1框架数据源概述
2处理数据源用到的工具包详解
3数据源处理设计思路和实战
1框架数据源概述
框架中的数据源是指作为测试框架执行时,输入的相关
配置数据、测试用例数据等。
配置数据一般使用后缀为.ini的文件进行配置,主要对比
如测试主机地址、测试日志和报告路径等进行配置。
在实际的框架设计中,测试用例数据我们可以使用不同
方式的文件来构造数据源,只要该方式能完成接口自动化测
试框架的易操作和维护即可。如 excel、xml、yaml、json、
数据库等。把测试需要用到的数据录入到上述相应文件或数
据库中,然后使用代码把数据读取并进行加工处理。
2处理数据源需要用到的工具包如下:
configparser(系统自带):读取.ini配置文件
xlrd/xlwt(第三方):用来读写excel文件,可以用其它包
json(系统自带):处理json数据模块(略
configparser模块简介:
configparser模块是用来解析ini配置文件的解析器。
ini配置文件的结构如右图:
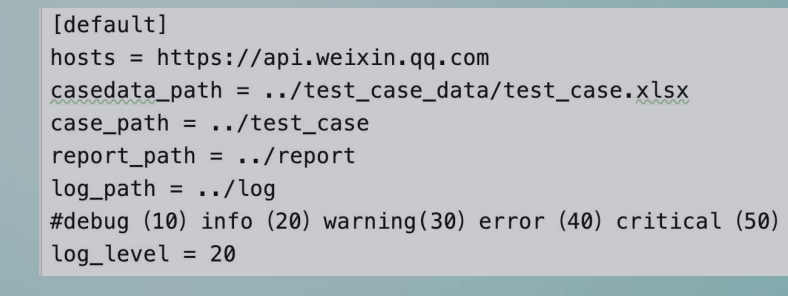
ini文件结构需要注意以下几点:
键值对可用=或者:进行分隔
section的名字是区分大小写的,而key的名字是不区分大小写的
键值对中头部和尾部的空白符会被去掉
值可以为多行
配置文件可以包含注释,注释以#或者;为前缀

xlrd/xlwt模块简介:
python操作excel主要用到xlrd和xlwt这两个库,即xlrd是读excel,xlwt
是写excel的库。
xlrd/xlwt模块安装:
和其它模块安装方式一样,可以离线安装和在线安装。
一般用在线安装方式: pip install xlrd 和 pip install xlwt
在框架中我们用xlrd读取excel文件的操作居多,暂时只讲该模块的使用。
xlrd模块使用:
import xlrd
data = xlrd.open_workbook(filename)#文件名以及路径
table = data.sheets()[0] #通过索引顺序获取
table = data.sheet_by_name(sheet_name)#通过名称获取
行的操作
nrows = table.nrows #获取该sheet中的有效行数
table.row(rowx) #返回由该行中所有的单元格对象组成的列表
列的操作
ncols = table.ncols #获取列表的有效列数
table.col(colx, start_rowx=0, end_rowx=None) #返回由该列中所有的单元格对
象组成的列表
单元格操作
table.cell(rowx,colx) #返回单元格对象
table.cell_type(rowx,colx) #返回单元格中的数据类型
table.cell_value(rowx,colx) #返回单元格中的数据
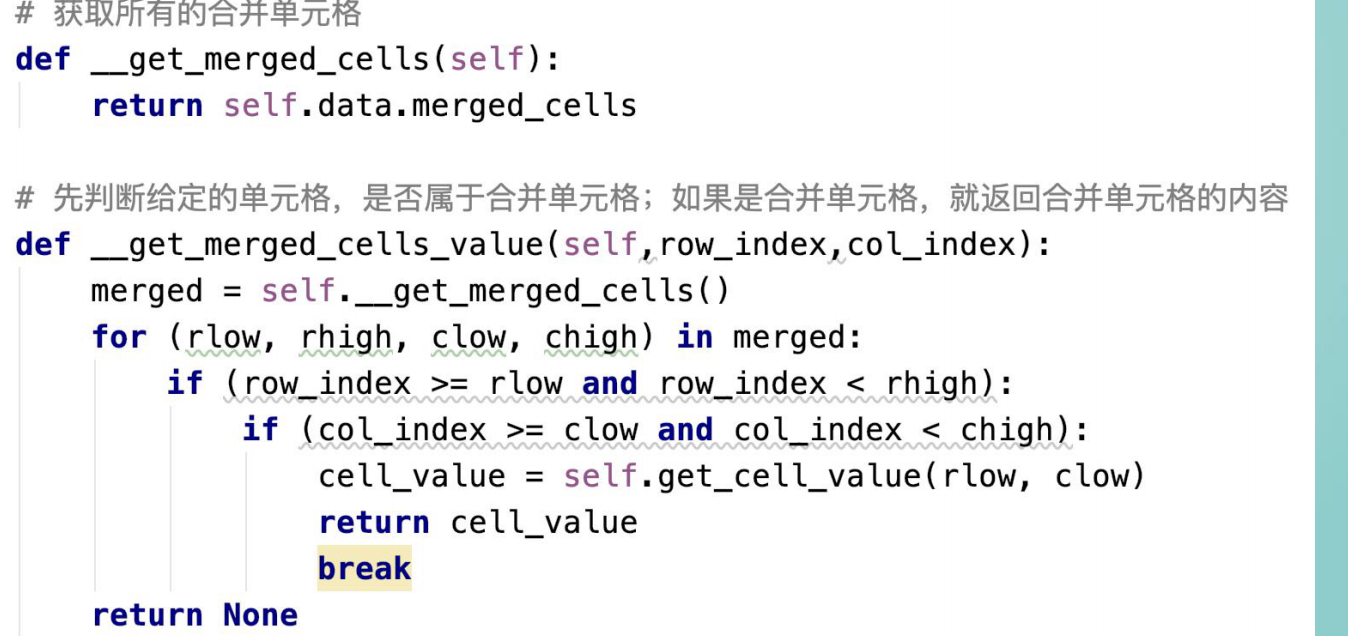
合并单元格的读取操作
table.merged_cells #获取当前文档中的所有合并单元格的位置信息
它返回的是一个列表,每一个元素是合并单元格的位置信息的数组,数组包含
四个元素(起始行,结束行,起始列,结束列)
合并单元格默认不处理的情况下,返回为null,一般是希望所有被合并的每个
单元格都返回合并单元格的内容。可以用判断来实现

