现代处理器的发展历史上,CPU的性能和内存性能差距逐渐拉大,为了解决这一问题,CPU设置了多级缓存结构
其中较为典型的有L1,L2,L3高速缓存
其中L1高速缓存具有和寄存器差不多的速度。
L1,L2,L3缓存都位于芯片内部,这些缓存我们统称为Cache,下述就不再区分了
由于Cache位于CPU内部,意味着对于多个CPU,缓存之对于所在的CPU可见,那么对于每个CPU在处理数据的时候就不免会造成缓存和主存的数据不一致的问题
为了解决这个问题,CPU厂商提出了两种解决方案
1,总线锁定:当某个CPU处理数据时,通过锁定系统总线或者时内存总线,让其他CPU不具备访问内存的访问权限,从而保证了缓存的一致性
2,缓存一致性协议(MESI):缓存一致性协议也叫缓存锁定,缓存一致性协议会阻止两个以上CPU同时修改缓存了相同主存数据的缓存副本
总线锁定开销太大,现代的处理器已经很少采用这种方式保证缓存数据一致性,重点分析一下MESI协议,这对于JMM模型的理解也很有帮助
MESI是四个单词的首字母缩写,Modified修改,Exclusive独占,Shared共享,Invalid无效,下图是一个多CPU协同缓存的图例1.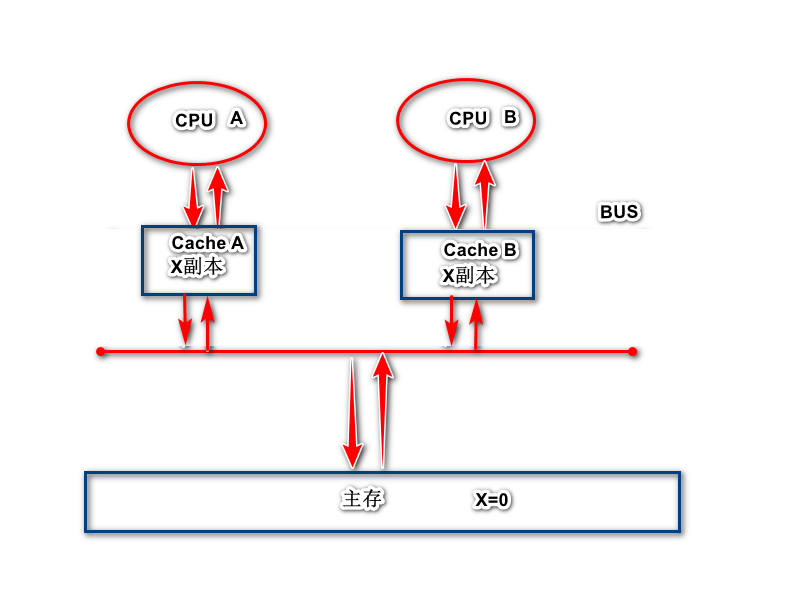
1.当CPU A将主存中的x cache line读入缓存中时,此时X副本的状态为E独占。
2.当CPU B将主存中的X cache line读入缓存中时,AB同时嗅探总线,得知X cache line不止一个副本,此时X的状态变为S共享
3,当CPU A将CACHE A中的x cache line修改为1后,Cache A中的X cache line 的状态变为M修改,并发送消息给CPU B,CPU将X cache line的状态变为I无效
4.当CPU A确认所有CPU缓存中的都提交了I无效状态,将修改后的值刷新到主存中,此时主存中的X变为了1,此时Cache A中的x cache line变为E独享
5.当CPU B需要用到X,发出读取X指令,于是读取主存中的x,于是重复第二步