自JDK 1.5 开始,JDK提供了ScheduledThreadPoolExecutor类用于计划任务(又称定时任务),这个类有两个用途:
-
-
在给定的延迟之后运行任务
-
周期性重复执行任务
-
在这之前,是使用Timer类来完成定时任务的,但是Timer有缺陷:
-
-
Timer是单线程模式;
-
如果在执行任务期间某个TimerTask耗时较久,那么就会影响其它任务的调度;
-
Timer的任务调度是基于绝对时间的,对系统时间敏感;
-
Timer不会捕获执行TimerTask时所抛出的异常,由于Timer是单线程,所以一旦出现异常,则线程就会终止,其他任务也得不到执行。
-
所以JDK 1.5之后,大家就摒弃Timer,使用ScheduledThreadPoolExecutor吧。
一、使用案例
假设我有一个需求,指定时间给大家发送消息。那么我们会将消息(包含发送时间)存储在数据库中,然后想用一个定时任务,每隔1秒检查数据库在当前时间有没有需要发送的消息,那这个计划任务怎么写?下面是一个Demo:
public class ThreadPool { private static final ScheduledExecutorService executor = new ScheduledThreadPoolExecutor(1, Executors.defaultThreadFactory()); private static SimpleDateFormat df = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss"); public static void main(String[] args){ // 新建一个固定延迟时间的计划任务 executor.scheduleWithFixedDelay(new Runnable() { @Override public void run() { if (haveMsgAtCurrentTime()) { System.out.println(df.format(new Date())); System.out.println("大家注意了,我要发消息了"); } } }, 1, 1, TimeUnit.SECONDS); } public static boolean haveMsgAtCurrentTime(){ //查询数据库,有没有当前时间需要发送的消息 //这里省略实现,直接返回true return true; } }
下面截取前面的输出(这个demo会一直运行下去):
2019-01-23 16:16:48 大家注意了,我要发消息了 2019-01-23 16:16:49 大家注意了,我要发消息了 2019-01-23 16:16:50 大家注意了,我要发消息了 2019-01-23 16:16:51 大家注意了,我要发消息了 2019-01-23 16:16:52 大家注意了,我要发消息了 2019-01-23 16:16:53 大家注意了,我要发消息了 2019-01-23 16:16:54 大家注意了,我要发消息了 2019-01-23 16:16:55 大家注意了,我要发消息了
这就是ScheduledThreadPoolExecutor的一个简单运用,想要知道奥秘,接下来的东西需要仔细的看哦。
二、类结构
public class ScheduledThreadPoolExecutor extends ThreadPoolExecutor implements ScheduledExecutorService { public ScheduledThreadPoolExecutor(int corePoolSize,ThreadFactory threadFactory) { super(corePoolSize, Integer.MAX_VALUE, 0, NANOSECONDS, new DelayedWorkQueue(), threadFactory); } //…… }
ScheduledThreadPoolExecutor继承了ThreadPoolExecutor,实现了ScheduledExecutorService。 线程池在之前的章节介绍过了,我们先看看ScheduledExecutorService。
public interface ScheduledExecutorService extends ExecutorService { public ScheduledFuture<?> schedule(Runnable command,long delay, TimeUnit unit); public <V> ScheduledFuture<V> schedule(Callable<V> callable,long delay, TimeUnit unit); public ScheduledFuture<?> scheduleAtFixedRate(Runnable command, long initialDelay, long period, TimeUnit unit); public ScheduledFuture<?> scheduleWithFixedDelay(Runnable command, long initialDelay, long delay, TimeUnit unit); }
