DFA
DFA即Deterministic Finite Automaton,也就是确定有穷自动机。在实现文字过滤的算法中,DFA是比较好的实现算法。
具体是什么原理呢?
存在如下几个敏感词:日本人、日本鬼子、毛.泽.东。
首先:query 日 ---> {本}、query 本 --->{人、鬼子}、query 人 --->{null}、query 鬼 ---> {子}。形如下结构:
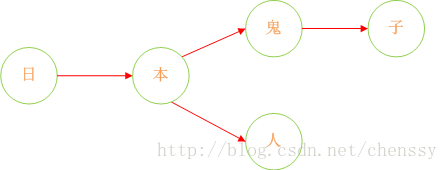
下面我们在对这图进行扩展:
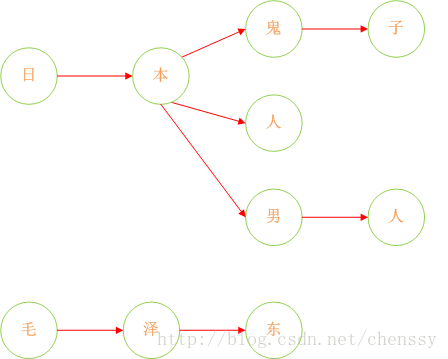
这样我们就将我们的敏感词库构建成了一颗树,这样我们判断一个词是否为敏感词时就大大减少了检索的匹配范围。比如我们要判断日本人,根据第一个字我们就可以确认需要检索的是那棵树,然后再在这棵树中进行检索。
具体实现
将敏感词放入HashSet中,构建一个DFA算法模型,例如:
中 = {
isEnd = 0
国 = {<br>
isEnd = 1
人 = {isEnd = 0
民 = {isEnd = 1}
}
男 = {
isEnd = 0
人 = {
isEnd = 1
}
}
}
}
五 = {
isEnd = 0
星 = {
isEnd = 0
红 = {
isEnd = 0
旗 = {
isEnd = 1
}
}
}
}
isEnd,判断该字是否为该词中的最后一个字。若是表示敏感词结束,设置标志位isEnd = 1,否则设置标志位isEnd = 0。
我们接下来实现一个例子,要求:
- 能够屏蔽单个单词。例如,敏感词“nice”,原文“U are a nice guy”,输出“U are a XXXX guy” ;
- 能够屏蔽多个单词。例如,敏感词“nice”,“sun”,原文“Such a nice day with a bright sun”,输出“Such a XXXX day with a bright XXX”
- 能够替换包含敏感字作为前缀的单词,例如,原文“U are so friendly”,输出“U are so XXXXXXXX”
- 能够替换包含敏感字作为后缀的单词。如上。
- 能够指定将敏感词替换为指定单词。例如,原文“Objection is bad,a better thing to do”,输出“Objection is ungood,a gooder thing to do”
源码在https://github.com/Ivyvivid/algorithm
这里只是简单的实现,性能上可以再优化。里面有一个没想到解决方法,按符号标点split,组装回string时,标点符号消失。希望有人可以解决。