实现步骤
第一步:创建一个Directory对象,也就是索引库存放的位置。
第二步:创建一个indexReader对象,需要指定Directory对象。
第三步:创建一个indexsearcher对象,需要指定IndexReader对象
第四步:创建一个TermQuery对象,指定查询的域和查询的关键词。
第五步:执行查询。
第六步:返回查询结果。遍历查询结果并输出。
第七步:关闭IndexReader对象
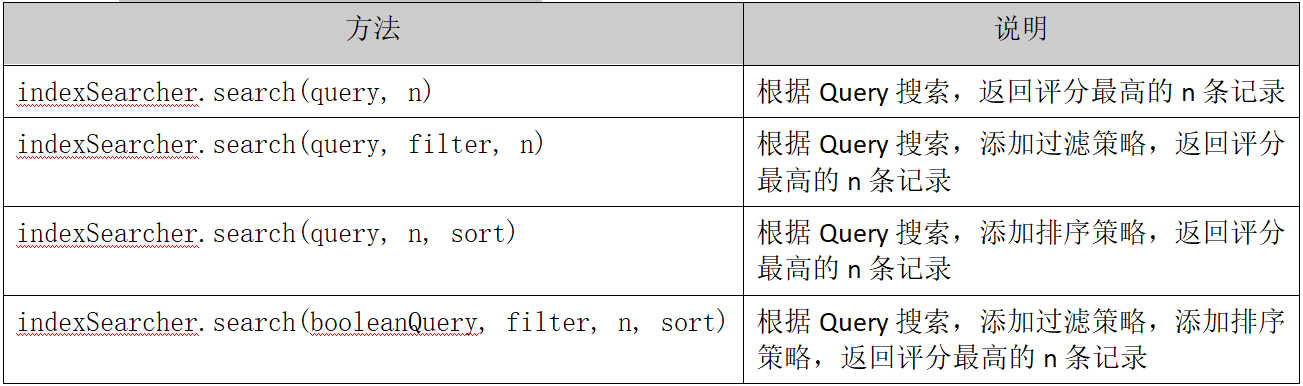
IndexSearcher搜索方法
代码实现
package com.test.lucene.helloworld; import java.io.File; import org.apache.lucene.document.Document; import org.apache.lucene.index.DirectoryReader; import org.apache.lucene.index.IndexReader; import org.apache.lucene.index.Term; import org.apache.lucene.search.IndexSearcher; import org.apache.lucene.search.Query; import org.apache.lucene.search.ScoreDoc; import org.apache.lucene.search.TermQuery; import org.apache.lucene.search.TopDocs; import org.apache.lucene.store.Directory; import org.apache.lucene.store.FSDirectory; import org.junit.Test; public class LuceneTestQueryIndex { // 查询索引 @Test public void queryIndex() throws Exception { // 创建一个Directory对象,也就是索引库存放的位置。 Directory directory = FSDirectory.open(new File("E:\study\test\index")); // 创建一个indexReader对象,需要指定Directory对象。 IndexReader indexReader = DirectoryReader.open(directory); // 创建indexsearcher对象 IndexSearcher indexSearcher = new IndexSearcher(indexReader); // 创建查询 Query query = new TermQuery(new Term("filename", "apache")); // 执行查询 // 第一个参数是查询对象,第二个参数是查询结果返回的最大值 TopDocs topDocs = indexSearcher.search(query, 10); // 查询结果的总条数 System.out.println("查询结果的总条数:" + topDocs.totalHits); // 遍历查询结果 // topDocs.scoreDocs存储了document对象的id for (ScoreDoc scoreDoc : topDocs.scoreDocs) { // scoreDoc.doc属性就是document对象的id // 根据document的id找到document对象 Document document = indexSearcher.doc(scoreDoc.doc); System.out.println("filename:"+document.get("filename")); System.out.println("content: "+document.get("content")); System.out.println("path:"+document.get("path")); System.out.println("size:"+document.get("size")); System.out.println("-----------------------------------"); } // 第七步:关闭IndexReader对象 indexReader.close(); } }
Topdocs
Lucene搜索结果可通过TopDocs遍历,TopDocs类提供了少量的属性,如下:
|
方法或属性 |
说明 |
|
totalHits |
匹配搜索条件的总记录数 |
|
scoreDocs |
顶部匹配记录 |
注意:
Search方法需要指定匹配记录数量n:indexSearcher.search(query, n)
TopDocs.totalHits:是匹配索引库中所有记录的数量
TopDocs.scoreDocs:匹配相关度高的前边记录数组,scoreDocs的长度小于等于search方法指定的参数n