excel02.py
# -*- coding: utf-8 -*-
#@File :excel_oper_02.py
#@Auth : wwd
#@Time : 2020/12/7 8:16 下午
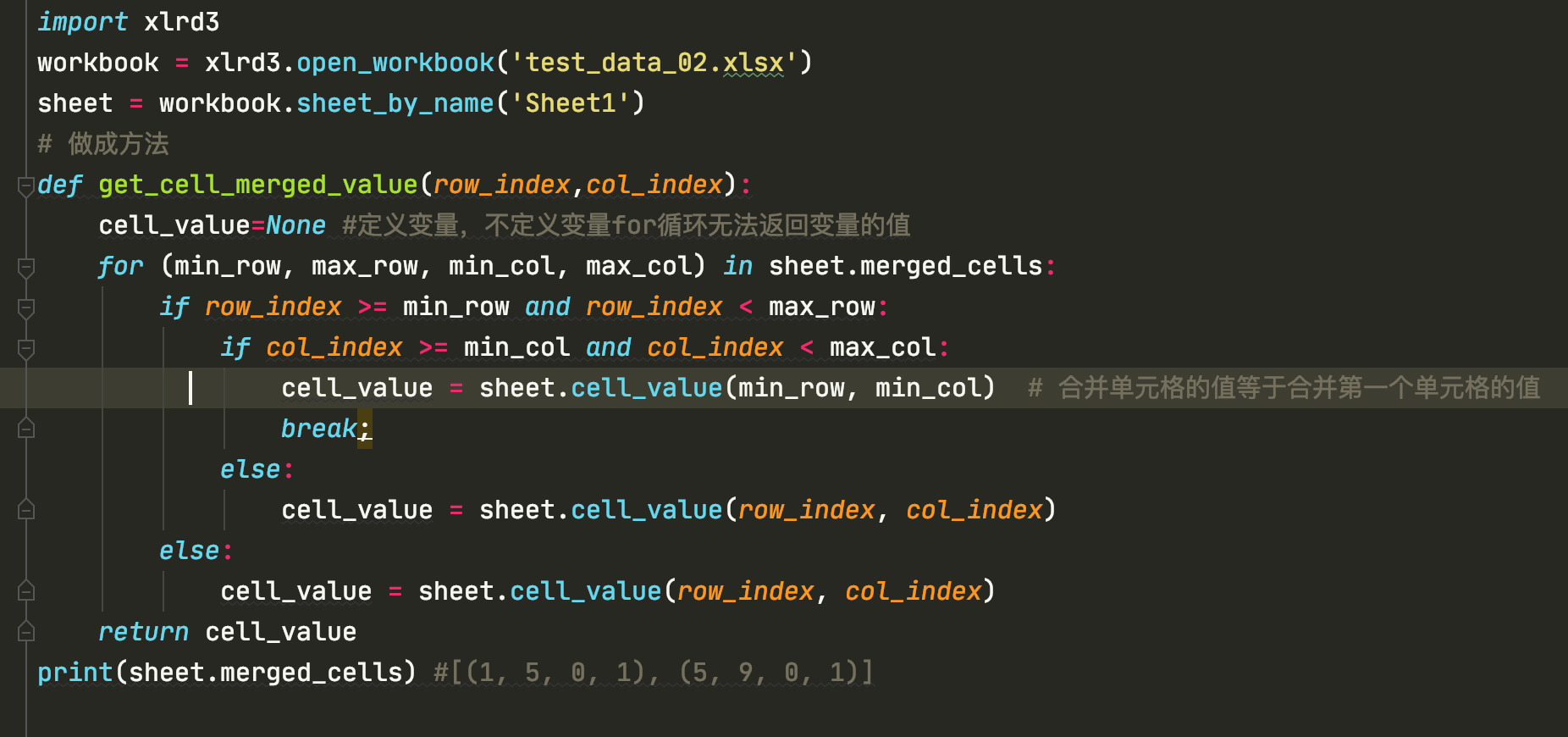
import xlrd3
workbook = xlrd3.open_workbook('test_data_02.xlsx')
sheet = workbook.sheet_by_name('Sheet1')
# 做成方法
def get_cell_merged_value(row_index,col_index):
cell_value=None #定义变量,不定义变量for循环无法返回变量的值
for (min_row, max_row, min_col, max_col) in sheet.merged_cells:
if row_index >= min_row and row_index < max_row:
if col_index >= min_col and col_index < max_col:
cell_value = sheet.cell_value(min_row, min_col) # 合并单元格的值等于合并第一个单元格的值
break;
else:
cell_value = sheet.cell_value(row_index, col_index)
else:
cell_value = sheet.cell_value(row_index, col_index)
return cell_value
print(sheet.merged_cells) #[(1, 5, 0, 1), (5, 9, 0, 1)]
