高可用架构
大型网站应该在任何时候都可以正常访问。正常提供对外服务。因为大型网站的复杂性,分布式,廉价服务器,开源数据库,操作系统等特点。要保证高可用是很困难的,也就是说网站的故障是不可避免的。
如何提高可用性,就是需要迫切解决的问题。首先,需要从架构级别,在规划的时候,就考虑可用性。行业内一般用几个9表示可用性指标。比如四个9(99.99),一年内允许的不可用时间是53分钟。
不同层级使用的策略不同,一般采用冗余备份和失效转移解决高可用问题。
应用层:一般设计为无状态的,对于每次请求,使用哪一台服务器处理是没有影响的。一般使用负载均衡技术(需要解决Session同步问题),实现高可用。
服务层:负载均衡,分级管理,快速失败(超时设置),异步调用,服务降级,幂等设计等。
数据层:冗余备份(冷,热备[同步,异步],温备),失效转移(确认,转移,恢复)。数据高可用方面著名的理论基础是CAP理论(持久性,可用性,数据一致性[强一致,用户一致,最终一致])
可伸缩架构
伸缩性是指在不改变原有架构设计的基础上,通过添加/减少硬件(服务器)的方式,提高/降低系统的处理能力。
应用层:对应用进行垂直或水平切分。然后针对单一功能进行负载均衡(DNS,HTTP[反向代理],IP,链路层)。
服务层:与应用层类似;
数据层:分库,分表,NOSQL等;常用算法Hash,一致性Hash。
可扩展架构
可以方便的进行功能模块的新增/移除,提供代码/模块级别良好的可扩展性。
模块化,组件化:高内聚,内耦合,提高复用性,扩展性。
稳定接口:定义稳定的接口,在接口不变的情况下,内部结构可以“随意”变化。
设计模式:应用面向对象思想,原则,使用设计模式,进行代码层面的设计。
消息队列:模块化的系统,通过消息队列进行交互,使模块之间的依赖解耦。
分布式服务:公用模块服务化,提供其他系统使用,提高可重用性,扩展性。
安全架构
对已知问题有有效的解决方案,对未知/潜在问题建立发现和防御机制。对于安全问题,首先要提高安全意识,建立一个安全的有效机制,从政策层面,组织层面进行保障。比如服务器密码不能泄露,密码每月更新,并且三次内不能重复;每周安全扫描等。以制度化的方式,加强安全体系的建设。同时,需要注意与安全有关的各个环节。安全问题不容忽视。包括基础设施安全,应用系统安全,数据保密安全等。
基础设施安全:硬件采购,操作系统,网络环境方面的安全。一般采用,正规渠道购买高质量的产品,选择安全的操作系统,及时修补漏洞,安装杀毒软件防火墙。防范病毒,后门。设置防火墙策略,建立DDOS防御系统,使用攻击检测系统,进行 子网隔离等手段。
应用系统安全:在程序开发时,对已知常用问题,使用正确的方式,在代码层面解决掉。防止跨站脚本攻击(XSS),注入攻击,跨站请求伪造(CSRF),错误信息,HTML注释,文件上传,路径遍历等。还可以使用Web应用防火墙(比如:ModSecurity),进行安全漏洞扫描等措施,加强应用级别的安全。
数据保密安全:存储安全(存在在可靠的设备,实时,定时备份),保存安全(重要的信息加密保存,选择合适的人员复杂保存和检测等),传输安全(防止数据窃取和数据篡改);
常用的加解密算法(单项散列加密[MD5,SHA],对称加密[DES,3DES,RC]),非对称加密[RSA]等。
敏捷性
网站的架构设计,运维管理要适应变化,提供高伸缩性,高扩展性。方便的应对快速的业务发展,突增高流量访问等要求。
除上面介绍的架构要素外,还需要引入敏捷管理,敏捷开发的思想。使业务,产品,技术,运维统一起来,随需应变,快速响应。
大型架构举例
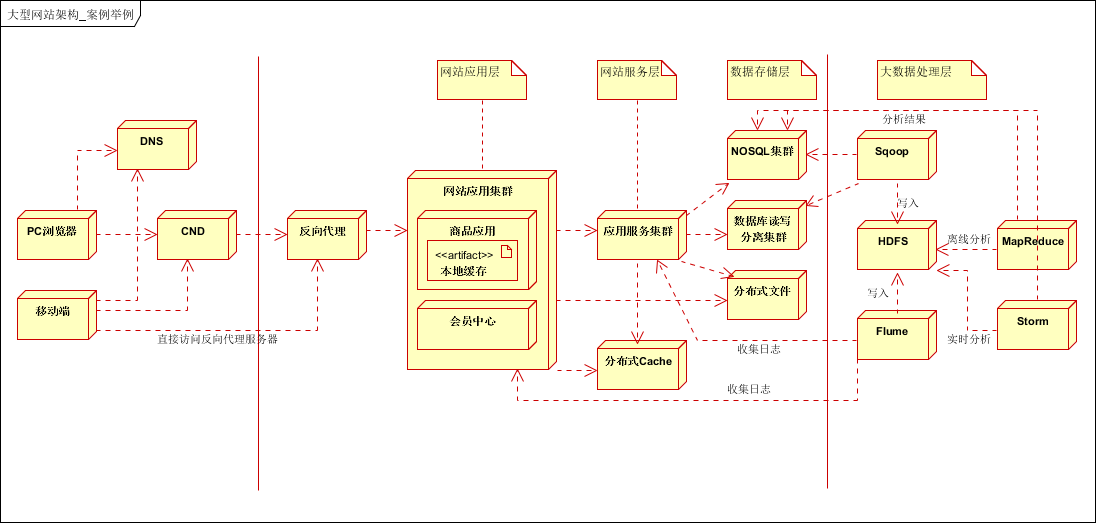
以上采用七层逻辑架构,第一层客户层,第二层前端优化层,第三层应用层,第四层服务层,第五层数据存储层,第六层大数据存储层,第七层大数据处理层。
客户层:支持PC浏览器和手机APP。差别是手机APP可以直接访问通过IP访问,反向代理服务器。
前端层:使用DNS负载均衡,CDN本地加速以及反向代理服务;
应用层:网站应用集群;按照业务进行垂直拆分,比如商品应用,会员中心等;
服务层:提供公用服务,比如用户服务,订单服务,支付服务等;
数据层:支持关系型数据库集群(支持读写分离),NOSQL集群,分布式文件系统集群;以及分布式Cache;
大数据存储层:支持应用层和服务层的日志数据收集,关系数据库和NOSQL数据库的结构化和半结构化数据收集;
大数据处理层:通过Mapreduce进行离线数据分析或Storm实时数据分析,并将处理后的数据存入关系型数据库。(实际使用中,离线数据和实时数据会按照业务要求进行分类处理,并存入不同的数据库中,供应用层或服务层使用)。