1 Elasticsearch安装
1.1 ES6.0版本安装head插件
1.1 下载head插件
下载地址:https://github.com/mobz/elasticsearch-head;点击clone or download按钮
1.2 安装node.js
下载地址:https://nodejs.org/en/download/
1.3 安装grunt
运行head需要借助grunt命令 ,但是安装grunt需要借助npm
进入nodejs安装根目录,输入以下命令安装grunt
npm install -g grunt -cli
1.4 安装pathomjs
进入head根目录,输入npm install命令
1.5 运行head
在head根目录下执行grunt server,出现如图所示内容则启动成功!

1.6 修改配置文件
打开 elasticsearch安装目录/config/elasticsearch.yml
在配置文件末尾加上以下两句
http.cors.enabled: true http.cors.allow-origin: "*"
修改完成后保存重启elasticsearch,然后在head根目录下键入命令grunt server,出现1.5图示则在浏览器地址栏访问http://localhost:9100
出现下图所示内容表示head插件安装成功。

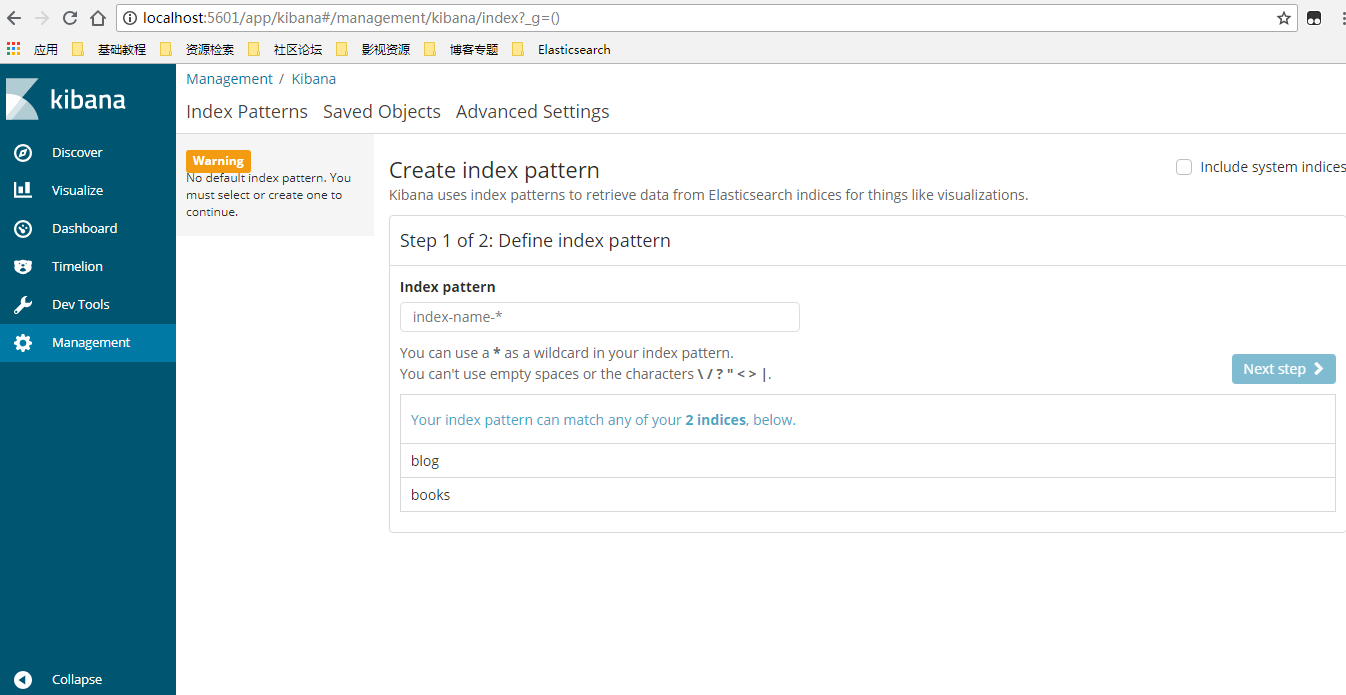
1.2 ElasticSearch6.x版本安装kibana插件
2.1 下载地址 : https://www.elastic.co/downloads/kibana
1.7 进入到下载目录,解压kibana-6.1.1-windows-x86_64.zip
1.8 进入config编辑kibana.yml,修改kibana的监听端口和kibana查看elasticsearch地址
# Kibana is served by a back end server. This setting specifies the port to use. server.port: 5601 # The URL of the Elasticsearch instance to use for all your queries. elasticsearch.url: "http://localhost:9200"
2.4进入bin目录下双击kibana.bat,启动kibana