# for i in range(1,9):
# cell_value = get_cell_merged_value(i,0) # 2,0
# print(cell_value)
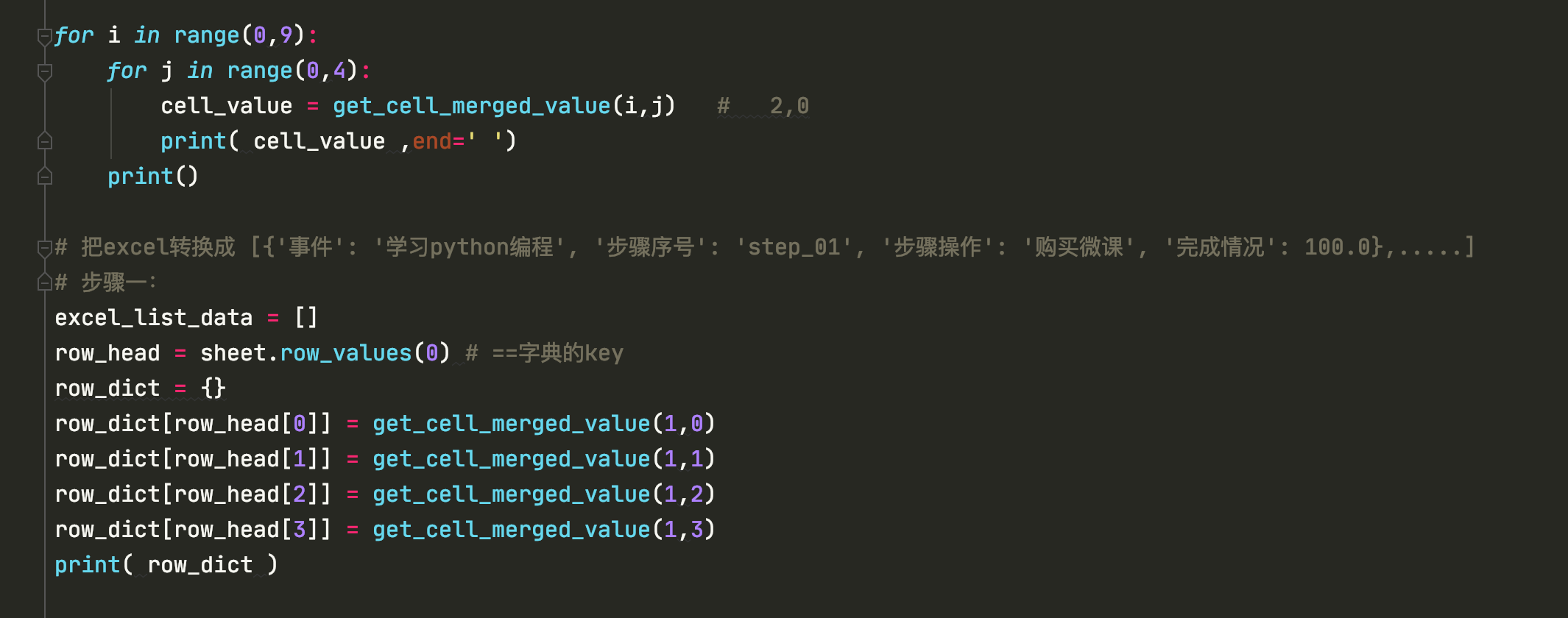
for i in range(0,9):
for j in range(0,4):
cell_value = get_cell_merged_value(i,j) # 2,0
print( cell_value ,end=' ')
print()
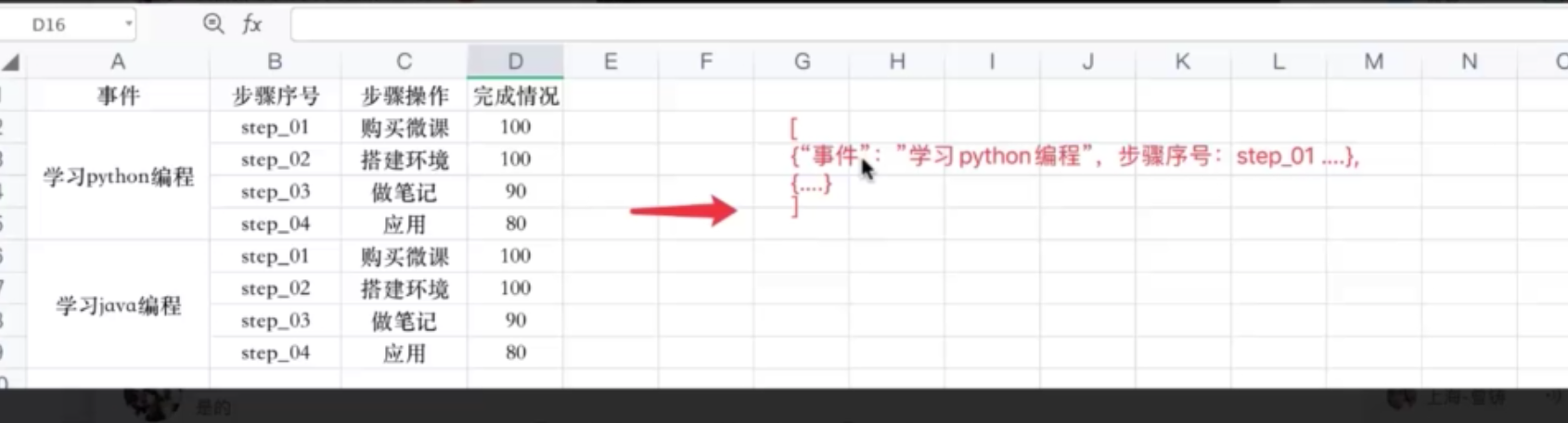
# 把excel转换成 [{'事件': '学习python编程', '步骤序号': 'step_01', '步骤操作': '购买微课', '完成情况': 100.0},.....]
# 步骤一:
excel_list_data = []
row_head = sheet.row_values(0) # ==字典的key
row_dict = {}
row_dict[row_head[0]] = get_cell_merged_value(1,0)
row_dict[row_head[1]] = get_cell_merged_value(1,1)
row_dict[row_head[2]] = get_cell_merged_value(1,2)
row_dict[row_head[3]] = get_cell_merged_value(1,3)
print( row_dict )
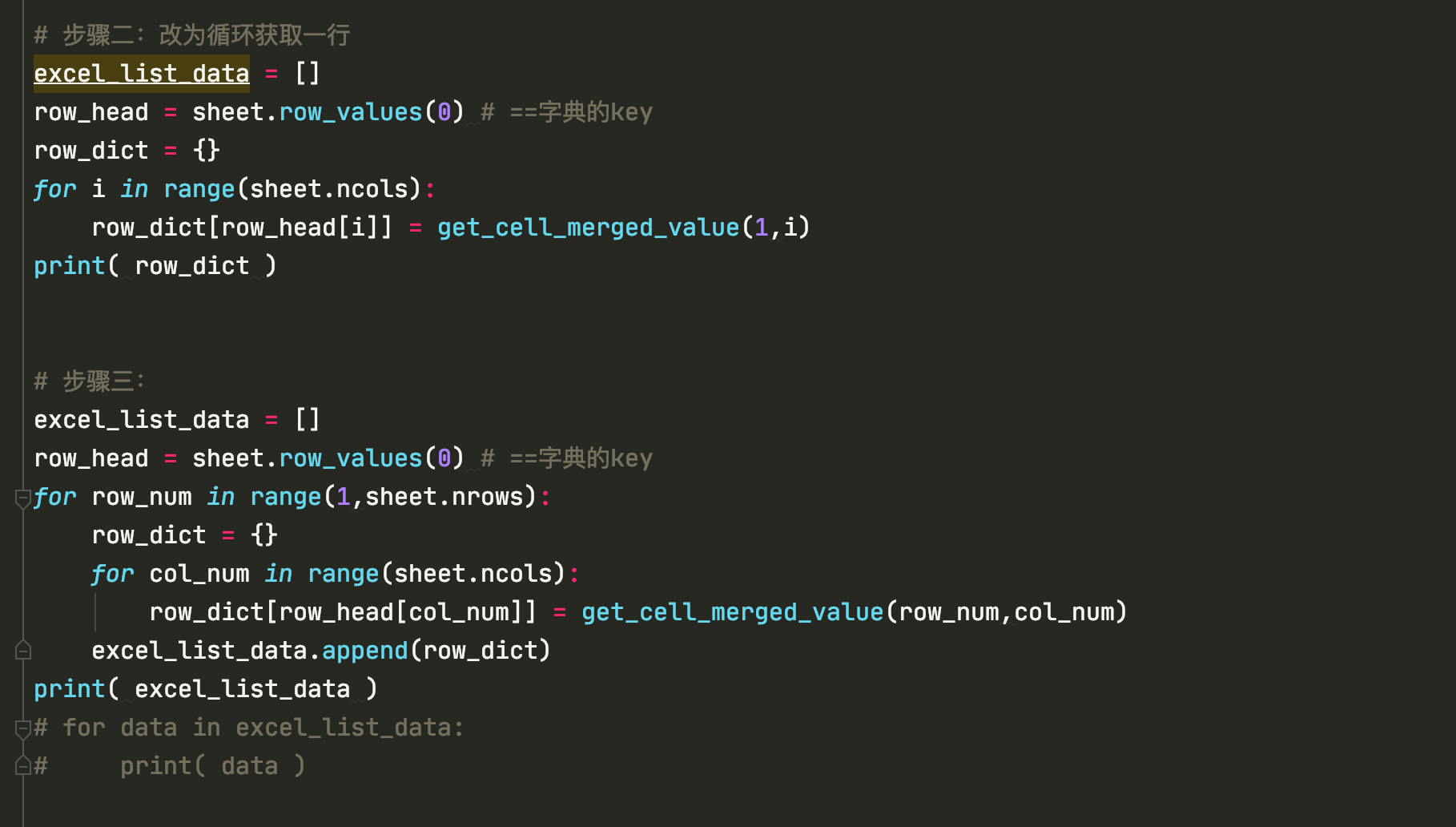