ScheduledExecutorService实现了ExecutorService ,并增加若干定时相关的接口。 前两个方法用于单次调度执行任务,区别是有没有返回值。
重点理解一下后面两个方法:
-
该方法在
initialDelay时长后第一次执行任务,以后每隔period时长,再次执行任务。注意,period是从任务开始执行算起的。开始执行任务后,定时器每隔period时长检查该任务是否完成,如果完成则再次启动任务,否则等该任务结束后才再次启动任务。 -
scheduleWithFixDelay
该方法在
initialDelay时长后第一次执行任务,以后每当任务执行完成后,等待delay
// delay时长后执行任务command,该任务只执行一次 public ScheduledFuture<?> schedule(Runnable command, long delay, TimeUnit unit) { if (command == null || unit == null) throw new NullPointerException(); // 这里的decorateTask方法仅仅返回第二个参数 RunnableScheduledFuture<?> t = decorateTask(command, new ScheduledFutureTask<Void>(command, null, triggerTime(delay,unit))); // 延时或者周期执行任务的主要方法,稍后统一说明 delayedExecute(t); return t; }
我们先看看里面涉及到的几个类和接口ScheduledFuture、 RunnableScheduledFuture、 ScheduledFutureTask的关系:
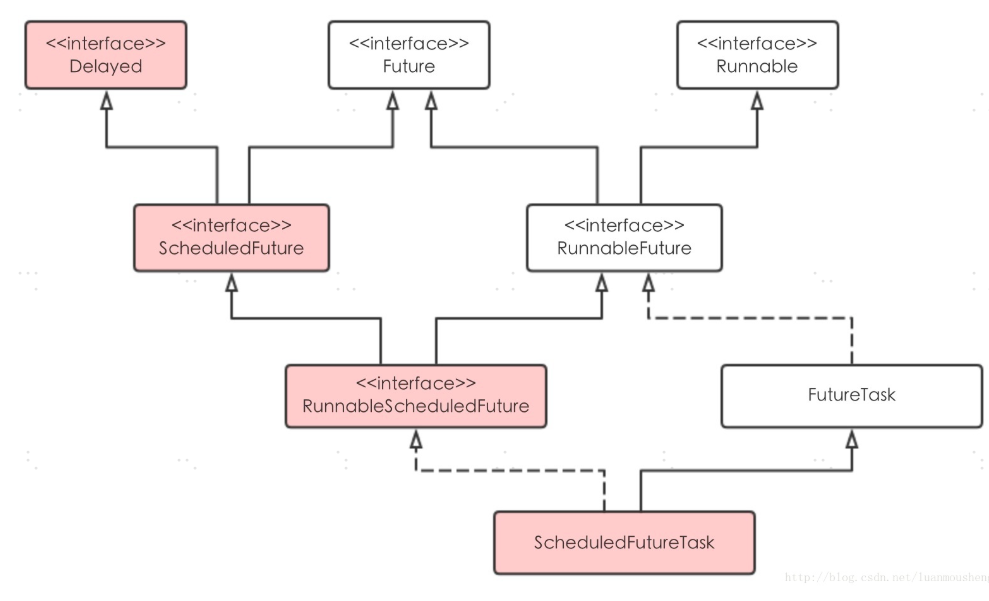
我们先看看这几个接口和类:
- Delayed接口
// 继承Comparable接口,表示该类对象支持排序 public interface Delayed extends Comparable<Delayed> { // 返回该对象剩余时延 long getDelay(TimeUnit unit); }
// 仅仅继承了Delayed和Future接口,自己没有任何代码 public interface ScheduledFuture<V> extends Delayed, Future<V> { }
没有添加其他方法。
- RunnableScheduledFuture接口
public interface RunnableScheduledFuture<V> extends RunnableFuture<V>, ScheduledFuture<V> { // 是否是周期任务,周期任务可被调度运行多次,非周期任务只被运行一次 boolean isPeriodic(); }
- ScheduledFutureTask类
回到schecule方法中,它创建了一个ScheduledFutureTask的对象,由上面的关系图可知,ScheduledFutureTask直接或者间接实现了很多接口,一起看看ScheduledFutureTask里面的实现方法吧。
构造方法
ScheduledFutureTask(Runnable r, V result, long ns, long period) { // 调用父类FutureTask的构造方法 super(r, result); // time表示任务下次执行的时间 this.time = ns; // 周期任务,正数表示按照固定速率,负数表示按照固定时延,0表示不是周期任务 this.period = period; // 任务的编号 this.sequenceNumber = sequencer.getAndIncrement(); }
Delayed接口的实现
// 实现Delayed接口的getDelay方法,返回任务开始执行的剩余时间 public long getDelay(TimeUnit unit) { return unit.convert(time - now(), TimeUnit.NANOSECONDS); }
Comparable接口的实现