默认情况下 http://localhost:5601/ 即可访问kibana主页,若elasticsearch连接正常即可看到如下界面表示安装成功。
1.3 Elasticsearch安装ik分词插件
下载地址:
https://github.com/medcl/elasticsearch-analysis-ik/
解压zip文件复制到plugin目录下即可
使用ik分词器与使用标准分词器进行对比
(1)使用standard分词器,对中文分词效果不佳

分词效果

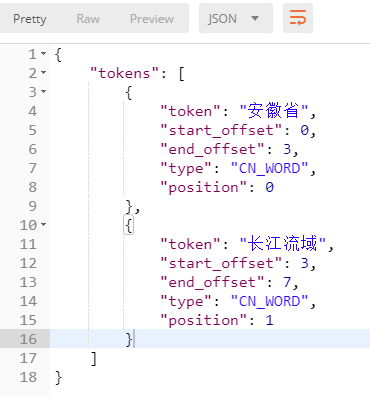
(2)使用ik_smart分词器
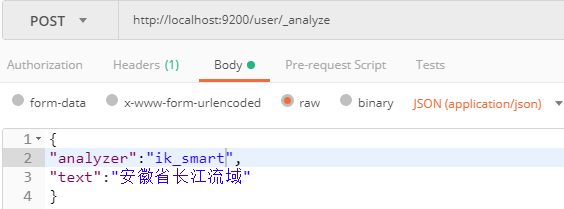
分词结果
(3)使用ik_max_word分词器

1.4 ElasticSearch基本概念
分片:Elasticsearch索引是由一个或多个分片组成的,每个分片包含了文档集的一部分。
副本:分片的副本
区别:生成索引后,分片的数量可以添加删除,而分片的数量无法改变。此时修改分片数量
的唯一途径就是创建另一个索引并重新索引数据。
1.修改索引的自动创建
修改配置文件elasticsearch.yml 设置action.auto_create_index: false
2.类型确定机制
解决方案是在映射定义文件中把
numeric_detection 属性设置为 true ,以开启更积极的文本检测
3.禁用字段猜测类型
要关闭自动添加字段,可以把dynamic属性设置为false
4.Elasticsearch 核心类型
①string:字符串;
②number:数字
③date:日期
④boolean:布尔类型
⑤binary:二进制(二进制字段是存储在索引中的二进制数据的Base64表示,可用来存储以二进制形式正常写入
的数据,例如图像)
5.公共属性
①index_name:定义存储在索引中的字段名称,默认对象名
②index:是否索引,默认(analyzed),设置为no则不索引,字符串可以设置not_analyzed,
则不分析直接编入索引,此时检索时需要全部匹配
③store:是否写入索引,默认为no(如果使用了_source字段,没有编入也可返回该值),设置yes
可用于搜索
④boost:默认值为1,设置权重,值越大,字段中值的重要性页越高
⑤null_value:如果该字段并非索引文档的一部分,此属性指定应写入索引的值
默认的行为是忽略该字段。(这tm怎么理解?)
