查看CRUSH map
- 从monitor节点上获取CRUSH map
[root@ceph ceph]# ceph osd getcrushmap -o crushmap_compiled_file- 反编译CRUSH map
[root@ceph ceph]# crushtool -d crushmap_compiled_file -o crushmap_decompiled_file- 修改完成后,我们需要编译他
[root@ceph ceph]# crushtool -d crushmap_decompiled_file -o newcrushmap- 将新CRUSH map导入集群中
[root@ceph ceph]# ceph osd setcrushmap -i newcrushmap[root@ceph ceph]# cat crushmap_decompiled_file
# begin crush map
tunable choose_local_tries 0
tunable choose_local_fallback_tries 0
tunable choose_total_tries 50
tunable chooseleaf_descend_once 1
tunable chooseleaf_vary_r 1
tunable straw_calc_version 1
# devices
device 0 osd.0
device 1 osd.1
device 2 osd.2
# types
type 0 osd
type 1 host
type 2 chassis
type 3 rack
type 4 row
type 5 pdu
type 6 pod
type 7 room
type 8 datacenter
type 9 region
type 10 root
# buckets
host ceph-node1 {
id -2 # do not change unnecessarily
# weight 0.000
alg straw
hash 0 # rjenkins1
}
host ceph {
id -3 # do not change unnecessarily
# weight 0.044
alg straw
hash 0 # rjenkins1
item osd.2 weight 0.015
item osd.1 weight 0.015
item osd.0 weight 0.015
}
root default {
id -1 # do not change unnecessarily
# weight 0.044
alg straw
hash 0 # rjenkins1
item ceph-node1 weight 0.000
item ceph weight 0.044
}
# rules
rule replicated_ruleset {
ruleset 0 #rule编号
type replicated #定义pool类型为replicated(还有esurecode模式) min_size 1 #pool中最小指定的副本数量不能小1 max_size 10 #pool中最大指定的副本数量不能大于10 step take default #定义pg查找副本的入口点 step chooseleaf firstn 0 type host #选叶子节点、深度优先、隔离host step emit #结束
}
# end crush map
注:
下面解释来自:https://my.oschina.net/u/2460844/blog/531722
影响crush算法结果的有两种因素,一个就是OSD Map的结构,另外一个就是crush rule。
OSDMap其实就是一个树形的结构,叶子节点是device(也就是osd),其他的节点称为bucket节点,这些bucket都是虚构的节点,可以根据物理结构进行抽象,当然树形结构只有一个最终的根节点称之为root节点,中间虚拟的bucket节点可以是数据中心抽象、机房抽象、机架抽象、主机抽象等。
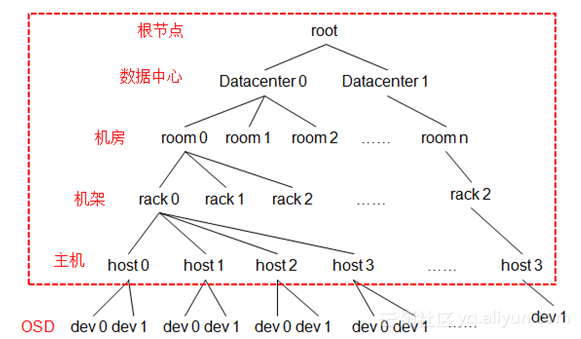
上图中红色框内的节点都是bucket节点,这些节点都是根据实际情况进行抽象得来的。
其实也就是实际中整个物理拓扑结构。这个拓扑里的每个节点都有一个权重值,这个权重值等于所有子节点的权重之和,叶子节点的重量由osd的容量决定,一般设定1T的权重为1。
这个权重值在crush算法中也有很重要的地位。
其实也就是实际中整个物理拓扑结构。这个拓扑里的每个节点都有一个权重值,这个权重值等于所有子节点的权重之和,叶子节点的重量由osd的容量决定,一般设定1T的权重为1。
这个权重值在crush算法中也有很重要的地位。
bucket类型解释:
对于bucket节点不只是虚设的节点,bucket同样有type。bucket的type有四种类型结构,uniform、list、tree、straw。这四种bucket有着不同的特性,bucket的type设定同样也影响着crush算法。不同的 类型定位数据在哪个子节点的过程不同。
crush rule主要作用:
- 从OSD Map中的哪个节点开始查找
- 使用那个节点作为故障隔离域
- 定位副本的搜索模式(广度优先 or 深度优先)