3数据源处理设计思路和实战
配置文件数据源设计思路:
配置文件之前讲过使用自带的configparser模块来读取数据,可以进行简单封装,更
适合在框架中使用。

上述代码完成封装操作,然后再编写config.py文件,达到简单调用:
HOSTS = ConfigUtil().read_value('default','hosts')
excel用例数据源设计思路:
本接口测试框架由于考虑用例的独立性(即每个用例都能单独执行的思路),所需
要的用例字段包含如下:
测试用例编号 测试用例名称 用例执行 测试用例步骤 接口名称
请求方式 请求地址 请求参数(get) 提交数据(post) 取值方式
传值变量 取值代码 期望结果类型 期望结果
用例执行:可以设置执行或者不执行当前用例
测试用例步骤:考虑设计偏业务的接口用例要多个接口顺序执行的情况
取值方式/传值变量/取值代码:做接口关联处理(上下接口之间传值)
期望结果类型:支持json方式、正则方式比对
excel用例数据源设计思路上:
把设计的excel中的数据转换成如下格式的列表,方便后期进行参数化执行测试用例。
[
{'column0': 'case01', 'column1': '用例名称1', 'column2': '是'...},
{'column0': 'case02', 'column1': '用例名称2', 'column2': '是'...},
{'column0': 'case02', 'column1': '用例名称2', 'column2': '是'...}
]
column0代表第一列的列名,其它依次内推;由于用例有多个步骤,采用在excel合并单元
格的写法实现,所以上面例子中会出现case02、用例名称2相同的情况
核心实现代码:
从第2行开始遍历 整个表格,遍历完 一列就组装成字典:
key=column
value=单元格值
在中间进行是否是 合并单元格的判断, 如果是就使用合并的值。

核心实现代码:
excel用例数据源设计思路下:
依照上述方法把数据从excel整理出来后,再进行加工,使其成为满足paramunittest
参数化测试所需要的数据格式。关于paramunittest在后续章节中会介绍讲解。需要转换成
如下格式的数据:
{'case_id': 'case01','case_info':[按步骤的case信息]}
{'case_id': 'case02','case_info':[按步骤的case信息]}
要把数据转换成这样,对数据要有两个加工步骤:
1、把数据内部的key名由column 换成真实的列名
2、使用 setdefault(k, []).append(v) 该表达式实现数据的抓换
3、把数据调整成为字典格式给paramunittest使用

使用如下的代码进行转换即可:

转换后的数据格式:
{'case_id': 'case编号', 'case_info': [case按步骤的列表信息]}