一、注意点
1、将一个已经存在数据的表转换为分区表,要先看看这个表是否有聚合索引(主键),有的话要删除掉.
2、这个就是通过给表添加聚集索引(使用分区架构的索引)来使表达到分区的效果。
3、可以不需要那么多文件组和文件,分区架构里可以使用同一个文件组[PRIMARY]。
4、做分区的列可以有重复数据,只是把重复的数据放到同一个分区而已。
5、做了分区的表也可以直接删除。
6、分区方案和分区函数的位置
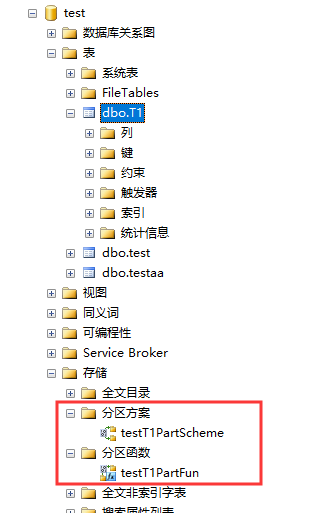
7、分区表依赖分区架构,分区架构依赖分区函数。
二、操作步骤
--1.创建分区函数
create partition function testT1PartFun(int)
as range right
for values(10000,20000,30000,40000,50000,60000,70000,80000,90000,100000)
--2.创建分区方案
create partition scheme testT1PartScheme
as partition testT1PartFun
to ([PRIMARY],[PRIMARY],[PRIMARY],[PRIMARY],[PRIMARY],[PRIMARY],[PRIMARY],[PRIMARY],[PRIMARY],[PRIMARY],[PRIMARY])
--3.创建使用分区方案的的聚集索引
create clustered index ix_col1 on T1 (Col1) on testT1PartScheme(Col1)
--4.查看指定物理分区上的数据
select * from test.dbo.T1 where $partition.testT1PartFun(Col1) =3
--5.查看每个物理分区上的数据
select $partition.testT1PartFun(Col1) as partitionNum,count(*) as cnt from test.dbo.T1
group by $partition.testT1PartFun(Col1)
--6.查看所有的分区id和使用的文件组的id
select * from sys.destination_data_spaces
--7.查看所有的文件组
select * from sys.filegroups