2015年元旦,好好学习,天天向上。良好的开端是成功的一半,任何学习都不能中断,只有坚持才会出结果。继续学习Hadoop。冰冻三尺,非一日之寒!
经过Hadoop的伪分布集群环境的搭建,基本对Hadoop有了一个基础的了解。但是还是有一些理论性的东西需要重复理解,这样才能彻底的记住它们。个人认为重复是记忆之母。精简一下:
NameNode:管理集群,并且记录DataNode文件信息;
SecondaryNameNode:可以做冷备份,对一定范围内的数据作快照性备份;
DataNode:存储数据;
JobTracker:管理任务,并将任务分配给taskTracker;
TaskTracker:任务的执行方。
HDFS现在都知道是Hadoop分布式文件系统,但是关于它的其它方面比如说它的体系结构就不知道了。因此,还得在此基础上理解Hadoop分布式文件系统的体系结构以及相关基本概念。《Hadoop入门学习笔记---part3》的重点内容就是分布式文件系统和HDFS;HDFS的shell操作,NameNode体系结构;DataNode的体系结构。
- 分布式文件系统和HDFS:
DFS(分布式文件系统)是一种允许文件通过网路在多台主机上分享的文件系统。可以让多台机器上的多用户分享文件和存储空间。
HDFS仅仅是DFS中的一种,适用于一次写入多次查询的情况,不支持并发写的情况,同时也不适合于小文件。
下面就可以在已经搭建好的hadoop伪分布环境下进行操作了。首先查看hadoop的进程是否已经启动。如果没有启动,需要启动后再进行下面的操作。
#jps #start-all.sh (如果没有启动)
2. HDFS的shell操作:
实际上HDFS的shell操作和Linux上的操作基本上是类似的。只是列举一些很是常用的命令,给一个抛砖引玉的作用。能够知道是怎么回事,怎么用就行。
#hadoop fs –ls / 查看根目录下的内容 #hadoop fs –lsr / 递归查看根目录下的内容 #hadoop fs –mkdir /hello 在HDFS的根目录下新建一个hello的文件夹 #hadoop fs –put /root/test /hello 将linux中root目录下的test文件上传到HDFS的hello目录下,当只有源路径而没有目标路径时,默认表示文件名称,不是文件夹,为上传后的名称 #hadoop fs –get /hello/test . 将HDFS上的文件下载到本地。注意在命令的最后面是一个点,而这个点就是表示本地路径,即为linux的路径,可以将点改为任何路径 #hadoop fs –text /hello/test 直接在HDFS上查看hello目录下的test文件 #hadoop fs –rm /hello/test 删除hello目录下的test文件,只针对文件 #hadoop fs –rmr /hello 递归地删除HDFS上的hello目录,包含文件和文件夹 **#hadoop fs –help +命令 查看帮助文档 **#hadoop fs –ls / 实际上是命令#hadoop fs –ls hdfs://hadoop:9000/ 是一样的效果,就是简写。注意里面的hadoop是我机器的主机名,应根据你自己的实际来选择
因为这样的命令太多,我就不一一列举了。只要会使用linux命令的,基本上很容易上手。类推就行!
3. NameNode的体系结构:
HDFS的两大核心就是NameNode和DataNode。是整个文件系统的管理节点,维护整个文件系统的文件目录树,文件/目录的元信息和每个文件对应的数据块列表,接收用户的操作请求。本人仅概括性的总结,详细的介绍还请参看官方文档。
文件包括:
(1) fsimage:文件系统镜像,元数据镜像文件,存储某一时段NameNode内存元数据信息;
(2) edits: 操作日志文件,事务文件;
(3) fstime: 保存最近一次checkpoint的时间。
以上这些文件是保存在Linux上。
SecondaryNameNode:
从NameNode上下载元数据信息(fsimage和edits),然后把二者合并,生成新的fsimage,在本地保存,并将其推送到NameNode,同时重置NameNode的edits。实际上就是冷备份。
在linux中的路径如下如下,你可以看到以上介绍的文件。
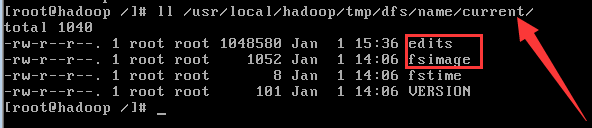
4. DataNode的体系结构:
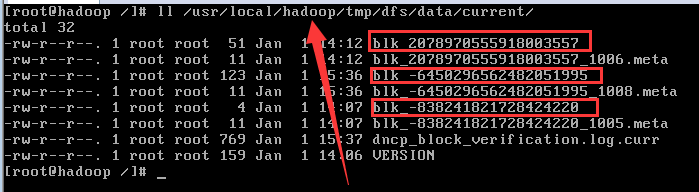
提供真实文件数据的存储服务;还得明白一个关键术语:数据块(block),最基本的存储单位;对于文件内存而言,一个文件的长度大小问size。那么从文件的0偏移开始,按照固定的大小,顺序对文件进行划分并编号,划分好的每一个块称为一个block。
HDFS默认的Block大小是64MB,以一个256MB的文件为例,256MB/64MB=4个Block。
与普通文件系统不同的是,HDFS中,如果文件小于一个数据块的大小,并不占用整个数据块存储空间。即:HDFS的DataNode在存储数据时,如果原始文件大小大于64MB,按照64MB大小划分,如果小于64MB,就按实际大小保存。
Repication:多副本,默认为3个,存放在不同的机器上。
在linux中的实际存储为下图所示。同时可以看到存储数据的元信息。
在《Hadoop入门学习笔记---part4》中将利用java操作HDFS,看看如何利用java实现的应用程序进行操作。
作者:itRed
邮箱:it_red@sina.com
博客:http://www.cnblogs.com/itred 个人网站:http://wangxingyu.jd-app.com
***版权声明:本文版权归作者和博客园共有,欢迎转载,但请在文章显眼位置标明文章出处。未经本人书面同意,将其作为他用,本人保留追究责任的所有权利。