
封面图是 凌晨 3点半起来更文的锁屏桌面。
前言
从上周六 7 号到今天的 11 号,我都在医院,小孩因肺炎已经住院了,我白天和晚上的时间需要照顾娃,只能在娃睡觉的时候肝文了。对了,医院没有宽带和 WiFi,我用的手机开的热点~
本篇主要内容
这篇主要是理论 + 实践相结合。实践部分涉及到如何把链路追踪 Sleuth + Zipkin 加到我的 Spring Cloud 《佳必过》开源项目上。
本篇知识点:
- 链路追踪基本原理
- 如何在项目中轻松加入链路追踪中间件
- 如何使用链路追踪排查问题。
一、为什么要用链路追踪?
1.1 因:拆分服务单元
微服务架构其实是一个分布式的架构,按照业务划分成了多个服务单元。
由于服务单元的数量是很多的,有可能几千个,而且业务也会更复杂,如果出现了错误和异常,很难去定位。
1.2 因:逻辑复杂
比如一个请求需要调用多个服务才能完成整个业务闭环,而内部服务的代码逻辑和业务逻辑比较复杂,假如某个服务出现了问题,是难以快速确定那个服务出问题的。
1.3 果:快速定位
而如果我们加上了分布式链路追踪,去跟踪一个请求有哪些服务参与其中,参与的顺序是怎样的,这样我们就知道了每个请求的详细经过,即使出了问题也能快速定位。
二、链路追踪的核心
链路追踪组件有 Twitter 的可视化链路追踪组件 Zipkin、Google 的 Dapper、阿里的 Eagleeye 等,而 Sleuth 是 Spring Cloud 的组件。Spring Cloud Sleuth 借鉴了 Dapper 的术语。
本文主要讲解 Sleuth + Zipkin 结合使用来更好地实现链路追踪。
为什么能够进行整条链路的追踪?其实就是一个 Trace ID 将 一连串的 Span 信息连起来了。根据 Span 记录的信息再进行整合就可以获取整条链路的信息。下面
2.1 Span(跨度)
-
大白话:远程调用和 Span
一对一。 -
基本的工作单元,每次发送一个远程调用服务就会产生一个 Span。
-
Span 是一个 64 位的唯一 ID。
-
通过计算 Span 的开始和结束时间,就可以统计每个服务调用所花费的时间。
2.2 Trace(跟踪)
-
大白话:一个 Trace 对应多个 Span,
一对多。 -
它由一系列 Span 组成,树状结构。
-
64 位唯一 ID。
-
每次客户端访问微服务系统的 API 接口,可能中间会调用多个微服务,每次调用都会产生一个新的 Span,而多个 Span 组成了 Trace
2.3 Annotation(注解)
链路追踪系统定义了一些核心注解,用来定义一个请求的开始和结束,注意是微服务之间的请求,而不是浏览器或手机等设备。注解包括:
cs- Client Sent:客户端发送一个请求,描述了这个请求调用的Span的开始时间。注意:这里的客户端指的是微服务的调用者,不是我们理解的浏览器或手机等客户端。sr- Server Received:服务端获得请求并准备开始处理它,如果将其sr减去cs时间戳,即可得到网络传输时间。ss- Server Sent:服务端发送响应,会记录请求处理完成的时间,ss时间戳减去sr时间戳,即可得到服务器请求的时间。cr- Client Received:客户端接收响应,Span 的结束时间,如果cr的时间戳减去cs时间戳,即可得到一次微服务调用所消耗的时间,也就是一个Span的消耗的总时间。
2.4 链路追踪原理
假定三个微服务调用的链路如下图所示:Service 1 调用 Service 2,Service 2 调用 Service 3 和 Service 4。

那么链路追踪会在每个服务调用的时候加上 Trace ID 和 Span ID。如下图所示:

大白话解释:
-
大家注意上面的颜色,相同颜色的代表是同一个 Span ID,说明是链路追踪中的一个节点。
-
第一步:客户端调用
Service 1,生成一个Request,Trace ID和Span ID为空,那个时候请求还没有到Service 1。 -
第二步:请求到达
Service 1,记录了 Trace ID = X,Span ID 等于 A。 -
第三步:
Service 1发送请求给Service 2,Span ID 等于 B,被称作 Client Sent,即客户端发送一个请求。 -
第四步:请求到达
Service 2,Span ID 等于 B,Trace ID 不会改变,被称作 Server Received,即服务端获得请求并准备开始处理它。 -
第五步:
Service 2开始处理这个请求,处理完之后,Trace ID 不变,Span ID = C。 -
第六步:
Service 2开始发送这个请求给Service 3,Trace ID 不变,Span ID = D,被称作 Client Sent,即客户端发送一个请求。 -
第七步:
Service 3接收到这个请求,Span ID = D,被称作 Server Received。 -
第八步:
Service 3开始处理这个请求,处理完之后,Span ID = E。 -
第九步:
Service 3开始发送响应给Service 2,Span ID = D,被称作 Server Sent,即服务端发送响应。 -
第十步:
Service 3收到Service 2的响应,Span ID = D,被称作 Client Received,即客户端接收响应。 -
第十一步:
Service 2开始返回 响应给Service 1,Span ID = B,和第三步的 Span ID 相同,被称作 Client Received,即客户端接收响应。 -
第十二步:
Service 1处理完响应,Span ID = A,和第二步的 Span ID 相同。 -
第十三步:
Service 1开始向客户端返回响应,Span ID = A、 -
Service 3向 Service 4 发送请求和Service 3类似,对应的 Span ID 是 F 和 G。可以参照上面前面的第六步到第十步。
把以上的相同颜色的步骤简化为下面的链路追踪图:
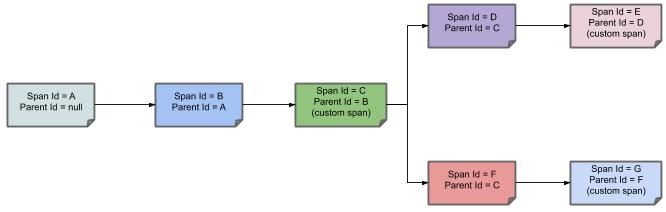
- 第一个节点:Span ID = A,Parent ID = null,
Service 1接收到请求。 - 第二个节点:Span ID = B,Parent ID= A,
Service 1发送请求到Service 2返回响应给Service 1的过程。 - 第三个节点:Span ID = C,Parent ID= B,
Service 2的 中间处理过程。 - 第四个节点:Span ID = D,Parent ID= C,
Service 2发送请求到Service 3返回响应给Service 2的过程。 - 第五个节点:Span ID = E,Parent ID= D,
Service 3的中间处理过程。 - 第六个节点:Span ID = F,Parent ID= C,
Service 3发送请求到 Service 4 返回响应给Service 3的过程。 - 第七个节点:Span ID = G,Parent ID= F,Service 4 的中间处理过程。
通过 Parent ID 即可找到父节点,整个链路就可以进行跟踪追溯了。
三、Spring Cloud 整合 Sleuth
大家可以参照我的 GitHub 开源项目 PassJava(佳必过)。
3.1 引入 Spring Cloud 依赖
在 passjava-common 中引入 Spring Cloud 依赖
因为我们使用的链路追踪组件 Sleuth 是 Spring Cloud 的组件,所以我们需要引入 Spring Cloud 依赖。
<dependencyManagement>
<dependencies>
<!-- Spring Cloud 依赖 -->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-dependencies</artifactId>
<version>Hoxton.SR3</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
3.2 引入Sleuth依赖
引入链路追踪组件 Sleuth 非常简单,在 pom.xml 文件中引入 Sleuth 依赖即可。
在 passjava-common 中引入 Sleuth 依赖:
<!-- 链路追踪组件 -->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-sleuth</artifactId>
</dependency>
3.3 通过日志观察链路追踪
我们先不整合 zipkin 链路追踪可视化组件,而是通过日志的方式来查看链路追踪信息。
文件路径:PassJava-Platformpassjava-questionsrcmain
esourcesapplication.properties
添加配置:
logging.level.org.springframework.cloud.openfeign=debug
logging.level.org.springframework.cloud.sleuth=debug
3.4 启动微服务
启动以下微服务:
-
passjava-gateway 服务(网关)
-
passjava-question 服务(题目中心微服务)
-
renren 服务(Admin 后台管理服务)
启动成功后如下图所示:

3.5 测试跟踪请求
打开 Admin 后台,访问题目中心->题目配置页面,可以看到发送了下面的请求:
http://localhost:8060/api/question/v1/admin/question/list?t=1605170539929&page=1&limit=10&key=

打开控制台,可以看到打印出了追踪日志。

说明:
- 当没有配置 Sleuth 链路追踪的时候,INFO 信息里面是 [passjava-question,,,],后面跟着三个空字符串。
- 当配置了 Sleuth 链路追踪的时候,追踪到的信息是 [passjava-question,504a5360ca906016,e55ff064b3941956,false] ,第一个是 Trace ID,第二个是 Span ID。
四、Zipkin 链路追踪原理
上面我们通过简单的引入 Sleuth 组件,就可以获取到调用链路,但只能通过控制台的输出信息来看,不太方便。
Zipkin 油然而生,一个图形化的工具。Zipkin 是 Twitter 开源的分布式跟踪系统,主要用来用来收集系统的时序数据,进而可以跟踪系统的调用问题。
而且引入了 Zipkin 组件后,就不需要引入 Sleuth 组件了,因为 Zipkin 组件已经帮我们引入了。
Zipkin 的官文:https://zipkin.io
4.1 Zipkin 基础架构

Zipkin 包含四大组件:
- Collection(收集器组件),主要负责收集外部系统跟踪信息。
- Storage(存储组件),主要负责将收集到的跟踪信息进行存储,默认存放在内存中,支持存储到 MySQL 和 ElasticSearch。
- API(查询组件),提供接口查询跟踪信息,给 UI 组件用的。
- UI (可视化 Web UI 组件),可以基于服务、时间、注解来可视化查看跟踪信息。注意:Web UI 不需要身份验证。
4.2 Zipkin 跟踪流程