⑥copy_to :此属性指定一个字段,字段的所有值都将复制到该指定字段
⑦include_in_all:此属性指定该字段是否应包括在 _all 字段中。默认情况下,如果使
用 _all 字段,所有字段都会包括在其中
注意:模糊查询(like)不能使用索引,查询效率低
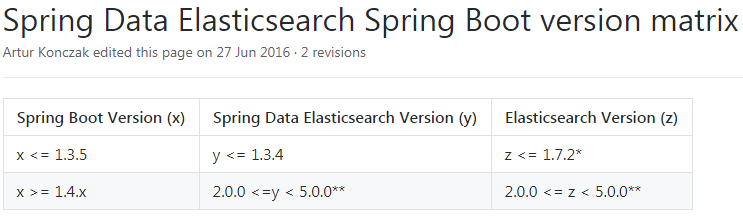
1.5 MySQL和Elasticsearch对比

springboot与elasticsearch版本对应关系
1.6 ElasticSearch集群搭建
ElasticSearch横向扩展能力很强,集群就是单机版的复制,
复制多个elasticsearch,这里配置一主二仆,修改config目录下elasticsearch.yml文件
① slave配置如下:
http.cors.enabled: true http.cors.allow-origin: "*" #master的配置信息: #集群名称,保证唯一 cluster.name: elasticsearch #节点名称,必须不一样 node.name: slave2 #当前节点不作为集群协调者,但存储数据 node.master: false node.data: true #必须为本机的ip地址 network.host: 127.0.0.1 #服务端口号,在同一机器下必须不一样 http.port: 9202 #集群间通信端口号,在同一机器下必须不一样 transport.tcp.port: 9302 #设置集群自动发现机器ip集合 discovery.zen.ping.unicast.hosts: ["127.0.0.1:9300", "127.0.0.1:9301", "127.0.0.1:9302"]
②master配置如下:
http.cors.enabled: true http.cors.allow-origin: "*" #master的配置信息: #集群名称,保证唯一 cluster.name: elasticsearch #节点名称,必须不一样 node.name: master #当前节点作为集群协调者且存储数据 node.master: true node.data: true #必须为本机的ip地址 network.host: 127.0.0.1 #服务端口号,在同一机器下必须不一样 http.port: 9200 #集群间通信端口号,在同一机器下必须不一样 transport.tcp.port: 9300 #设置集群自动发现机器ip集合 discovery.zen.ping.unicast.hosts: ["127.0.0.1:9300", "127.0.0.1:9301", "127.0.0.1:9302"]
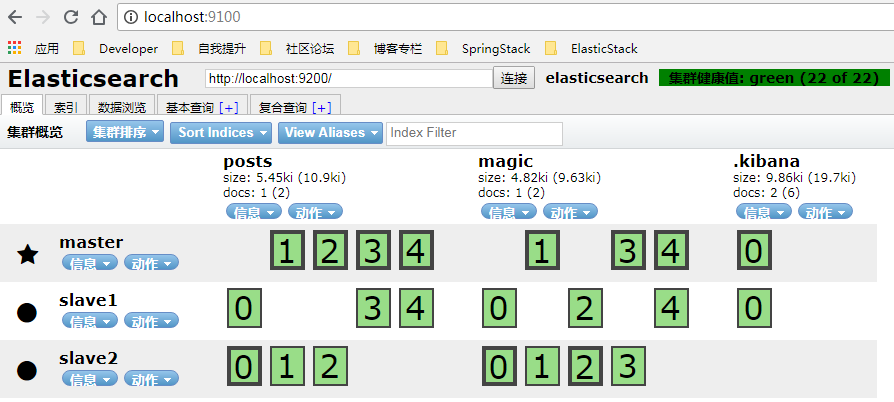
配置完成后,启动三个节点,在head插件下会看到如图所示的效果:
1.7 linux下elasticsearch安装问题
[1]: max file descriptors [4096] for elasticsearch process is too low, increase to at least [65536]
解决:切换到root用户,编辑limits.conf 添加类似如下内容
vi /etc/security/limits.conf
添加如下内容:
* soft nofile 65536 * hard nofile 131072 * soft nproc 2048 * hard nproc 4096
[2]: max virtual memory areas vm.max_map_count [65530] is too low, increase to at least [262144]
解决:切换到root用户修改配置sysctl.conf
vi /etc/sysctl.conf
添加下面配置:
vm.max_map_count=655360
并执行命令:
sysctl –p
[3]: system call filters failed to install; check the logs and fix your configuration or disable system call filters at your own risk
其他错误:
https://blog.csdn.net/qq_33363618/article/details/78882827
2 Elasticsearch查询
2.1 Elasticsearch Restful API
①新增记录
向指定的 /Index/Type 发送 PUT 请求,就可以在 Index 里面新增一条记录
http://localhost:9200/cmbc/employee
{ "first_name": "zkr-yanghuiying", "last_name": "pacbj-yanghuiying", "age": 24, "about": "I love to coding ...", "interests": [ "games" ], "join_time": "2018-03-06" }