// Comparable接口的compareTo方法,比较两个任务的”大小”。 public int compareTo(Delayed other) { if (other == this) return 0; if (other instanceof ScheduledFutureTask) { ScheduledFutureTask<?> x = (ScheduledFutureTask<?>)other; long diff = time - x.time; // 小于0,说明当前任务的执行时间点早于other,要排在延时队列other的前面 if (diff < 0) return -1; // 大于0,说明当前任务的执行时间点晚于other,要排在延时队列other的后面 else if (diff > 0) return 1; // 如果两个任务的执行时间点一样,比较两个任务的编号,编号小的排在队列前面,编号大的排在队列后面 else if (sequenceNumber < x.sequenceNumber) return -1; else return 1; } // 如果任务类型不是ScheduledFutureTask,通过getDelay方法比较 long d = (getDelay(TimeUnit.NANOSECONDS) - other.getDelay(TimeUnit.NANOSECONDS)); return (d == 0) ? 0 : ((d < 0) ? -1 : 1); }
setNextRunTime
// 任务执行完后,设置下次执行的时间 private void setNextRunTime() { long p = period; // p > 0,说明是固定速率运行的任务 // 在原来任务开始执行时间的基础上加上p即可 if (p > 0) time += p; // p < 0,说明是固定时延运行的任务, // 下次执行时间在当前时间(任务执行完成的时间)的基础上加上-p的时间 else time = triggerTime(-p); }
Runnable接口实现
public void run() { boolean periodic = isPeriodic(); // 如果当前状态下不能执行任务,则取消任务 if (!canRunInCurrentRunState(periodic)) cancel(false); // 不是周期性任务,执行一次任务即可,调用父类的run方法 else if (!periodic) ScheduledFutureTask.super.run(); // 是周期性任务,调用FutureTask的runAndReset方法,方法执行完成后 // 重新设置任务下一次执行的时间,并将该任务重新入队,等待再次被调度 else if (ScheduledFutureTask.super.runAndReset()) { setNextRunTime(); reExecutePeriodic(outerTask); } }
总结一下run方法的执行过程:
-
如果当前线程池运行状态不可以执行任务,取消该任务,然后直接返回,否则执行步骤2;
-
如果不是周期性任务,调用FutureTask中的run方法执行,会设置执行结果,然后直接返回,否则执行步骤3;
-
如果是周期性任务,调用FutureTask中的runAndReset方法执行,不会设置执行结果,然后直接返回,否则执行步骤4和步骤5;
-
计算下次执行该任务的具体时间;
-
重复执行任务。
-
runAndReset方法是为任务多次执行而设计的。runAndReset方法执行完任务后不会设置任务的执行结果,也不会去更新任务的状态,维持任务的状态为初始状态(NEW状态),这也是该方法和FutureTask的run方法的区别。
// 注意,固定速率和固定时延,传入的参数都是Runnable,也就是说这种定时任务是没有返回值的 public ScheduledFuture<?> scheduleAtFixedRate(Runnable command, long initialDelay, long period, TimeUnit unit) { if (command == null || unit == null) throw new NullPointerException(); if (period <= 0) throw new IllegalArgumentException(); // 创建一个有初始延时和固定周期的任务 ScheduledFutureTask<Void> sft = new ScheduledFutureTask<Void>(command, null, triggerTime(initialDelay, unit), unit.toNanos(period)); RunnableScheduledFuture<Void> t = decorateTask(command, sft); // outerTask表示将会重新入队的任务 sft.outerTask = t; // 稍后说明 delayedExecute(t); return t; }
scheduleAtFixedRate这个方法和schedule类似,不同点是scheduleAtFixedRate方法内部创建的是ScheduledFutureTask,带有初始延时和固定周期的任务 。
3.3 scheduledAtFixedDelay
FixedDelay也是通过ScheduledFutureTask体现的,唯一不同的地方在于创建的ScheduledFutureTask不同 。这里不再展示源码。
3.4 delayedExecute
前面讲到的schedule、scheduleAtFixedRate和scheduleAtFixedDelay最后都调用了delayedExecute方法,该方法是定时任务执行的主要方法。 一起来看看源码:
private void delayedExecute(RunnableScheduledFuture<?> task) { // 线程池已经关闭,调用拒绝执行处理器处理 if (isShutdown()) reject(task); else { // 将任务加入到等待队列 super.getQueue().add(task); // 线程池已经关闭,且当前状态不能运行该任务,将该任务从等待队列移除并取消该任务 if (isShutdown() && !canRunInCurrentRunState(task.isPeriodic()) && remove(task)) task.cancel(false); else // 增加一个worker,就算corePoolSize=0也要增加一个worker ensurePrestart(); } }
delayedExecute方法的逻辑也很简单,主要就是将任务添加到等待队列,然后调用ensurePrestart方法。
void ensurePrestart() { int wc = workerCountOf(ctl.get()); if (wc < corePoolSize) addWorker(null, true); else if (wc == 0) addWorker(null, false); }
ensurePrestart方法主要是调用了addWorker,线程池中的工作线程是通过该方法来启动并执行任务的。 具体可以查看前面讲的线程池章节。
对于ScheduledThreadPoolExecutor,worker添加到线程池后会在等待队列上等待获取任务,这点是和ThreadPoolExecutor一致的。但是worker是怎么从等待队列取定时任务的?
因为ScheduledThreadPoolExecutor使用了DelayedWorkQueue保存等待的任务,该等待队列队首应该保存的是最近将要执行的任务,如果队首任务的开始执行时间还未到,worker也应该继续等待。
四、DelayedWorkQueue
该等待队列队首应该保存的是最近将要执行的任务,所以worker只关心队首任务即可,如果队首任务的开始执行时间还未到,worker也应该继续等待。
DelayedWorkQueue是一个无界优先队列,使用数组存储,底层是使用堆结构来实现优先队列的功能。我们先看看DelayedWorkQueue的声明和成员变量:
static class DelayedWorkQueue extends AbstractQueue<Runnable> implements BlockingQueue<Runnable> { // 队列初始容量 private static final int INITIAL_CAPACITY = 16; // 数组用来存储定时任务,通过数组实现堆排序 private RunnableScheduledFuture[] queue = new RunnableScheduledFuture[INITIAL_CAPACITY]; // 当前在队首等待的线程 private Thread leader = null; // 锁和监视器,用于leader线程 private final ReentrantLock lock = new ReentrantLock(); private final Condition available = lock.newCondition(); // 其他代码,略 }
当一个线程成为leader,它只要等待队首任务的delay时间即可,其他线程会无条件等待。leader取到任务返回前要通知其他线程,直到有线程成为新的leader。每当队首的定时任务被其他更早需要执行的任务替换时,leader设置为null,其他等待的线程(被当前leader通知)和当前的leader重新竞争成为leader。
同时,定义了锁lock和监视器available用于线程竞争成为leader。
当一个新的任务成为队首,或者需要有新的线程成为leader时,available监视器上的线程将会被通知,然后竞争称为leader线程。 有些类似于生产者-消费者模式。
接下来看看DelayedWorkQueue中几个比较重要的方法
public RunnableScheduledFuture take() throws InterruptedException { final ReentrantLock lock = this.lock; lock.lockInterruptibly(); try { for (;;) { // 取堆顶的任务,堆顶是最近要执行的任务 RunnableScheduledFuture first = queue[0]; // 堆顶为空,线程要在条件available上等待 if (first == null) available.await(); else { // 堆顶任务还要多长时间才能执行 long delay = first.getDelay(TimeUnit.NANOSECONDS); // 堆顶任务已经可以执行了,finishPoll会重新调整堆,使其满足最小堆特性,该方法设置任务在 // 堆中的index为-1并返回该任务 if (delay <= 0) return finishPoll(first); // 如果leader不为空,说明已经有线程成为leader并等待堆顶任务 // 到达执行时间,此时,其他线程都需要在available条件上等待 else if (leader != null) available.await(); else { // leader为空,当前线程成为新的leader Thread thisThread = Thread.currentThread(); leader = thisThread; try { // 当前线程已经成为leader了,只需要等待堆顶任务到达执行时间即可 available.awaitNanos(delay); } finally { // 返回堆顶元素之前将leader设置为空 if (leader == thisThread) leader = null; } } } } } finally { // 通知其他在available条件等待的线程,这些线程可以去竞争成为新的leader if (leader == null && queue[0] != null) available.signal(); lock.unlock(); } }
take方法是什么时候调用的呢?在线程池的章节中,介绍了getTask方法,工作线程会循环地从workQueue中取任务。但计划任务却不同,因为如果一旦getTask方法取出了任务就开始执行了,而这时可能还没有到执行的时间,所以在take方法中,要保证只有在到指定的执行时间的时候任务才可以被取走。
总结一下流程:
-
如果堆顶元素为空,在available条件上等待。
-
如果堆顶任务的执行时间已到,将堆顶元素替换为堆的最后一个元素并调整堆使其满足最小堆特性,同时设置任务在堆中索引为-1,返回该任务。
-
如果leader不为空,说明已经有线程成为leader了,其他线程都要在available监视器上等待。
-
如果leader为空,当前线程成为新的leader,并等待直到堆顶任务执行时间到达。
-
take方法返回之前,将leader设置为空,并通知其他线程。
-
再来说一下leader的作用,这里的leader是为了减少不必要的定时等待,当一个线程成为leader时,它只等待下一个节点的时间间隔,但其它线程无限期等待。 leader线程必须在从take()或poll()返回之前signal其它线程,除非其他线程成为了leader。
举例来说,如果没有leader,那么在执行take时,都要执行available.awaitNanos(delay),假设当前线程执行了该段代码,这时还没有signal,第二个线程也执行了该段代码,则第二个线程也要被阻塞。但只有一个线程返回队首任务,其他的线程在awaitNanos(delay)之后,继续执行for循环,因为队首任务已经被返回了,所以这个时候的for循环拿到的队首任务是新的,又需要重新判断时间,又要继续阻塞。
所以,为了不让多个线程频繁的做无用的定时等待,这里增加了leader,如果leader不为空,则说明队列中第一个节点已经在等待出队,这时其它的线程会一直阻塞,减少了无用的阻塞(注意,在finally中调用了signal()来唤醒一个线程,而不是signalAll())。
4.2 offer
该方法往队列插入一个值,返回是否成功插入 。
public boolean offer(Runnable x) { if (x == null) throw new NullPointerException(); RunnableScheduledFuture e = (RunnableScheduledFuture)x; final ReentrantLock lock = this.lock; lock.lock(); try { int i = size; // 队列元素已经大于等于数组的长度,需要扩容,新堆的容量是原来堆容量的1.5倍 if (i >= queue.length) grow(); // 堆中元素增加1 size = i + 1; // 调整堆 if (i == 0) { queue[0] = e; setIndex(e, 0); } else { // 调整堆,使的满足最小堆,比较大小的方式就是上文提到的compareTo方法 siftUp(i, e); } if (queue[0] == e) { leader = null; // 通知其他在available条件上等待的线程,这些线程可以竞争成为新的leader available.signal(); } } finally { lock.unlock(); } return true; }
在堆中插入了一个节点,这个时候堆有可能不满足最小堆的定义,siftUp用于将堆调整为最小堆,这属于数据结构的基本内容,本文不做介绍。
五、总结
内部使用优化的DelayQueue来实现,由于使用队列来实现定时器,有出入队调整堆等操作,所以定时并不是非常非常精确。
参考资料