流程解释:
- 第一步:用户代码发起 HTTP Get 请求,请求路径:/foo。
- 第二步:请求到到跟踪工具后,请求被拦截,会被记录两项信息:标签和时间戳。以及HTTP Headers 里面会增加跟踪头信息。
- 第三步:将封装好的请求传给 HTTP 客户端,请求中包含 X-B3-TraceID 和 X-B3-SpanId 请求头信息。
- 第四步:由HTTP 客户端发送请求。
- 第五步:Http 客户端返回响应 200 OK 后,跟踪工具记录耗时时间。
- 第六步:跟踪工具发送 200 OK 给用户端。
- 第七步:异步报告 Span 信息给 Zipkin 收集器。
五、整合 Zipkin 可视化组件
5.1 启动虚拟机并连接
vagrant up

用 Xshell 工具连接 虚拟机。
5.2 docker 安装 zipkin 服务
- 使用以下命令开始拉取 zipkin 镜像并启动 zipkin 容器。
docker run -d -p 9411:9411 openzipkin/zipkin
- 命令执行完后,会执行下载操作和启动操作。

- 使用 docker ps 命令可以看到 zipkin 容器已经启动成功了。如下图所示:

- 在浏览器窗口打开 zipkin UI
访问服务地址:http://192.168.56.10:9411/zipkin。
5.3 引入 Zipkin 依赖
在公共模块引入 zipkin 依赖
<!-- 链路追踪组件 Zipkin -->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-zipkin</artifactId>
</dependency>
因为 zipkin 包里面已经引入了 sleuth 组件,所以可以把之前引入的 sleuth 组件删掉。
5.4 添加 Zipkin 配置
在需要追踪的微服务模块下添加 zipkin 配置。
# zipkin 的服务器地址
spring.zipkin.base-url=http://192.168.56.10:9411/
# 关闭服务发现,否则 Spring Cloud 会把 zipkin 的 URL 当作服务名称。
spring.zipkin.discovery-client-enabled=false
# 设置使用 http 的方式传输数据,也可以用 RabbitMQ 或 Kafka。
spring.zipkin.sender.type=web
# 设置采样率为 100 %,默认为 0.1(10%)
spring.sleuth.sampler.probability=1
5.5 测试 Zipkin 是否工作
这里我在 passjava-member 微服务中写了一个 API:
passjava-member 服务的 API:getMemberStudyTimeListTest,访问路径为/studytime/list/test/{id}。
passjava-member 服务远程调用 passjava-study 服务的 API:getMemberStudyTimeListTest。
我用 postman 工具测试 member 服务的 API:

打开 Zipkin 工具,搜索 passjava-member 的链路追踪日志,可以看到有一条记录,相关说明如下图所示:

从图中可以看到 passjava-member 微服务调用了 passjava-study 微服务,如图中左半部分所示。
而且 passjava-study 微服务详细的调用时间都记录得非常清楚,如图中右半部分所示。
时间计算:
- 请求传输时间:Server Start - Client Start = 2.577s-2.339s = 0.238s
- 服务端处理时间:Server Finish - Server Start = 2.863s - 2.577s = 0.286s
- 请求总耗时:Client Finish - Client Start = 2.861s - 2.339s = 0.522s
- Passjava-member 服务总耗时:3.156 s
- Passjava-study 服务总耗时:0.521s
- 由此可以看出 passjava-member 服务花费了很长时间,性能很差。
还可以用图标的方式查看:

六、Zipkin 数据持久化
6.1 Zipkin 支持的数据库
Zipkin 存储数据默认是放在内存中的,如果 Zipkin 重启,那么监控数据也会丢失。如果是生成环境,数据丢失会带来很大问题,所以需要将 Zipkin 的监控数据持久化。而 Zipkin 支持将数据存储到以下数据库:
- 内存(默认,不建议使用)
- MySQL(数据量大的话, 查询较为缓慢,不建议使用)
- Elasticsearch(建议使用)
- Cassandra(国内使用 Cassandra 的公司较少,相关文档也不多)
6.2 使用 Elasticsearch 作为储存介质
- 通过 docker 的方式配置 elasticsearch 作为 zipkin 数据的存储介质。
docker run --env STORAGE_TYPE=elasticsearch --env ES_HOSTS=192.168.56.10:9200 openzipkin/zipkin-dependencies
- ES 作为存储介质的配置参数:

七、总结
本篇讲解了链路追踪的核心原理,以及 Sleuth + Zipkin 的组件的原理,以及将这两款组件加到了我的开源项目《佳必过》里面了。
写在最后
这周真的身心俱疲,娃也是受罪,出院后,娃吃饭也不像以前那么积极了,看到医生那种衣服就怕,连看到照片打印机都怕了。生怕是要给他打针、吃药、做雾化的。还未结婚生娃的抓紧时间学习吧,加油少年~
我是悟空,努力变强,变身超级赛亚人!手写了一套 Spring Cloud 进阶教程和 PMP 刷题小程序。