注意: /Index/Type后面可以加id,id可以为数字或者字符串,不加会自动生成,此时请求为PUT请求。新增记录的时候,也可以不指定 Id,这时要改成 POST 请求
② 查看记录
向/Index/Type/Id发出 GET 请求,就可以查看这条记录。
③ 删除记录
删除记录就是Delete请求
Delete http://localhost:9200/cmbc/employee
删除文档加Id即可,删除索引则加Index即可
④ 更新记录(有点糊涂,后期再研究)
ES可以使用POST或者PUT进行全部更新,如果指定ID的文档已经存在,则执行更新操作。
注意:es执行更新操作的时候,ES首先将旧的文档标记为删除状态,然后添加新的文档,旧的文档不会立即消失,但是你也无法访问,ES会在你继续添加更多数据的时候在后台清理已经标记为删除状态的文档。
局部更新,可以添加新字段或者更新已有字段(必须使用POST)
http://localhost:9200/cmbc/employee/TuAQIGQBNnQMC6EoMDSM/_update
{ "doc": { "age": 25, "last_name": "zkr-lijunkai" } }
区别: 全部更新,是直接把之前的老数据,标记为删除状态,然后,再添加一条更新的;局域更新,只是修改某个字段。
⑤ 查询
5.1 返回所有记录,使用 GET 方法,直接请求/Index/Type/_search,就会返回所有记录
http://localhost:9200/_search
http://localhost:9200/cmbc/employee/_search
{ "took": 15, "timed_out": false, "_shards": { "total": 5, "successful": 5, "skipped": 0, "failed": 0 }, "hits": { "total": 13, "max_score": 1, "hits": [ { "_index": "cmbc", "_type": "employee", "_id": "dR_7G2QBVx78n1CFS4kg", "_score": 1, "_source": { "first_name": "zkr-liuyang", "last_name": "pacbj-liuyang", "age": 22, "about": "I love to coding ...", "interests": [ "games" ], "join_time": "2018-03-06" } }, { "_index": "cmbc", "_type": "employee", "_id": "eB_8G2QBVx78n1CFVol2", "_score": 1, "_source": { "first_name": "zkr-yanghuiying", "last_name": "pacbj-yanghuiying", "age": 24, "about": "I love to coding ...", "interests": [ "games" ], "join_time": "2018-03-06" } } ] } }
返回结果的 took字段表示该操作的耗时(单位为毫秒),timed_out字段表示是否超时,hits字段表示命中的记录
5.2 Match查询,指定匹配条件
POST http://localhost:9200/cmbc/employee/_search
{ "query": { "match": { "first_name": "zkr-liuyang" } } }
网上的教程使用的是get请求拼json查询条件,但是post请求发送json数据也是可以的。
我们可以通过size字段,指定返回几条结果
"_score": 0.87546873 _score表示得分(匹配程度),查询出来的结果会按照匹配程度的大小倒排。
还可以通过from字段,指定位移。
"from": 1(从位置1开始(默认是从位置0开始))
5.3 查询所有
{ "query": { "match_all": {} } }
ElasticSearch中Filter和Query的异同
如下例子,查找性别是女,所在的州是PA,过滤条件是年龄是39岁,balance大于等于10000的文档:
{ "query": { "bool": { "filter": [ {"term": {"age": "39"}}, {"range": {"balance": {"gte": "10000"}} } ], "must": [ {"match":{"gender": "F"}}, {"match": {"state": "PA"}} ] } } }
2.2 Query与Filter异同:
Query查询上下文:
在查询上下文中,查询会回答这个问题——“这个文档匹不匹配这个查询,它的相关度高么?” ES中索引的数据都会存储一个_score分值,分值越高就代表越匹配。另外关于某个搜索的分值计算还是很复杂的,因此也需要一定的时间。查询上下文 是在 使用query进行查询时的执行环境,比如使用search的时候。
Filter过滤器上下文:
在过滤器上下文中,查询会回答这个问题——“这个文档匹不匹配?”