# 步骤二:改为循环获取一行
excel_list_data = []
row_head = sheet.row_values(0) # ==字典的key
row_dict = {}
for i in range(sheet.ncols):
row_dict[row_head[i]] = get_cell_merged_value(1,i)
print( row_dict )
# 步骤三:
excel_list_data = []
row_head = sheet.row_values(0) # ==字典的key
for row_num in range(1,sheet.nrows):
row_dict = {}
for col_num in range(sheet.ncols):
row_dict[row_head[col_num]] = get_cell_merged_value(row_num,col_num)
excel_list_data.append(row_dict)
print( excel_list_data )
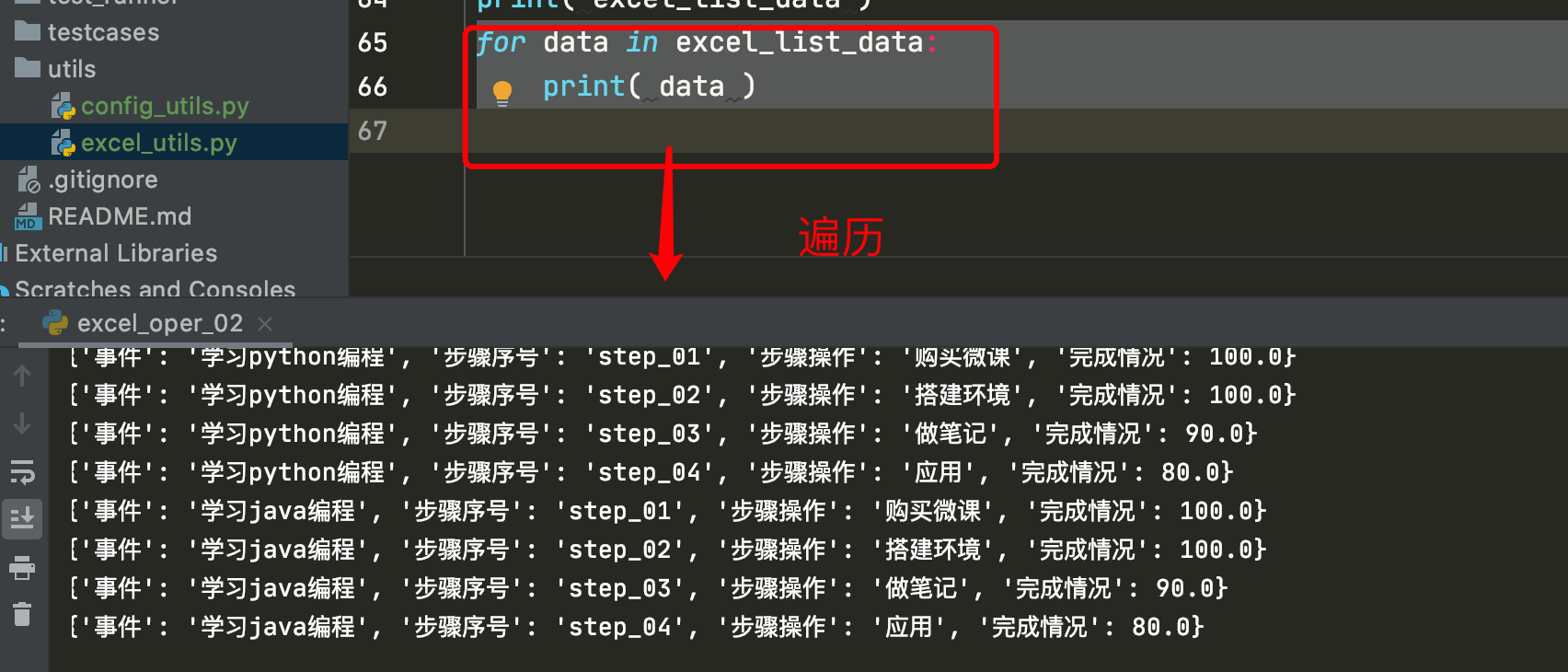
# for data in excel_list_data:
# print( data )
运行结果:
[{'事件': '学习python编程', '步骤序号': 'step_01', '步骤操作': '购买微课', '完成情况': 100.0}, {'事件': '学习python编程', '步骤序号': 'step_02', '步骤操作': '搭建环境', '完成情况': 100.0}, {'事件': '学习python编程', '步骤序号': 