现在允许表达式出现的地方。
嵌套查询的执行过程是“由里到外”进行的,先执行最内层的子查询,依次由里到外执行各层的查询,即每个子查询在其上一级查询未处理之前已经完成计算,其结果用于建立父查询的查询条件。
一个SELECT-FROM-WHERE语句称为一个查询块
将一个查询块嵌套在另一个查询块的WHERE子句或HAVING短语的条件中的查询称为嵌套查询
USE stu select sname --外层查询/父查询 from student where sno=any ( select sno --内层查询/子查询 from sc where cno='2' )
子查询的限制:不能使用order by子句,order by子句只能对最终结果排序
层层嵌套方式反映了SQL语言的结构化
有些嵌套查询可以用连接运算替代
返回单值的子查询
例:查询与‘李晨’在同一个系学习的学生。
USE stu select * from student where sdept= ( select sdept from student where sname='李晨' )
例:将数据库课程的全体学生的成绩加上5分
USE stu update sc set cgrade=cgrade+5 where cno= ( select cno from course where cname='数据库' )
返回多值的子查询
(1) any谓词
例:查询年龄小于“IS”系某一学生的非“IS”系学生的基本信息
USE stu select * from student where sdept!='IS' and sage<any ( select sage from student where sdept='IS' )
例:查询学生年龄平均值不是最小的系
USE stu select sdept from student group by sdept having avg(sage)>any ( select avg(sage) from student group by sdept )
(2) all谓词
例:查询小于“IS”系学生最小年龄的学生基本信息
USE stu select * from student where sdept!='IS' and sage<all ( select sage from student where sdept='IS' ) USE stu select * from student where sage< ( select min(sage) from student where sdept='IS' )
(3) in谓词
例:查询所有年龄小于20岁的学生的成绩
USE stu select cgrade from sc where sno in ( select sno from student where sage<20 )
例:查询IS系学生的选课情况
USE stu select * from sc where sno in ( select sno from student where sdept='IS' )
例:查询没有选任何课程的学生的学号、姓名
USE stu select * from student where sno not in ( select distinct sno from sc )
例:查询没有选修计算机课程的学生的学号、姓名。
USE stu select student.sno as '学号',sname as '姓名' from student where sno not in ( select student.sno from student inner join sc on student.sno=sc.sno inner join course on course.cno=sc.cno where cname='计算机课程' )
(4) exists谓词(是否存在)
带exists的子查询不返回任何数据,只产生真或者假。
例:查询选修“数据库”课程的学生的姓名、学号、系别
USE stu select s.sno,sname,sdept from student as s where exists ( select * from sc where sc.sno = s.sno and sc.cno = ( select cno from course where cname='数据库' ) ) -- 另一种写法 USE stu select s.sno,sname,sdept from student as s where exists ( select * from sc inner join course on sc.cno=course.cno where cname='数据库' and sc.sno=s.sno ) -- 另一种写法 USE stu select sno,sname,sdept from student where sno in ( select sno from sc where cno in ( select cno from course where cname='数据库' ) )
例:从课程表中删除在选课表中没有选课记录的课程记录
USE stu delete from course where not exists ( select * from sc where course.cno=sc.cno )
几个高级查询运算词
A: UNION 运算符
UNION 运算符通过组合其他两个结果表(例如 TABLE1 和 TABLE2)并消去表中任何重复行而派生出一个结果表。当 ALL 随 UNION 一起使用时(即 UNION ALL),不消除重复行。两种情况下,派生表的每一行不是来自 TABLE1 就是来自 TABLE2。
B: EXCEPT 运算符
EXCEPT 运算符通过包括所有在 TABLE1 中但不在 TABLE2 中的行并消除所有重复行而派生出一个结果表。当 ALL 随 EXCEPT 一起使用时 (EXCEPT ALL),不消除重复行。
C: INTERSECT 运算符
INTERSECT 运算符通过只包括 TABLE1 和 TABLE2 中都有的行并消除所有重复行而派生出一个结果表。当 ALL 随 INTERSECT 一起使用时 (INTERSECT ALL),不消除重复行。
注:使用运算词的几个查询结果行必须是一致的。