答案很简单,是或者不是。它不会去计算任何分值,也不会关心返回的排序问题,因此效率会高一点。
过滤上下文 是在使用filter参数时候的执行环境,比如在bool查询中使用Must_not或者filter。另外,经常使用过滤器,ES会自动的缓存过滤器的内容,这对于查询来说,会提高很多性能。
总结
查询上下文中,查询操作不仅仅会进行查询,还会计算分值,用于确定相关度;在过滤器上下文中,查询操作仅判断是否满足查询条件,且查询的结果可以被缓存。
注意:此处JestClient是单例的,在多线程并发访问时注意加锁同步或者使用异步执行jestClient.executeAsync()或者自定义JestClientFactory设置HttpClientConfig的多线程属性为true,从而重新构造JestClient。
2.3 Elasticsearch模糊查询
Elasticsearch模糊查询
GET /_search { "query": { "wildcard" : { "user" : "ki*y" } } }
也可以使用下面这种查询方式
GET /_search { "query": { "wildcard" : { "user" : { "value" : "ki*y", "boost" : 2.0 } } } }
wildcard query应杜绝使用通配符打头,实在不得已要这么做,就一定需要限制用户输入的字符串长度。 最好换一种实现方式,通过在index time做文章,选用合适的分词器,比如nGram tokenizer预处理数据,然后使用更廉价的term query来实现同等的模糊搜索功能。 对于部分输入即提示的应用场景,可以考虑优先使用completion suggester, phrase/term suggeter一类性能更好,模糊程度略差的方式查询,待suggester没有匹配结果的时候,再fall back到更模糊但性能较差的wildcard, regex, fuzzy一类的查询。
2.4 对象嵌套查询(Nested dataype)
参考链接 : https://www.elastic.co/guide/en/elasticsearch/reference/current/nested.html
参考链接 : https://www.elastic.co/guide/cn/elasticsearch/guide/current/nested-query.html
嵌套类型是对象数据类型的专门化版本,它允许对象数组以一种彼此独立查询的方式被索引。
内部对象字段的数组并不像您预期的那样工作。Lucene没有内部对象的概念,因此,ElasticSearch将对象层次结构变平为一个简单的字段名和值列表。例如,下面的文档
PUT my_index/_doc/1
{ "group": "fans", "user": [ { "first": "John", "last": "Smith" }, { "first": "Alice", "last": "White" } ] }
用户字段被动态地添加为一类对象字段
将会在内部被转换成一个更像这样的文档:
{ "group": "fans", "user.first": [ "alice", "john" ], "user.last": [ "smith", "white" ] }
User。User.first,user.last字段被平铺到多值字段中,而alice和white之间的关联丢失了。该文档将错误地匹配alice和smith的查询
如果您需要索引对象数组并维护阵列中每个对象的独立性,您应该使用嵌套数据类型,而不是对象数据类型。在内部,嵌套对象将数组中的每个对象作为单独的隐藏文档进行索引,这意味着每个嵌套的对象都可以独立地查询,并使用嵌套查询:
PUT my_index
{ "mappings": { "_doc": { "properties": { "user": { "type": "nested" } } } } }
PUT my_index/_doc/1
{ "group": "fans", "user": [ { "first": "John", "last": "Smith" }, { "first": "Alice", "last": "White" } ] }
GET my_index/_search
{ "query": { "nested": { "path": "user", "query": { "bool": { "must": [ { "match": { "user.first": "Alice" }}, { "match": { "user.last": "Smith" }} ] } } } } }
GET my_index/_search
{ "query": { "nested": { "path":"user", "query":{ "bool":{ "must":[ {"match":{"user.first":"Alice"}}, {"match":{"user.last":"White"}} ] } }, "inner_hits":{ "highlight":{ "fields":{ "user.first": {} } } } } } }
GET /my_index/blogpost/_search
{ "query": { "bool": { "must": [ {"match": {"title": "eggs" }}, {"nested": { "path": "comments", "query": { "bool": { "must": [ {"match":{"comments.name": "john"}}, {"match": {"comments.age": 28}} ] } } } } ] }}}
未完待续...