'step_03', '步骤操作': '做笔记', '完成情况': 90.0}, {'事件': '学习python编程', '步骤序号': 'step_04', '步骤操作': '应用', '完成情况': 80.0}, {'事件': '学习java编程', '步骤序号': 'step_01', '步骤操作': '购买微课', '完成情况': 100.0}, {'事件': '学习java编程', '步骤序号': 'step_02', '步骤操作': '搭建环境', '完成情况': 100.0}, {'事件': '学习java编程', '步骤序号': 'step_03', '步骤操作': '做笔记', '完成情况': 90.0}, {'事件': '学习java编程', '步骤序号': 'step_04', '步骤操作': '应用', '完成情况': 80.0}]

excel_utils.py 封装
# -*- coding: utf-8 -*-
#@File :excel_utils.py
#@Auth : wwd
#@Time : 2020/12/7 9:13 下午
import xlrd3
class ExcelUtils:
def __init__(self,excel_file_path,sheet_name):
self.excel_file_path=excel_file_path
self.sheet_name =sheet_name
self.sheet = self.get_sheet()
def get_sheet(self):
''' 根据文件路径及表格名称获取表格对象 '''
work_book =xlrd3.open_workbook(self.excel_file_path)
sheet=work_book.sheet_by_name(self.sheet_name)
return sheet
def get_row_count(self):
'''获取表格的行数'''
row_count=self.sheet.nrows
return row_count
def get_column_count(self):
'''获取表格的列数'''
column_count =self.sheet.ncols
return column_count
def get_merge_cell_value(self,row_index,col_index):
''' 获取excel单元格的数据(包含合并单元格的数据)'''
cell_value = None
for (min_row, max_row, min_col, max_col) in self.sheet.merged_cells:
if row_index >= min_row and row_index < max_row:
if col_index >= min_col and col_index < max_col:
cell_value = self.sheet.cell_value(min_row, min_col) # 合并单元格的值等于合并第一个单元格的值
break;
else:
cell_value = self.sheet.cell_value(row_index, col_index)
else:
cell_value = self.sheet.cell_value(row_index, col_index)
return cell_value

excel02.py
运行报错:

修改:
