摘自:http://python.jobbole.com/87805/
原文出处: liuzhijun
本文源自RQ作者的一篇博文,原文是Iterables vs. Iterators vs. Generators,俺写的这篇文章是按照自己的理解做的参考翻译,算不上是原文的中译版本,推荐阅读原文,谢谢网友指正。
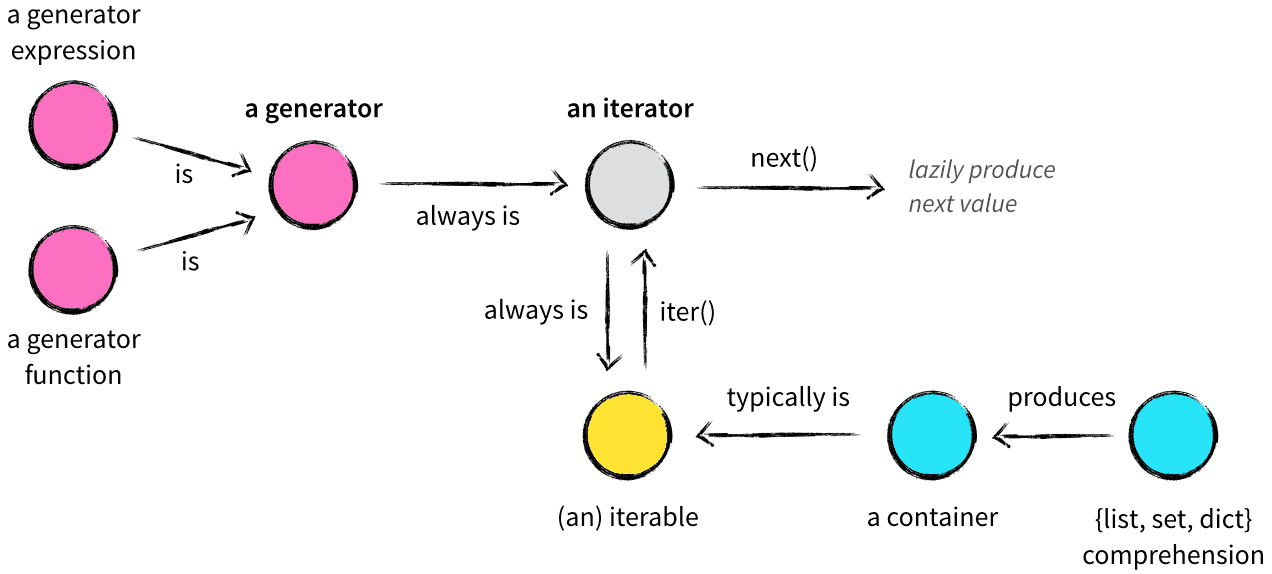
在了解Python的数据结构时,容器(container)、可迭代对象(iterable)、迭代器(iterator)、生成器(generator)、列表/集合/字典推导式(list,set,dict comprehension)众多概念参杂在一起,难免让初学者一头雾水,我将用一篇文章试图将这些概念以及它们之间的关系捋清楚。
容器(container)
容器是一种把多个元素组织在一起的数据结构,容器中的元素可以逐个地迭代获取,可以用in, not in关键字判断元素是否包含在容器中。通常这类数据结构把所有的元素存储在内存中(也有一些特例,并不是所有的元素都放在内存,比如迭代器和生成器对象)在Python中,常见的容器对象有:
- list, deque, ….
- set, frozensets, ….
- dict, defaultdict, OrderedDict, Counter, ….
- tuple, namedtuple, …
- str
容器比较容易理解,因为你就可以把它看作是一个盒子、一栋房子、一个柜子,里面可以塞任何东西。从技术角度来说,当它可以用来询问某个元素是否包含在其中时,那么这个对象就可以认为是一个容器,比如 list,set,tuples都是容器对象:
>>> assert 1 in [1, 2, 3] # lists >>> assert 4 not in [1, 2, 3] >>> assert 1 in {1, 2, 3} # sets >>> assert 4 not in {1, 2, 3} >>> assert 1 in (1, 2, 3) # tuples >>> assert 4 not in (1, 2, 3)
询问某元素是否在dict中用dict的中key:
>>> d = {1: 'foo', 2: 'bar', 3: 'qux'}
>>> assert 1 in d
>>> assert 'foo' not in d # 'foo' 不是dict中的元素
询问某substring是否在string中:
>>> s = 'foobar' >>> assert 'b' in s >>> assert 'x' not in s >>> assert 'foo' in s
尽管绝大多数容器都提供了某种方式来获取其中的每一个元素,但这并不是容器本身提供的能力,而是可迭代对象赋予了容器这种能力,当然并不是所有的容器都是可迭代的,比如:Bloom filter,虽然Bloom filter可以用来检测某个元素是否包含在容器中,但是并不能从容器中获取其中的每一个值,因为Bloom filter压根就没把元素存储在容器中,而是通过一个散列函数映射成一个值保存在数组中。
可迭代对象(iterable)
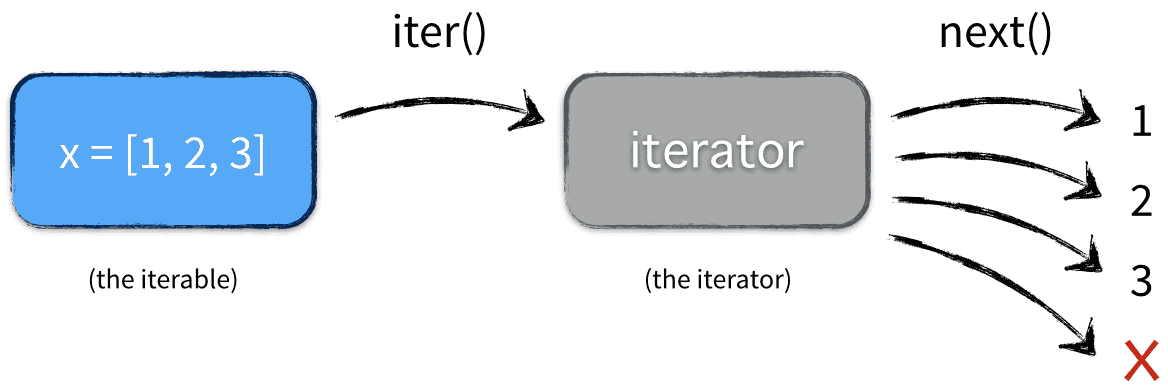
刚才说过,很多容器都是可迭代对象,此外还有更多的对象同样也是可迭代对象,比如处于打开状态的files,sockets等等。但凡是可以返回一个迭代器的对象都可称之为可迭代对象,听起来可能有点困惑,没关系,先看一个例子:
>>> x = [1, 2, 3] >>> y = iter(x) >>> z = iter(x) >>> next(y) 1 >>> next(y) 2 >>> next(z) 1 >>> type(x) <class 'list'> >>> type(y) <class 'list_iterator'>
这里x是一个可迭代对象,可迭代对象和容器一样是一种通俗的叫法,并不是指某种具体的数据类型,list是可迭代对象,dict是可迭代对象,set也是可迭代对象。y和z是两个独立的迭代器,迭代器内部持有一个状态,该状态用于记录当前迭代所在的位置,以方便下次迭代的时候获取正确的元素。迭代器有一种具体的迭代器类型,比如list_iterator,set_iterator。可迭代对象实现了__iter__方法,该方法返回一个迭代器对象。
当运行代码:
x = [1, 2, 3] for elem in x: ...
反编译该段代码,你可以看到解释器显示地调用GET_ITER指令,相当于调用iter(x),FOR_ITER指令就是调用next()方法,不断地获取迭代器中的下一个元素,但是你没法直接从指令中看出来,因为他被解释器优化过了。
>>> import dis >>> x = [1, 2, 3] >>> dis.dis('for _ in x: pass') 1 0 SETUP_LOOP 14 (to 17) 3 LOAD_NAME 0 (x) 6 GET_ITER >> 7 FOR_ITER 6 (to 16) 10 STORE_NAME 1 (_) 13 JUMP_ABSOLUTE 7 >> 16 POP_BLOCK >> 17 LOAD_CONST 0 (None) 20 RETURN_VALUE
迭代器(iterator)
那么什么迭代器呢?它是一个带状态的对象,他能在你调用next()方法的时候返回容器中的下一个值,任何实现了__iter__和__next__()(python2中实现next())方法的对象都是迭代器,__iter__返回迭代器自身,__next__返回容器中的下一个值,如果容器中没有更多元素了,则抛出StopIteration异常,至于它们到底是如何实现的这并不重要。
所以,迭代器就是实现了工厂模式的对象,它在你每次你询问要下一个值的时候给你返回。有很多关于迭代器的例子,比如itertools函数返回的都是迭代器对象。
生成无限序列:
Python >>> from itertools import count >>> counter = count(start=13) >>> next(counter) 13 >>> next(counter) 14 1 2 3 4 5 6 >>> from itertools import count >>> counter = count(start=13) >>> next(counter) 13 >>> next(counter) 14
从一个有限序列中生成无限序列:
>>> from itertools import cycle >>> colors = cycle(['red', 'white', 'blue']) >>> next(colors) 'red' >>> next(colors) 'white' >>> next(colors) 'blue' >>> next(colors) 'red'
从无限的序列中生成有限序列:
>>> from itertools import islice >>> colors = cycle(['red', 'white', 'blue']) # infinite >>> limited = islice(colors, 0, 4) # finite >>> for x in limited: ... print(x) red white blue red
为了更直观地感受迭代器内部的执行过程,我们自定义一个迭代器,以斐波那契数列为例:
class Fib: def __init__(self): self.prev = 0 self.curr = 1 def __iter__(self): return self def __next__(self): value = self.curr self.curr += self.prev self.prev = value return value >>> f = Fib() >>> list(islice(f, 0, 10)) [1, 1, 2, 3, 5, 8, 13, 21, 34, 55]
Fib既是一个可迭代对象(因为它实现了__iter__方法),又是一个迭代器(因为实现了__next__方法)。实例变量prev和curr用户维护迭代器内部的状态。每次调用next()方法的时候做两件事:
- 为下一次调用
next()方法修改状态 - 为当前这次调用生成返回结果
迭代器就像一个懒加载的工厂,等到有人需要的时候才给它生成值返回,没调用的时候就处于休眠状态等待下一次调用。
生成器(generator)
生成器算得上是Python语言中最吸引人的特性之一,生成器其实是一种特殊的迭代器,不过这种迭代器更加优雅。它不需要再像上面的类一样写__iter__()和__next__()方法了,只需要一个yiled关键字。 生成器一定是迭代器(反之不成立),因此任何生成器也是以一种懒加载的模式生成值。用生成器来实现斐波那契数列的例子是:
def fib(): prev, curr = 0, 1 while True: yield curr prev, curr = curr, curr + prev >>> f = fib() >>> list(islice(f, 0, 10)) [1, 1, 2, 3, 5, 8, 13, 21, 34, 55]
fib就是一个普通的python函数,它特殊的地方在于函数体中没有return关键字,函数的返回值是一个生成器对象。当执行f=fib()返回的是一个生成器对象,此时函数体中的代码并不会执行,只有显示或隐示地调用next的时候才会真正执行里面的代码。
生成器在Python中是一个非常强大的编程结构,可以用更少地中间变量写流式代码,此外,相比其它容器对象它更能节省内存和CPU,当然它可以用更少的代码来实现相似的功能。现在就可以动手重构你的代码了,但凡看到类似:
def something(): result = [] for ... in ...: result.append(x) return result
都可以用生成器函数来替换:
Python def iter_something(): for ... in ...: yield x 1 2 3 def iter_something(): for ... in ...: yield x
生成器表达式(generator expression)
生成器表达式并不是真正创建数字列表,而是返回一个生成器对象,生成器表达式是列表推倒式的生成器版本,看起来像列表推导式,但是它返回的是一个生成器对象而不是列表对象。此对象在每次计算出一条目后,把这个条目“产生”(yield)出来。
生成器表达式使用了“惰性计算”或称作“延迟求值”的机制
使用场景:
序列过长,并且每次只需要获取一个元素时,应当考虑使用生成器表达式而不是列表解析。
>>> a = (x*x for x in range(10)) >>> a <generator object <genexpr> at 0x401f08> >>> sum(a) 285
emumerate (枚举函数)
range可在非完备遍历中用于产生索引偏移,而非偏移处的元素;
如果同时需要偏移索引和偏移元素,则可使用emumerate()函数;
此内置函数返回一个生成器对象。
举例:
url = "www.baidu.com" g1 = enumerate(url) print(g1.__next__()) 同时打印出索引和元素的生成器对象进行对应
总结
- 容器是一系列元素的集合,str、list、set、dict、file、sockets对象都可以看作是容器,容器都可以被迭代(用在for,while等语句中),因此他们被称为可迭代对象。
- 可迭代对象实现了
__iter__方法,该方法返回一个迭代器对象。 - 迭代器持有一个内部状态的字段,用于记录下次迭代返回值,它实现了
__next__和__iter__方法,迭代器不会一次性把所有元素加载到内存,而是需要的时候才生成返回结果。 - 生成器是一种特殊的迭代器,它的返回值不是通过
return而是用yield。
参考链接:https://docs.python.org/2/library/stdtypes.html#iterator-types