Distributed programming is the art of solving the same problem that you can solve on a single computer using multiple computers.
Scalability
处理每件事情都需要注意它的规模,如果规模达到一定程度,处理的难度明显加强。例如你可以计算出一个房间中的人数,但是很难计算出一个国家的人数。在一个可扩展的分布式系统中,系统从小变大,但是相关性能没有变差。
比如在单机文件系统上加 RAID5 做数据冗余,来解决单机文件系统的可靠性问题。假设 RAID5 的数据修复时间是1天(实际上往往做不到,尤其是业务系统本身压力比较大的情况下,留给 RAID 修复用的磁盘读写带宽很有限),这种方案单机的可靠性大概是100年丢失一次数据(即可靠性是2个9)。看起来尚可?但是你得小心两种情况。一种是你的集群规模变大,你仍然沿用这个土方法,比如你现在有 100 台这样的机器,那么就会变成1年就丢失一次数据。另一种情况是如果实际数据修复时间是 3 天,那么单机的可靠性就直降至4年丢失一次数据,100台就会是15天丢失一次数据。这个数字显然无法让人接受。
scalability(可扩展性)是指在一个系统、网络以及处理能力范围内,可以处理不断增长的任务,并它们可以加强自己的能力来适应任务的增长(有点儿抽象)。
- 大小可扩展性:增加节点可以线性增加性能,并数据集的增加不增加延迟性
- 地理位置可扩展性:数据中心间延迟性采用合理的方式处理,则可以跨数据中心,减少用户数据查询响应时间
- 管理可扩展性:增加更多的节点不增加管理的开销
Performance
性能特点是在一定任务情况下,系统处理所需要的时间和资源使用量来衡量的。如快速回复(低延迟性)、高吞吐量以及计算资源低使用率。但是这几个性能,在实际中只能权衡。
latency
延迟性指事件初始化和发生的时间段。比如在分布式系统中写操作,就写发生到新的数据可以被用户看到的时间段。latency经常要受一些硬件(ram的性能、cpu性能)的限制。
Availability
指系统处在运行状态时间的比例,用户不可以访问,那么系统就是不可用。
分布式系统上可以获得单机非常的特性,比如单机就是无法容忍机器宕机。分布式系统可以由一些非常不好的组件构成,但是可以提供可信赖的系统。
Availability = uptime / (uptime + downtime)
例如:
| Availability % | How much downtime is allowed per year? |
|---|---|
| 90% ("one nine") | More than a month |
| 99% ("two nines") | Less than 4 days |
| 99.9% ("three nines") | Less than 9 hours |
| 99.99% ("four nines") | Less than an hour |
| 99.999% ("five nines") | ~ 5 minutes |
| 99.9999% ("six nines") | ~ 31 seconds |
availability不仅仅是uptime,还可能受网络中断以及该业务超出系统的功能的影响。
Fault tolerance
指在故障发生时,系统还可以正常运行(和没有发生故障时功能相同)的能力。
容错归结为:确定你所期望的故障,然后设计一个系统或一个算法可以容错他们。没有考虑过故障是无法容错的。
什么在阻止我们获得理想的状态呢?
有以下两个硬件方面的因素:
1 nodes的数量
2 nodes的距离
伴随着以下限制:
1 独立节点的增加,就增加了系统失败的概率(减小了availability并增加了管理成本)
2 独立节点的增加,就增加了节点的通信 (降低了可扩展的performance)
3 节点的跨机房部署,增加了节点之间的延迟性(降低了某些操作的performance)
可用性和性能是系统必须保证的,更高一级,可以考虑SLA(服务等级协议),如果我写数据,如何更快在其他地方看到?
在数据被写入时,什么可以保证耐久性?如果让系统运行一个计算,如何迅速返回结果?当组件发生故障,执行取出操作,什么样的影响将在在系统上?
设计技术:partition and replicate
如果要把数据分布在不同节点,那么上面两个技术非常关键。数据可以被分割在多个节点(partition),以允许更多的并行处理。也可以被复制或缓存在不同的节点上,以减少客户端和服务器之间距离以及更大的容错性(replicate)
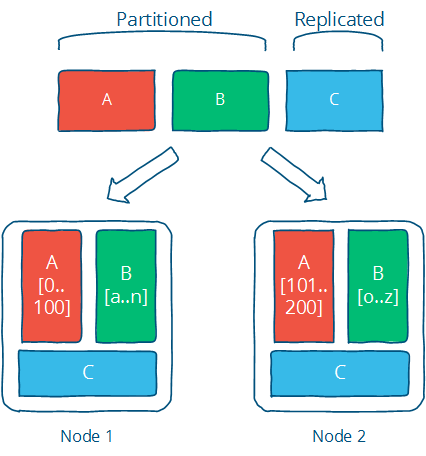
partitioning是把数据分成相互独立的数据集,这样可以避免数据的增长带来的影响。partitioning是通过限制被检查数据集的大小和定位相关数据在相同partition来提高性能的(如一个数据一分钟的记录,那么这个数据分布在一台机器和多台机器性能是截然不同的)。容许partition独立失败,来挺高可用性。在不可用情况下,容易更多节点失败。
replication可以通过复制数据集,提高计算和带宽能力。可以提高可用性,在不可用情况下,容易更多节点失败。当然replication又会带来一致性问题,后面再讨论一致性的问题。