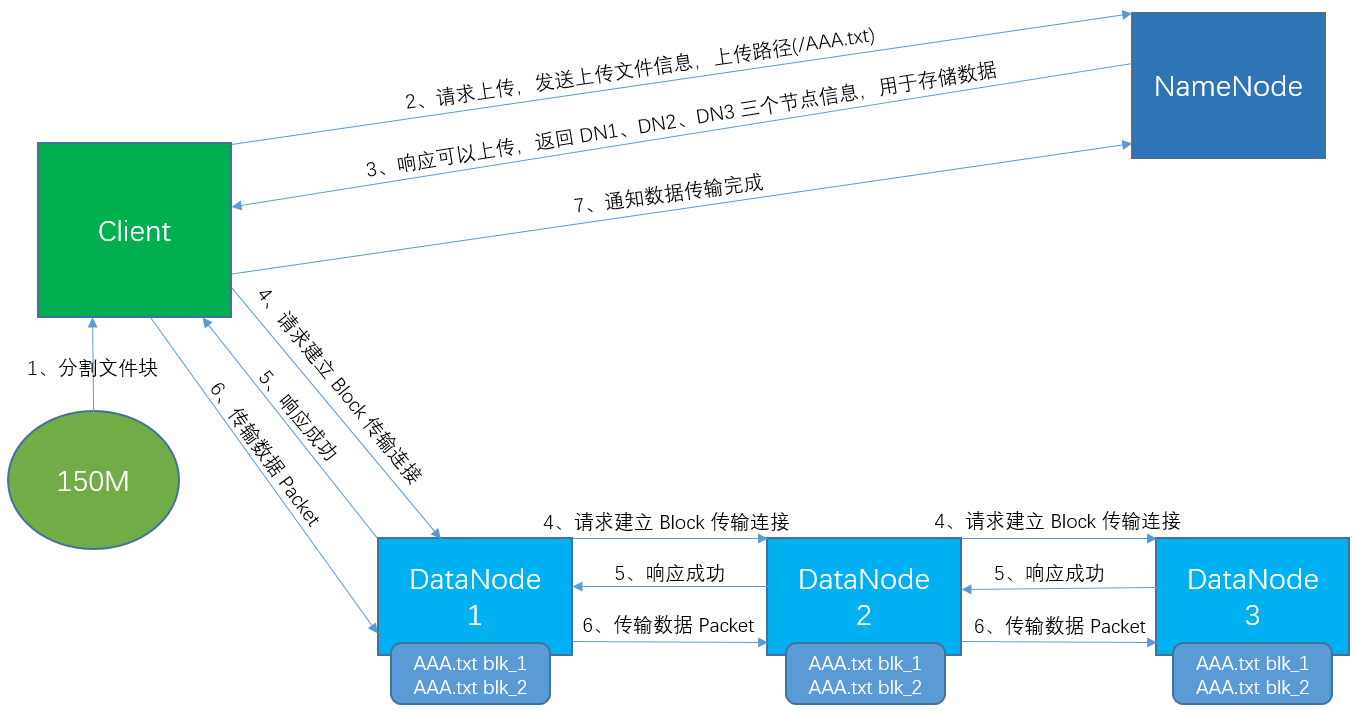
一、上传数据
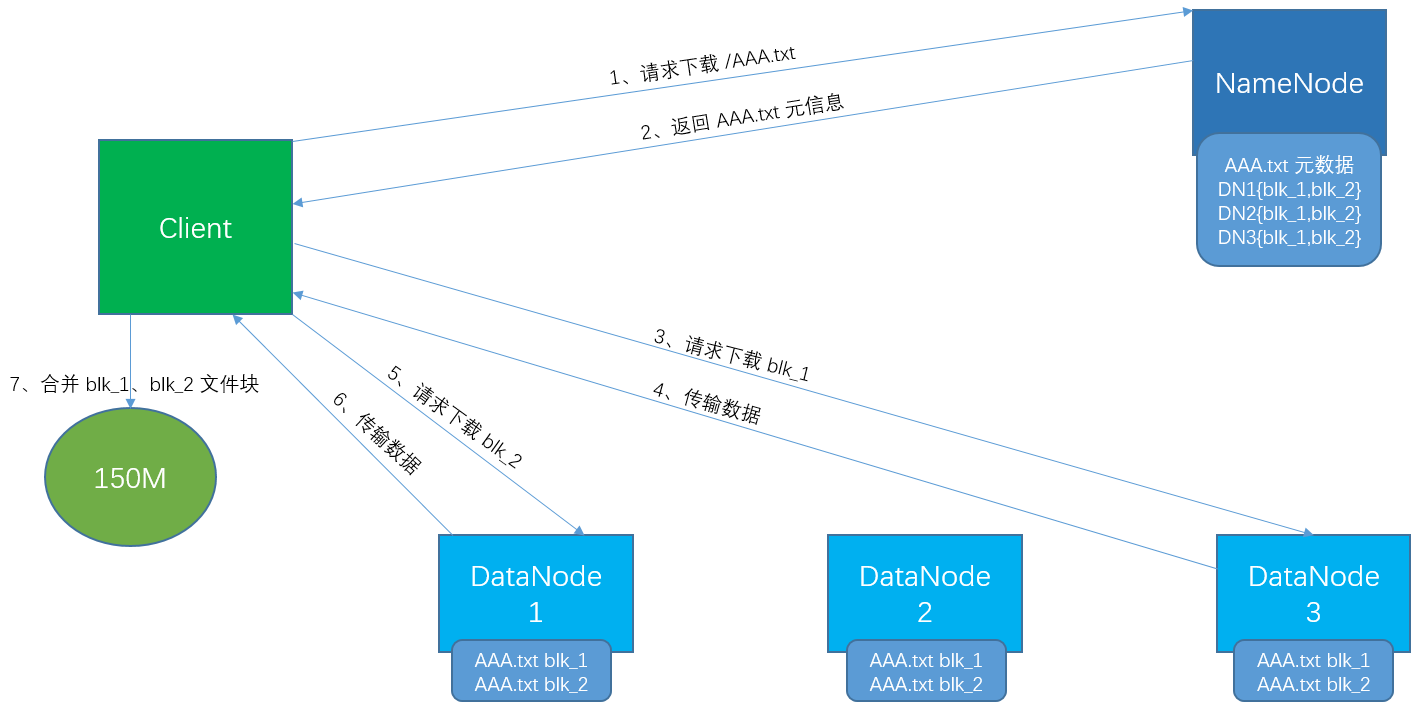
二、下载数据
三、读写时的节点位置选择
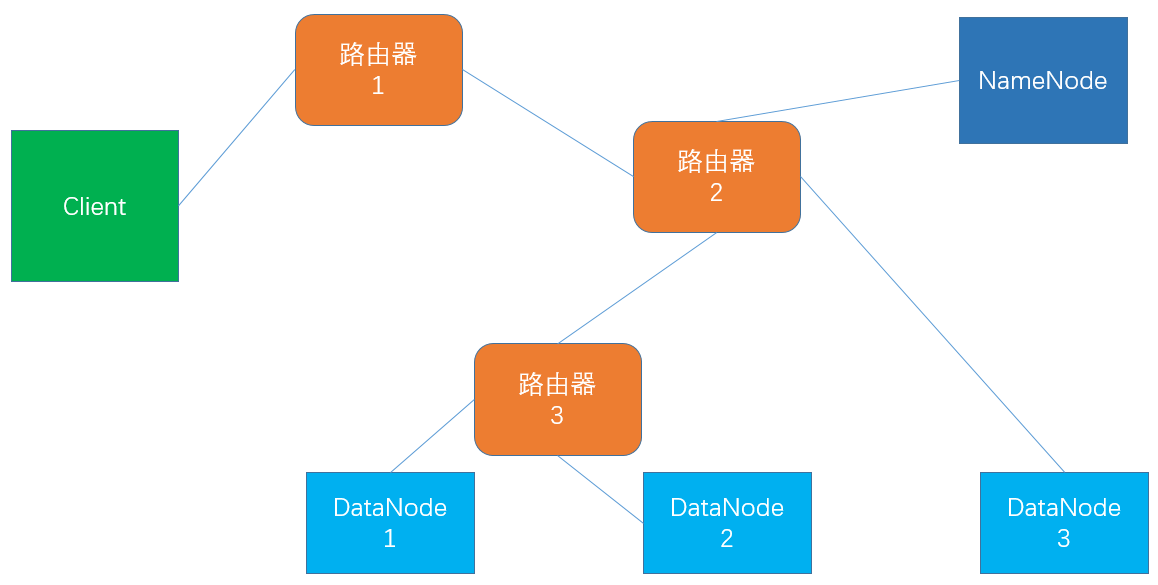
1.网络节点距离(机架感知)
下图中: client 到 DN1 的距离为 4 client 到 NN 的距离为 3 DN1 到 DN2 的距离为 2
2.Block 的副本放置策略
NameNode 通过 Hadoop Rack Awareness 确定每个 DataNode 所属的机架 ID
简单但非最优的策略
将副本放在单独的机架上 这可以防止在整个机架出现故障时丢失数据,并允许在读取数据时使用来自多个机架的带宽。 此策略在群集中均匀分布副本,平衡组件故障的负载。 但是此策略会增加写入消耗,因为写入时会将块传输到多个机架。
常见情况策略(HDFS 采取的策略)
当复制因子为 3 时,HDFS 的放置策略是: 若客户端位于 datanode 上,则将一个副本放在本地计算机上,否则放在随机 datanode 上 在另一个(远程)机架上的节点上放置另一个副本,最后一个在同一个远程机架中的另一个节点上。 机架故障的可能性远小于节点故障的可能性。 此策略可以减少机架间写入流量,从而提高写入性能,而不会影响数据可靠性和可用性(读取性能)。 这样减少了读取数据时使用的聚合网络带宽,因为块只放在两个唯一的机架,而不是三个。
如果复制因子大于 3,则随机确定第 4 个及后续副本的放置,同时保持每个机架的副本数量低于上限(基本上是(副本 - 1)/机架+ 2)。
由于 NameNode 不允许 DataNode 具有同一块的多个副本,因此创建的最大副本数是此时DataNode的总数。
原文(Replica Placement: The First Baby Steps 章节): http://hadoop.apache.org/docs/current/hadoop-project-dist/hadoop-hdfs/HdfsDesign.html
3.下载时副本的选择
为了最大限度地减少全局带宽消耗和读取延迟,HDFS 会选择最接客户端的节点中的副本来响应读取请求。 如果客户端与 DataNode 节点在同一机架上,且存在所需的副本,则该副本会首读用来响应取请求。 如果 HDFS 群集跨越多个数据中心,则驻留在本地数据中心的副本优先于任何远程副本。
原文(Replica Selection 章节): http://hadoop.apache.org/docs/current/hadoop-project-dist/hadoop-hdfs/HdfsDesign.html